

Armは、Armv9 CPUポートフォリオの最新製品として、これまでコードネーム“Black Hawk”と呼ばれていた“究極のパフォーマンス”プロセッサである「Cortex-X925」を発表した。これは、QualcommのSnapdragon 8 Gen 3やMediaTekのDimensity 9300に搭載されているCortex-X4の直接の後継となり、今後のハイエンドスマートフォン向けに搭載される事になる。
Arm Cortex-X925:シングルスレッドIPCの大きな飛躍
新しいCortex-X925は、DSU-120、インターコネクトサブシステム、およびImmortalis GPUで構成されている、2024年のクライアントコンピュートサブシステム(2024 CSS)の一部だ。新しいCortex-X925およびCortex-A725、リフレッシュされたCortex-A520はすべてArmの3nmプロセスノードに移行し、第2世代のArmv9.2アーキテクチャにシームレスに統合されている。Armv9.1ではGEMMとBFloat16のサポートが追加され、Armv9.2ではSME(SVE2)のサポートが追加されている。
Cortex-X925および他のCortex-Xシリーズは、標準的な大きいコアと小さいコアとは異なり、その非準拠性が興味深い。Armはここで、パフォーマンス、消費電力、および面積のトレードオフをより緩和し、パフォーマンスに有利になるようにしている。
| Cortex-X925 | Cortex-X4 | Cortex-X3 | Cortex-X2 | |
|---|---|---|---|---|
| ピーククロックスピード | 約3.6GHz | 約3.4GHz | 約3.25GHz | 約3.0GHz |
| デコード幅 | 10命令 | 10命令 | 6命令 (8 mop) | 5命令 |
| ディスパッチパイプライン深度 | 10サイクル | 10サイクル | 11サイクル (命令用) (mop用は9サイクル) | 10サイクル |
| OoO実行ウィンドウ | 1,500 (2x 750) | 768 (2x 384) | 640 (2x 320) | 448 (2x 288) |
