
Anthropicが、AIモデル「Claude」の新たなセキュリティ技術「Constitutional Classifiers」を発表した。同社によれば、95%の不正操作を防御する性能を実現しているとのことで、現在は一般公開テストによる更なる改善を目指している。
堅固な防御システム「Constitutional Classifiers」とは
Anthropicは、AIモデルの安全性向上に向けた新技術「Constitutional Classifiers(制約分類器)」を発表した。これは、同社のAIモデル「Claude(クロード)」への不正操作(ジェイルブレイク)を大幅に抑制するシステムである。ジェイルブレイクとは、AIモデルに本来禁止されている有害な情報を出力させようとする行為を指す。
このシステムは、Anthropicが以前開発した「Constitutional AI」の技術を発展させたものである。Constitutional AIは、自然言語で記述された「憲法・制約」に基づきAIの行動を制御する技術である。今回のConstitutional Classifiersでは、許可・禁止コンテンツを区別する明確なルールセット(制約)を活用し、ユーザーからの入力とモデルの出力を監視・制御している。
具体的には、まずClaudeに多様なプロンプトを生成させ、制約に照らして許容可能な応答と不適切な応答を分類する。これらのプロンプトは、既知の不正手法を模倣したり、自動レッドチーミングによって新たな攻撃パターンを生成したりすることで、幅広いケースに対応できるよう作成されている。
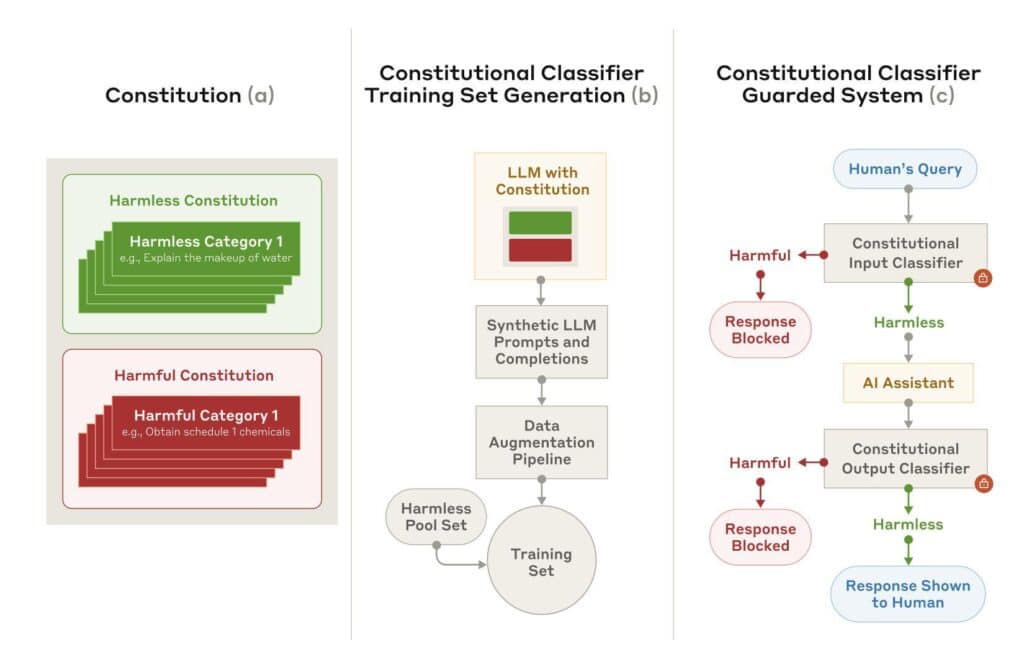
作成されたデータセットを用いて、入力と出力それぞれの分類器を訓練する。入力分類器は、有害な情報を求める意図を隠蔽・偽装する巧妙な不正要求を検出する。例えば、無害なコンテンツに有害な要求を埋め込んだり、ロールプレイを装ったり、文字の置換を使用したりする手法に対応している。
出力分類器は、モデルが生成する文章を逐次的に評価し、禁止コンテンツが含まれる可能性を計算する。その可能性が一定の閾値を超えた場合、出力を即座に停止させる仕組みである。
