これまで「安全性」と「プライバシー保護」を旗印に、競合他社との差別化を図ってきたAI研究企業Anthropicが、その根幹を揺るがす大きな方針転換を発表した。2025年8月28日、同社はAIアシスタント「Claude」の無料および有料の個人ユーザーに対し、彼らの会話データをモデルの学習に利用する新方針を公開。ユーザーは同年9月28日までに、自らの意思でデータ提供を拒否する「オプトアウト」を選択しない限り、会話履歴が最大5年間にわたって保持され、次世代モデルの訓練に使用されることになる。
この動きは、AI開発の最前線で起きている構造的な変化が表出したものであり、我々ユーザーが享受するAIの利便性と、その対価として差し出すプライバシーとの関係を根本から問い直すものだ。なぜAnthropicはこのタイミングで方針を転換したのか? UIに隠された巧妙な仕掛けとは? そして、この潮流は我々のデジタルライフにどのような影響を与えるのだろうか。
何が変わるのか? 新方針の要点を5分で理解
今回の変更は複雑に見えるが、核心はシンプルだ。まずは、あなたに直接関係する変更点を箇条書きで明確に整理しよう。
- 対象者: 個人向けの「Claude Free」(無料版)、「Claude Pro」(月額20ドル)、「Claude Max」(月額100ドル)の全ユーザー。コーディング支援ツール「Claude Code」の利用者も含まれる。
- 変更内容: あなたとClaudeとの会話(プロンプトとAIの応答)が、将来のClaudeモデルの性能向上や安全性強化のための学習データとして利用されるようになる。
- 方式: オプトアウト方式。つまり、初期設定(デフォルト)ではあなたのデータは「利用される」状態になっている。利用を拒否したい場合は、ユーザー自身が設定画面で明確に「オフ」にする必要がある。
- 期限: 既存ユーザーは2025年9月28日までに、データ利用を許可するか否かの選択を迫られる。この日を過ぎると、選択を行うまでClaudeの利用が継続できなくなる可能性がある。
- データ保持期間の変更: モデル学習へのデータ提供を許可(オプトイン)した場合、会話データの保持期間が従来の30日から最大5年へと大幅に延長される。提供を拒否(オプトアウト)した場合は、従来通り30日で保持期間は終了する。
- 対象外: 企業向けの「Claude for Work」、政府向けの「Claude Gov」、教育機関向けの「Claude for Education」、そしてAmazon BedrockやGoogle Cloud Vertex AI経由でのAPI利用者は、今回の変更の対象外。彼らのデータが学習に使われることはない。
要するに、Anthropicは個人ユーザーの膨大な会話データを、自社のAIモデルを強化するための「燃料」として活用する決断を下したのだ。月額100ドルを支払う最上位プランのユーザーでさえ、このデータ収集の対象となる点は特に注目に値する。
Anthropicの「公式説明」とその裏にある戦略的意図
Anthropicは公式ブログで、今回の変更の目的を「より高性能で、有用なAIモデルを提供するため」そして「有害な利用に対する我々の安全対策を強化するため」と説明している。ユーザーがデータを提供することで、有害コンテンツ検出システムの精度が上がり、無害な会話を誤ってフラグ立てする可能性が減る。さらに、コーディング、分析、推論といったスキルが向上し、結果的に全ユーザーの利益に繋がる、というのが彼らの主張だ。
この説明は、一見すると合理的で、ユーザーとの協調を謳うポジティブなものに聞こえる。しかし、その言葉の裏にはより切実で戦略的な動機が透けて見える。
競争という名の渇き:高品質な「生データ」への渇望
最大の動機は、疑いようもなく、OpenAIやGoogleといった巨人との熾烈な開発競争だ。現代のAI開発競争において、高品質な学習データは石油以上の価値を持つ戦略資源である。インターネットから収集した静的なテキストデータだけでは、もはやモデル性能の飛躍的な向上は望めない。AIが本当に賢くなるためには、人間が実際にどのようにAIを使い、何を求め、どのように対話し、どこで失敗するのかという、生々しい「実世界のデータ」が不可欠なのだ。