| 実行ユニット | (想定) 6x ALU (一部は2サイクル) 2x ALU/MAC 2x ALU/MAC/DIV 3x Branch | 6x ALU 1x ALU/MAC 1x ALU/MAC/DIV 3x Branch | 4x ALU 1x ALU/MUL 1x ALU/MAC/DIV 2x Branch | 2x ALU 1x ALU/MAC 1x ALU/MAC/DIV 2x Branch |
| アーキテクチャ | ARMv9.2 | ARMv9.2 | ARMv9 | ARMv9 |
アーキテクチャの面では、Armはいくつかのかなり大きな変更を加えている。
メモリの改良
新しいCortex-X925の改良の大部分は、メモリ(直接および間接的に)に関連している。以前の世代と同様に、Cortex-X925は、使用される前に正しい命令ストリームを見つけるために命令フェッチを超えて実行するランアヘッド分岐予測器を持っている。Cortex-X925では、分岐予測器の命令ウィンドウサイズを2倍にし、条件付き分岐の帯域幅を増加させている。また、精度の向上も世代ごとに見られる。ISO構成では、Cortex-X925はキロ命令あたりの予測ミス(MPKI)が低くなると言われている。
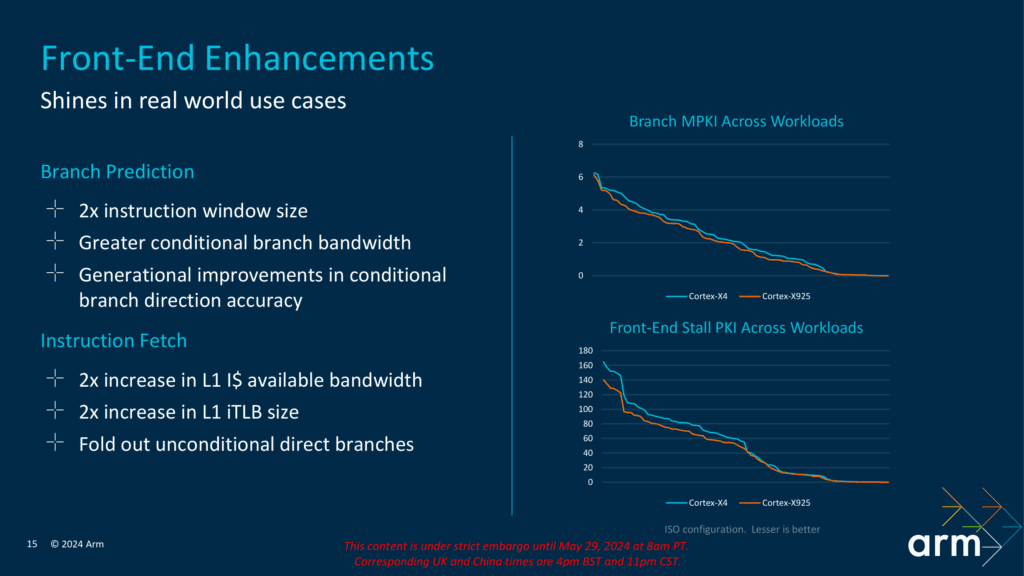
コア自体のフィードも大幅に改善された。これにより、Cortex-X925は前世代と比較してL1命令キャッシュ(I$)の帯域幅も2倍に拡大され、L1命令変換ルックサイドバッファ(iTLB)のサイズも同様に拡大されている。これは特にキャッシュのバンキングの追加に関連しており、理論的にはより高い有効帯域幅の提供が可能になる。これにより、バックエンドのベクトルパイプラインの数の増加と並行して帯域幅が増加している。また、X925は現在、最大3 MiBのプライベートL2キャッシュ容量を提供しており、前世代の1.5倍の容量であることも注目に値する。
実行面では、合計4つのロード実行ユニットが追加された。これは、過去数世代にわたってメモリサブシステムがいくつかの再バランス試みを経て、一般的なAGUの数が減少し、ロードAGUの数が増加した後に再び以前の構成に戻されたことを示している。複雑なパイプラインをすべての既存のワークロードに対してバランスさせることが非常に難しいことを再認識させるものである。合計で、新しいCortex-X925は64B/サイクル(4x16Bレート)をサポートしている。さらに、Cortex-X925には、ストアからロードへのフォワーディングの改良など、LSUに追加のアーキテクチャ改良が施されている。
