

AMDの次世代CPUアーキテクチャ「Zen 5」は、いくつかのベンチマークテスト結果が示すように、驚異的な進化を見せるものだ。この新アーキテクチャの中核を成すのは、30年前の学術研究に端を発する「2-Ahead Branch Predictor」という画期的な分岐予測技術である。Chips and Cheeseは、この革新的なZen 5アーキテクチャについて、より深く掘り下げた記事で解説してくれているので、ここでご紹介しよう。
Zen 5アーキテクチャの革新:分岐予測の進化と性能向上の鍵
AMDのChief Technology OfficerであるMark Papermaster氏が「Zen 5はZenアーキテクチャの根本的な再設計です」と述べているように、これまでのZenアーキテクチャとは大きく異なるものだ。
現代のマイクロプロセッサにおいて、分岐予測は極めて重要な役割を果たしている。プログラムの実行中、条件分岐や繰り返し、サブルーチンなどによって、プログラムの実行ポイントが頻繁に変更される。高性能を維持するためには、これらの分岐をできるだけ正確に予測し、パイプラインを効率的に維持する必要がある。
Zen 5の2-Ahead Branch Predictorは、この課題に新たなアプローチで取り組んでいる。この技術は、1サイクルあたり2つの分岐を処理できる能力を持ち、非連続な命令ブロックにまたがる2つの分岐を同時に処理することを可能にした。さらに、Zen 5は3つの予測ウィンドウを持ち、2番目の分岐を超えて命令ストリームをより先まで見通すことができる。これにより、プロセッサは将来の分岐をより正確に予測し、パイプラインの効率を大幅に向上させることが可能になった。
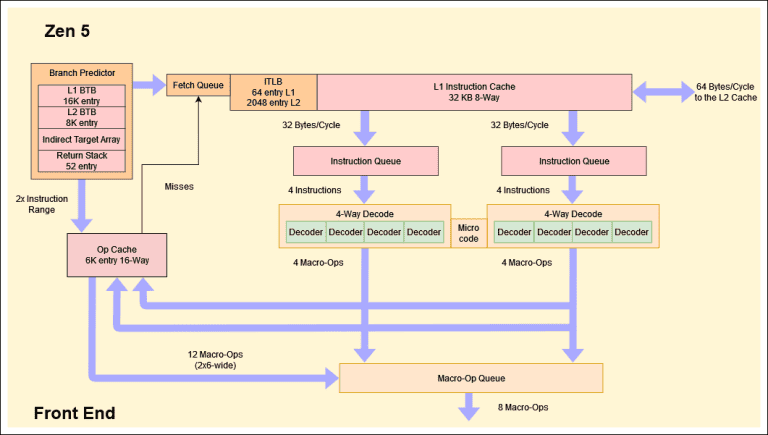
この先進的な分岐予測技術を最大限に活用するため、AMDはZen 5アーキテクチャにおいて、命令フェッチとオペレーションキャッシュ(Op Cache)のデュアルポート化を実現した。具体的には、32KBのL1命令キャッシュから2つの32バイト/サイクルのフェッチパイプを設け、それぞれが4ワイドのデコードクラスタに接続されている。これにより、命令フェッチの並列性が大幅に向上し、プロセッサの処理速度を加速させている。
さらに、Op Cacheは6ワイドのデュアルポート設計となり、最大12個のオペランドをOp Queueに供給できるようになった。これは、命令デコードの効率を飛躍的に高め、プロセッサが1サイクルあたりにデコードできる命令数を増加させている。
Branch Target Buffer(BTB)もデュアルポート化され、L1 BTBは16Kエントリという大容量を持つようになった。これは、より多くの分岐履歴を保持し、予測精度を向上させるのに役立っている。L2 BTBは8Kエントリとやや小さいものの、L1 BTBから追い出されたされたエントリを保持する役割を果たし、二次的な予測支援を提供している。
これらの改良により、Zen 5は分岐が発生した際のフェッチ帯域幅の低下を大幅に抑制し、より効率的な命令実行を実現している。特に、x86アーキテクチャの可変長命令という特性を巧みに活用し、命令境界の決定という本質的に並列化が難しい処理を効率的に行うことに成功している。
Zen 5の2-Ahead Branch Predictorは、単に30年前のアイデアを実装しただけではない。現代のプロセッサ設計の要求に合わせて最適化され、半導体技術の進歩と密接に関連付けられている。トランジスタ密度の向上や、マルチコアからハンドレッドコアへの進化など、半導体製造技術の発展がこの革新的な技術の実現を可能にした。
さらに、この技術はx86アーキテクチャの特性を巧みに活用している。x86の可変長命令セットは、命令デコードの並列化を困難にする要因であったが、2-Ahead Branch Predictorはこの課題を克服し、むしろx86の特性を利点に変えている。具体的には、分岐予測の精度向上により、命令境界の決定を効率的に行い、デコードの並列性を高めることに成功している。
AMDの次世代アーキテクチャZen 5は、過去の革新的アイデアを現代の技術で実現し、プロセッサの性能向上に新たな可能性を開いた。この技術は、今後のZenファミリーの発展に重要な役割を果たすことが期待される一方で、高度な分岐予測能力は、より複雑化するソフトウェアやAIワークロードに対応する上で、重要な要素となることも間違いない。
Zen 5の導入は、単にAMDの製品ラインナップを強化するだけでなく、コンピューティング産業全体に影響を与える可能性がある。高精度の分岐予測は、エネルギー効率の向上にも寄与し、データセンターや高性能コンピューティング分野での電力消費削減にも貢献する可能性があるからだ。さらに、この技術の進化は、機械学習やAI処理の高速化にも寄与し、新たなアプリケーションの開発や既存のソフトウェアの性能向上を促進する可能性がある。
Source







コメント