Anthropicはこれまで、プライバシーを重視する姿勢を貫くことで、ユーザーの信頼を獲得してきた。しかし、競合がユーザーデータを活用して日々モデルを改良していく中で、その「高潔さ」が開発速度の足枷になりかねないというジレンマに直面したのだろう。今回の決定は、プライバシーという理念よりも、競争に勝ち抜くための実利を選んだ、苦渋の、しかし必然の戦略転換と言える。
安全性とプライバシーのトレードオフ
Anthropicは「安全性向上」を大きな理由に掲げている。確かに、多様なユーザーとの対話データは、AIが悪用されるパターンを学習し、より堅牢なセーフガードを構築する上で有効だ。しかし、これは「安全性を高めるために、あなたのプライバシーを差し出してください」という、ユーザーに対する究極のトレードオフの提示に他ならない。The Registerが報じているように、有害コンテンツが検出された場合、データは最大7年間保持される可能性さえある。安全性という大義名分が、より長期かつ広範なデータ収集を正当化するロジックとして機能している側面は否定できない。
「同意」は本当にあなたの意思か? UIに隠された巧妙な仕掛け
今回の変更で最も議論を呼んでいるのが、ユーザーに意思決定を促す通知画面のユーザーインターフェース(UI)デザインだ。既存ユーザーに表示されるポップアップは、「利用規約とプライバシーポリシーの更新」という大きな見出しの下に、目立つように「承認」ボタンが配置されている。
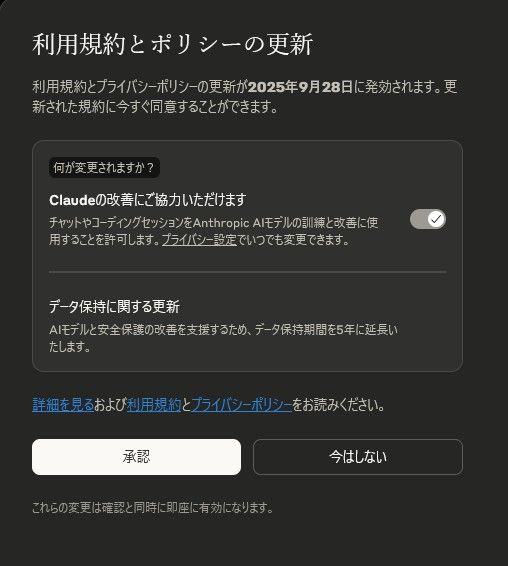
問題は、AI学習へのデータ提供を制御するトグルスイッチだ。それは「承認」ボタンよりもずっと小さく、目立たないデザインで、しかもデフォルトで「オン」の状態になっている。このデザインはユーザーの注意を逸らし、内容をよく確認しないまま「承認」ボタンを押させてしまう「ダークパターン」であると言えるだろう。
多くのユーザーは、煩わしいポップアップを早く消したい一心で、無意識に最も目立つボタンをクリックしてしまう傾向がある。Anthropicのこのデザインは、ユーザーから積極的な「同意」を取り付けるというよりは、ユーザーの「不注意」や「無関心」に乗じて、なし崩し的に同意を得ようとする意図があると見られても仕方がない。
加えて、文言も「Claudeの改善にご協力いただけます」と、ユーザーの善意に訴える物になっている。チャット履歴が利用されることは小さく付記されているに過ぎない。
これは、AIの複雑性が「意味のあるユーザー同意」をいかに困難にしているかを示す象徴的な事例だ。米国連邦取引委員会(FTC)は過去に、AI企業が「密かに利用規約を変更したり、難解な法律用語や小さな文字で開示内容を隠したりする」行為に対して警告を発している。AnthropicのUIがこの警告に抵触するかどうかは議論の余地があるが、ユーザーの真の理解と同意を尊重する姿勢とは言い難いだろう。
個人と企業で異なる「プライバシーの階層」- 鮮明になる二重基準
今回の発表で最も明確になったことの一つが、AI業界における「プライバシーの二重基準(ダブルスタンダード)」だ。
- 個人ユーザー(無料・有料問わず): あなたのデータは、AIを賢くするための貴重な「資源」と見なされる。
- 企業・政府・教育機関の顧客: 彼らのデータは、厳格に保護されるべき「機密情報」として扱われる。
なぜこのような差が生まれるのか。理由は明快だ。企業顧客は、自社の機密情報や顧客データがAIの学習に使われることを断じて許容しない。情報漏洩は事業の存続に関わる致命的なリスクであり、彼らはその保護を契約の絶対条件として要求し、その対価として高額なライセンス料を支払う。Anthropicが政府との大型契約を視野に入れているとすれば、政府データの保護はなおさら不可侵の領域となる。
一方で、個人ユーザーは企業ほどの交渉力を持たない。結果として、個人ユーザーのデータは、AI企業にとって最も手軽で安価な高品質データソースとなる。こうして、支払う金額や立場によって提供されるプライバシー保護のレベルが異なる「プライバシーの階層構造」が、業界の事実上の標準として定着しつつあるのだ。