バックエンド
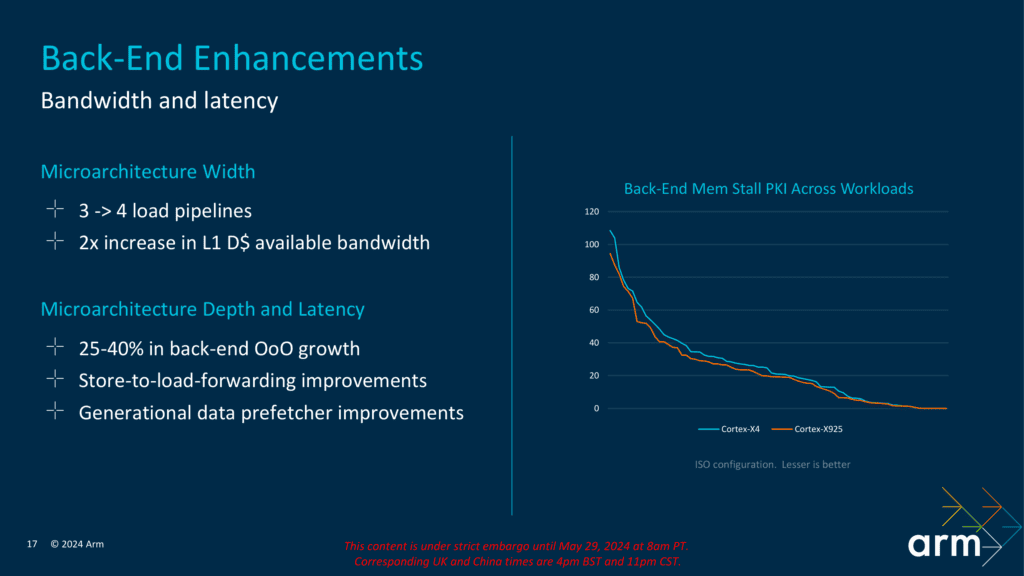
Cortex-X925のアウトオブオーダーウィンドウは非常に大きく、前世代の2倍である。つまり、Cortex-X925は768のフライト中の命令(または1,536の融合操作)のブックキーピング容量を持っている。Armによると、コアパイプラインの幅はほぼ同じであるが、X925は前世代の制約の除去により、より高い有効利用率を示すという。言い換えれば、理論上のピーク命令ストリームのスループットはX4と同じであるが、パイプラインのアーキテクチャ変更により、新しいX925の実際のピーク命令ストリームは高くなるとされている。
AIおよびベクトルアプリケーションを直接ターゲットにして、X925には新しい高度なSIMDパイプが2つ追加され、合計で6つの128ビットパイプとなった。さらに、整数ALUパイプは、より複雑な2サイクル操作に対応するようになっている。

全体的に見て、バックエンドバッファの多くは全体で25%から40%成長したと言われている。全体として、Armはさまざまなアプリケーションにわたってフロントエンドのフェッチストールやバックエンドのメモリストールが改善されたとしている。
パフォーマンス

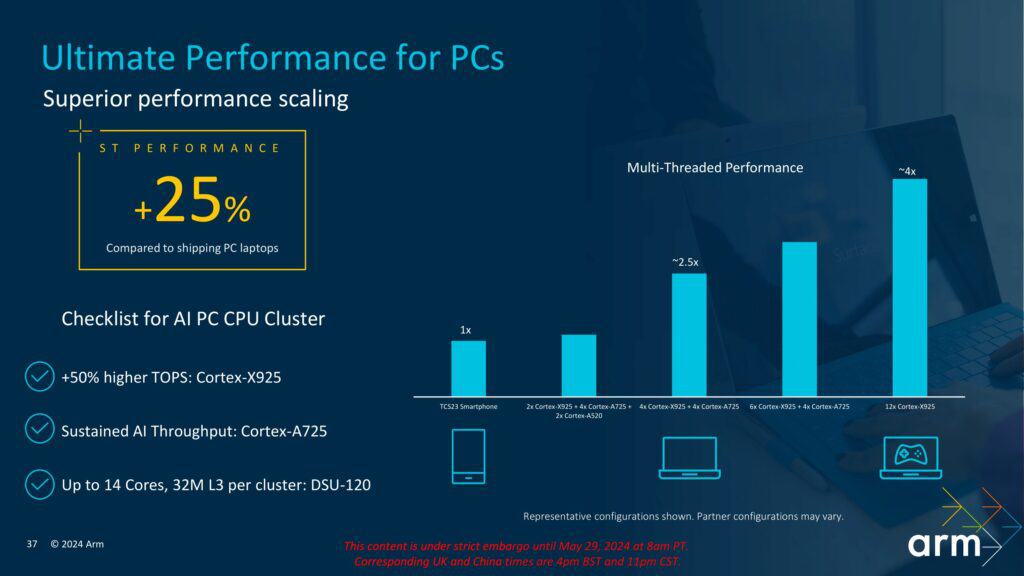
Armによれば、新しいCortex-X925はCortex-Xシリーズの歴史上、最高のパフォーマンス向上をもたらすという。Armが提示したIPCに関するグラフの1つが以下に示されている。グラフはわかりにくいが、実際の数値は非常に堅実である。標準的な2023年のプレミアムクラスのAndroidデバイスと比較して、3.8 GHzでクロックされたCortex-X925は約36%の性能向上をもたらす。ISO周波数では、Cortex-X925は約17%のIPC向上を提供するとされている。完全に最適化されたシステムとソフトウェアスタックおよび最良のケースシナリオでは、ICPは約25%向上するようだ。
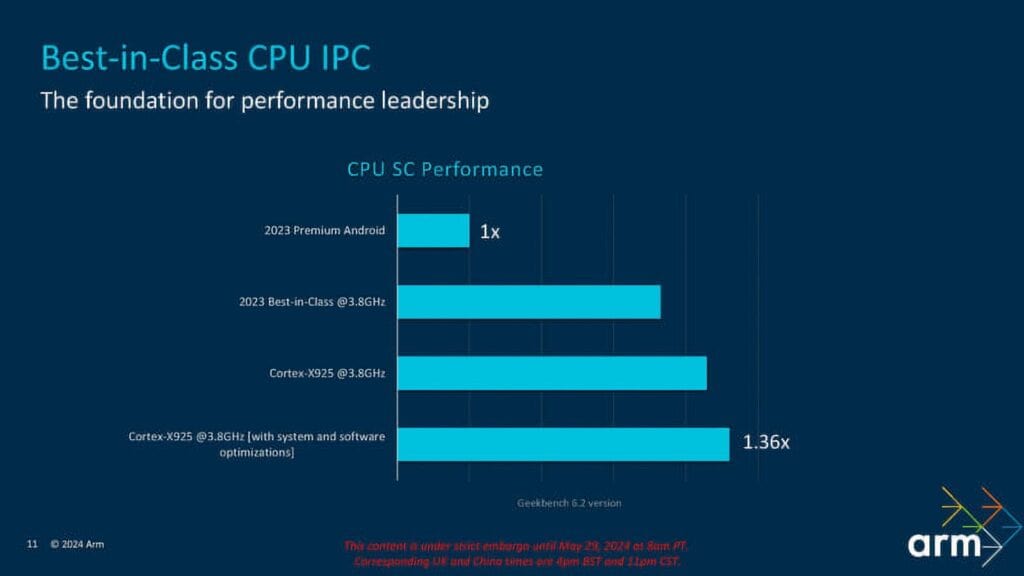
