

MetaがLlama 3の大規模言語モデルのトレーニングを行う中で、NVIDIA H100 GPUの頻繁な故障に悩まされていたことが明らかになった。Metaが最近公開した研究によると、16,384基のNVIDIA H100 80GB GPUで構成されるクラスターを使用した54日間のトレーニング期間中、平均して3時間に1回の割合で予期せぬコンポーネント故障が発生していたという。この驚くべき頻度の故障の半数以上がGPUまたはその搭載メモリに起因するものであった。
GPUは重要であるが信頼性への課題も示唆する結果に
Metaの研究チームは、Llama 3 405Bモデルのトレーニングを54日間にわたって実施した。この期間中、クラスターは合計466回のジョブ中断を経験した。そのうち47回は計画的なメンテナンスによるものだったが、残りの419回は予期せぬ障害によるものだった。これらの予期せぬ中断の内訳を見ると、GPUが関連する問題が最大の要因となっていることが分かる。
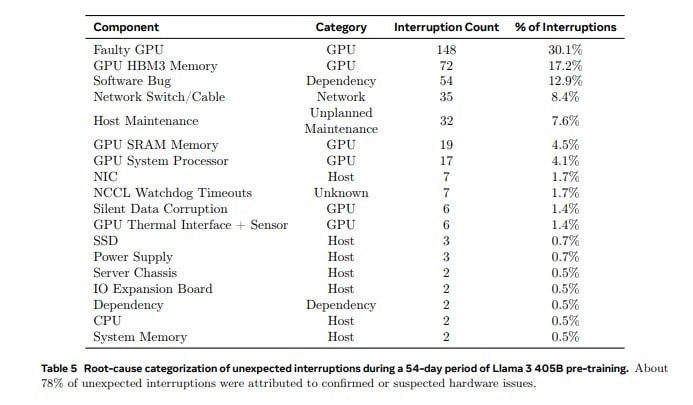
具体的には、予期せぬ中断の58.7%がGPU関連の問題に起因していた。その中でも30.1%が様々なGPU故障(NVLinkの障害を含む)によるもので、17.2%がHBM3メモリの故障によるものだった。NVIDIA H100 GPUは約700Wという極めて高い電力を消費し、それに伴う熱ストレスにさらされることを考えると、これらの故障の頻度は驚くべきことではないかもしれない。
一方で、CPUの故障はわずか2回にとどまっており、GPUの脆弱性が際立つ結果となった。このことは、現代の大規模AIトレーニングにおいて、GPUが重要な役割を果たす一方で、その信頼性に課題があることを示唆している。
GPUの故障だけでなく、環境要因もトレーニングパフォーマンスに無視できない影響を与えていたことが明らかになった。日中の温度変動によって、GPUのスループットに1-2%の変動が生じていたのである。これは、GPUのダイナミック電圧・周波数スケーリングが温度変化の影響を受けたためだと考えられる。
さらに、数万基のGPUの同時電力消費の変動が、データセンターの電力網に大きな負荷をかけていたことも判明した。これらの変動は時に数十メガワットに及び、電力網の限界に迫るものだった。このことは、Metaが今後のAIトレーニングのために、十分な電力供給を確保する必要性を示している。
このような頻繁な障害にもかかわらず、Metaのチームは90%以上という高い実効トレーニング時間を維持することに成功した。これは、彼らが採用した複数の戦略が効果的に機能したからだ。
まず、ジョブの起動時間とチェックポイント作成時間の短縮に取り組んだ。これにより、障害発生時のダウンタイムを最小限に抑えることができた。次に、独自の診断ツールを開発し、問題の迅速な特定と解決を可能にした。
さらに、PyTorchのNCCL Flight Recorderを活用し、特にNCCLXに関連するハングアップやパフォーマンスの問題を診断・解決した。このツールは、集合通信のメタデータやスタックトレースを捕捉し、問題の迅速な解決に貢献した。
また、他のGPUの処理速度を低下させる「ストラグリングGPU」を特定するための専門ツールも開発した。これにより、問題のある通信を優先的に検出し、タイムリーに解決することで、全体のトレーニング効率を維持することができた。
Metaの16,384 GPU規模のクラスターで54日間に419回の故障(24時間あたり7.76回、つまり約3時間に1回)が発生したという事実は、より大規模なAIトレーニングクラスターの信頼性に関する重要な示唆を与えている。
例えば、xAIが保有する100,000基のH100 GPUで構成されるクラスターは、Metaのクラスターの約6倍の規模である。同様の故障率を仮定すると、xAIのクラスターではさらに頻繁な障害が発生する可能性がある。この予測は、大規模AIトレーニングにおける信頼性の確保が今後ますます重要になることを示唆している。
Metaの経験は、大規模AIシステムの運用における複雑な課題を提示する物だ。頻繁な故障にもかかわらず高い実効トレーニング時間を維持できたことは、積極的な故障緩和戦略の重要性を示している。同時に、ハードウェアの信頼性向上、より効率的な冷却システムの開発、そしてより安定した電力供給システムの構築など、ハードウェアとインフラストラクチャの両面での改善の必要性も明らかになった。この研究結果は、大規模AIトレーニングクラスターの信頼性に関する重要な示唆を与えている。例えば、xAIが保有する100,000基のH100 GPUで構成されるクラスターでは、同様の故障率を仮定すると、さらに頻繁な障害が発生する可能性がある。
AIモデルとそのトレーニングクラスターの規模が拡大し続ける中、Metaの経験から得られたこれらの教訓は、AI業界全体にとって極めて重要な指針となるだろう。今後、ハードウェアメーカー、データセンター設計者、そしてAI研究者たちが協力して、これらの課題に取り組むことが、次世代のAIシステムの発展に不可欠となると見られる。
Sources






コメント