一社だけの問題ではない。AI業界全体に広がる「データ収集」の潮流
Anthropicの今回の動きを孤立した事象として捉えるのは誤りだ。これは、AI業界全体を覆う大きな潮流の一部である。
Googleは自社のプライバシーポリシーで、Bard(現Gemini)などの公開サービスから得た情報をモデル学習に利用する権利を留保している。Metaも同様に、ユーザーの投稿などをAI学習に活用している。そして今、これまで一線を画してきたAnthropicも、このオプトアウト方式のデータ収集モデルに合流した。
この背景には、AIモデルの性能向上が徐々に頭打ちになりつつあるという現実がある。性能をもう一段階引き上げるためには、データの「量」だけでなく、実世界の文脈を反映したデータの「質」が決定的に重要になる。その最も豊かな源泉が、何百万人ものユーザーとの日々の対話なのだ。
同時に、AI企業は法的な逆風にも晒されている。OpenAIは、ニューヨーク・タイムズ紙などから著作権侵害で提訴された裁判において、ユーザーが削除したものも含め、全てのChatGPTの会話を無期限に保持するよう裁判所から命じられている。このような法的要請も、企業がデータ保持期間を延長する一因となっている可能性がある。
あなたはどうすべきか? 9月28日までに取るべき具体的なアクション
この大きな変化の波の中で、我々ユーザーは傍観者でいることはできない。自らのデータを守るために、主体的な行動が求められる。
ステップ1: 意思決定を行う
まず、あなた自身の価値観に基づいて、データを提供するか否かを決めよう。
- 提供する(オプトイン)メリット: AI技術の発展に貢献できる。Claudeの性能や安全性が向上し、将来的にはその恩恵を受けられるかもしれない。
- 提供しない(オプトアウト)デメリット/メリット: あなたのプライバシーは守られる。個人的な会話や機密情報が、意図しない形で学習データに含まれるリスクを回避できる。一方で、技術の発展への貢献度は低くなる。
ステップ2: 設定を変更する(オプトアウトする場合)
もしデータを提供しないと決めたなら、以下の手順で設定を変更する必要がある。
- ClaudeのWebサイトまたはアプリにログインする。
- アカウント設定やプロフィール画面に移動する。
- 「プライバシー設定」を探す。
- 「Claudeの改善にご協力ください」という選択肢を見つけ、そのトグルスイッチを「オフ」にする。
注意すべき点:
- 期限: この選択は、2025年9月28日までに行う必要がある。
- 過去のデータ: Anthropicによれば、一度データ提供を許可した後に設定をオフにした場合、それ以降の新しい会話は学習に使われなくなる。しかし、設定をオフにする前に提供されたデータは、既に開始された学習や訓練済みのモデルに含まれ続ける可能性がある。
- 会話の削除: 学習に使われたくない特定の会話がある場合、その会話を手動で削除すれば、将来のモデル学習には含まれないとされている。
利便性の代償としてのプライバシー – 我々が立つ岐路
Anthropicの今回の方針転換は、AI時代における利便性とプライバシーの根源的なトレードオフを、我々一人ひとりに突きつける象徴的な出来事だ。我々は、より賢く、より安全なAIアシスタントを手に入れるために、自らの思考の断片とも言える会話データをどこまで差し出す覚悟があるのか。
これは、もはや「善か悪か」で割り切れる単純な問題ではない。AI技術が社会のインフラとなる過程で、テクノロジーと社会、そして個人の関係性を再定義していく、長く困難なプロセスの始まりなのだ。
ユーザーとしては、まず自らの権利と選択肢を正確に理解し、主体的に行動することが第一歩となる。そして長期的には、より透明性が高く、ユーザーが自身のデータをより細かくコントロールできる技術(連合学習や差分プライバシーなど)や、そうした選択肢を提供するサービスを支持していく姿勢が、健全なAIエコシステムの発展に繋がるだろう。
9月28日という期限は、我々が自らのデジタルな人格の一部をどう扱うかを決断する、重要な岐路なのだ。
Sources
- Anthropic: Updates to Consumer Terms and Privacy Policy