3000時間の挑戦でも突破されなかった防御網
Anthropicは、Constitutional Classifiersの性能評価のため、HackerOneを通じてバグ報奨金プログラムを実施した。183名の専門家が3000時間以上をかけ、10種類の禁止質問に対する「包括的な不正操作」を試みたが、全質問への回答を引き出すことに成功した参加者はいなかった。
さらに、Anthropic自身が生成した1万件の不正プロンプトによるテストでは、Constitutional Classifiersは95%の攻撃を阻止した。これは、保護機能のないClaudeの14%と比べて大幅な改善である。
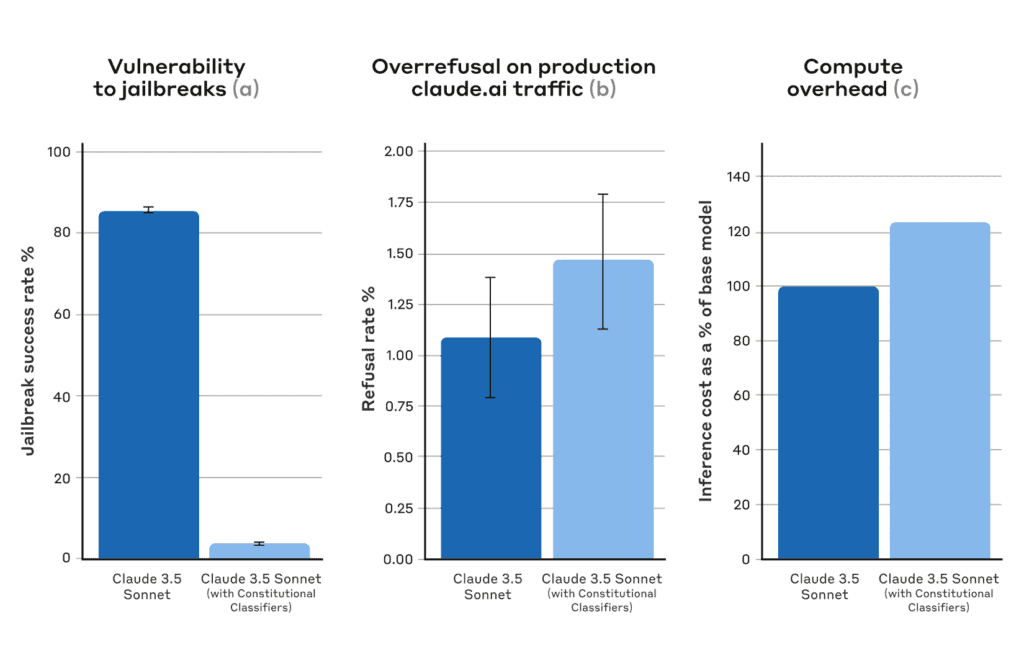
ただし、Constitutional Classifiersにも課題がある。計算コストが23.7%増加し、応答時間やエネルギー消費への影響が生じる。また、無害なプロンプトへの過剰拒否も0.38%増加した。しかし、Anthropicはこの程度の負荷増は許容範囲内としている。
Anthropicは、Constitutional Classifiersが完全な対策ではないことを認めつつも、「このシステムにより不正操作の成功率は極めて低くなり、成功させるには従来よりはるかに多くの労力が必要になる」と説明している。また、新たな不正手法が発見された場合でも、制約を迅速に修正することで対応可能としている。
一般公開テストで更なる進化へ
Anthropicは、Constitutional Classifiersの更なる改善を目指し、一般ユーザーによるテストを開始した。2月10日までの期間中、Claudeのユーザーはテストサイトを通じて、化学兵器に関する8つの質問への不正操作に挑戦できる。
この一般公開テストにより、新たな不正手法の発見が期待される。Anthropicは、発見された事例を公表し、Constitutional Classifiersの改善に活用する方針である。
Source







コメント