Speedometer2やGeekbench 6などのモバイル業界のベンチマークのいくつかでは、ISO周波数およびISOメモリで、新しいCortex-X925は前のCortex-X4と比較して約15%のIPC向上を提供するとArmは主張している。また、AIベースのワークロード向けに設計・最適化されており、AI処理効率を高める専用のAIアクセラレータとソフトウェア最適化を備えている。このコアは、最大80 TOPS(1秒間に1兆回の演算)で、自然言語処理からコンピュータビジョンまで、複雑なAIタスクを処理できる。これらの機能は、高度なAIアプリケーションの構築に必要なツールを開発者に提供するArmのKleidi AIおよびKleidi CVライブラリによってさらにサポートされる。
ちなみに、ArmはNPUやAIアクセラレーターの領域には進出していない。その代わりに、MediaTekのようなパートナーが独自のNPU等を組み込むことを許可し、Core Clusterが必要なサポートと統合機能を提供できるようにしている。リファレンス・ソフトウェア・スタックと最適化されたライブラリにより、CSSプラットフォームは開発者に堅牢な基盤を提供する。包括的なArm Performance Studioは、開発者が新しいアーキテクチャ向けにアプリケーションを最適化するのに役立つ高度なツール環境を提供する。
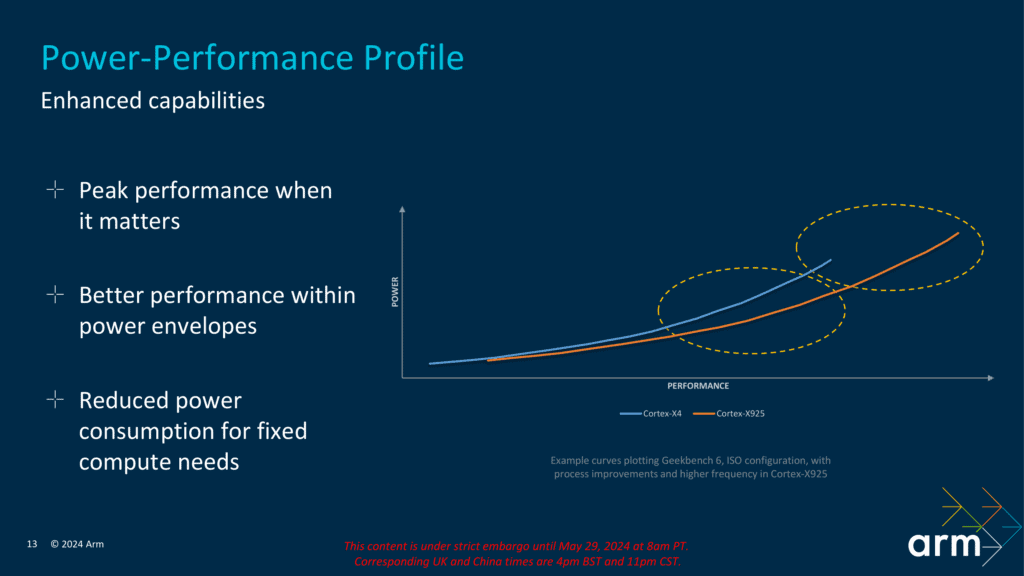
またCortex-X925は3nmのプロセスノードをターゲットにしており、そのノードに最適化されているため、ISOパフォーマンスでは新しいCortex-X925ははるかに高い効率(つまり、低消費電力)で動作するとのことだ。加えて、Cortex-X925には、コアごとのDVFSや電圧レギュレーションの改善など、高度な電力管理機能も組み込まれている。これらの機能は、消費電力をより効果的に管理するのに役立ち、エネルギー効率を損なうことなくコアが高性能を発揮できるようにしている。このバランスは、持続的な性能と長いバッテリ寿命を必要とするモバイル機器にとって特に有益だ。
新しいArm Cortex-X925は、今年の終わりまでに主要なプレミアムモバイル製品に搭載される予定だ。
Sources








コメント