

AIスーパーコンピューター企業Cerebras Systemsは、最大24兆個のパラメータ・サイズのニューラルネットワーク・モデルをトレーニングすることが可能な90万個のAI最適化コアを提供する、第3世代のウェハースケール・エンジン・チップ「WSE-3」を発表した。
Cerebrasによると、WSE-3には4兆個のトランジスタが搭載されており、TSMCの5nmクラスの製造プロセスの採用により、性能は前世代より50%以上向上、同等の消費電力で前世代の2倍の性能を発揮できるとのことだ。
スペックの概要は以下の通りだ:
- 4兆個のトランジスタ
- 90万AIコア
- 125ペタフロップスのAIピーク性能
- 44GBのオンチップSRAM
- 5nm TSMCプロセス
- 外部メモリ:1.5TB、12TB、1.2PB
- 最大24兆個のパラメータでAIモデルを学習
- 最大2048 CS-3システムのクラスタ・サイズ
同社によると、WSE-3は新世代のAIコンピューター「Cerebras CS-3」に使用される予定だ。CS-3は125 ペタフロップスのピーク AI パフォーマンスを持ち、1.5TB、12TB、または1.2PBの外部メモリをサポートすることができ、パーティショニングやリファクタリングを行うことなく、巨大なモデルを単一の論理空間に格納することが出来る。これとは別に、CerebrasはQualcommと共同開発契約を締結し、AI推論の価格と性能の指標を10倍に高めることを目指している。
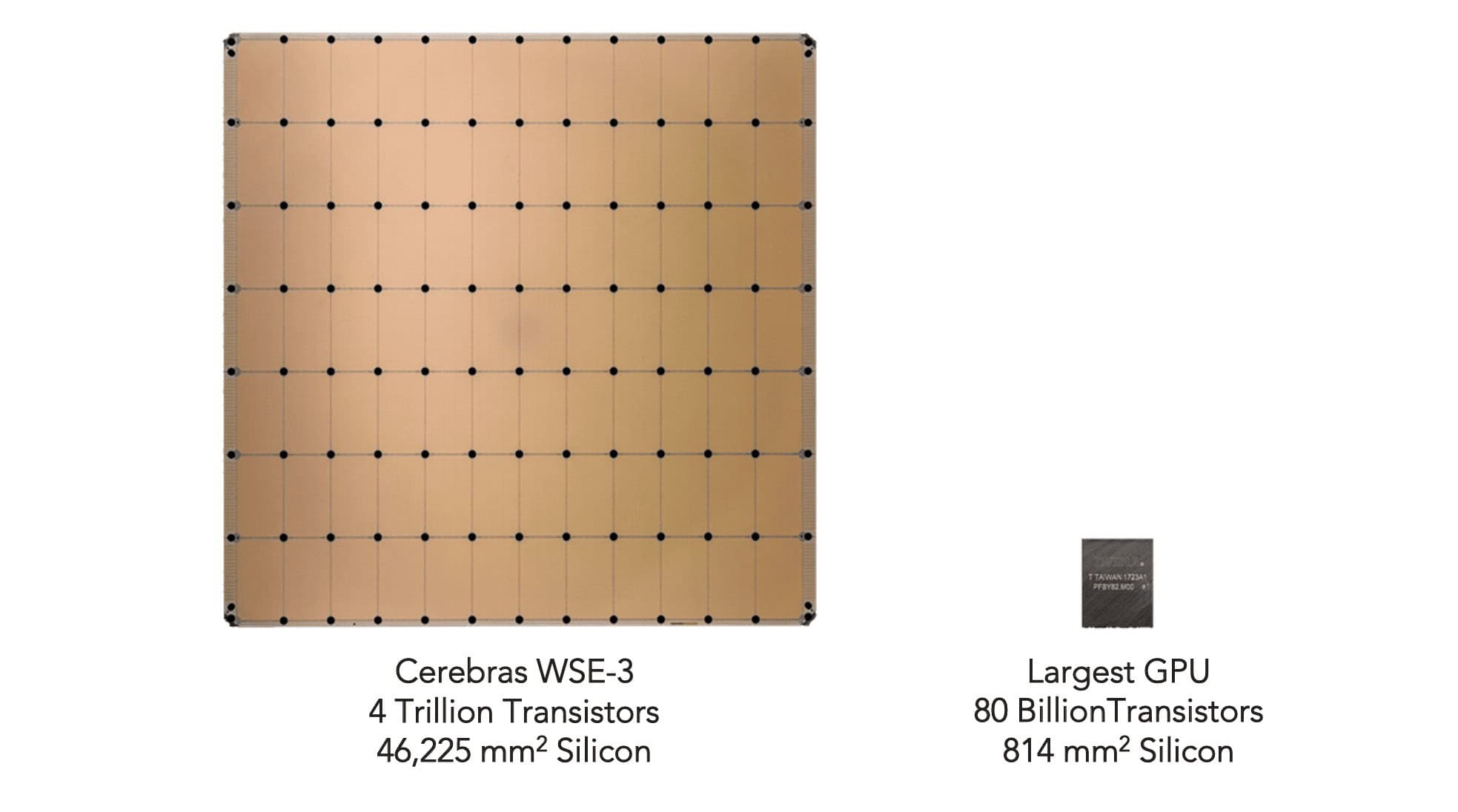
WSE-3は“ウェハー・スケール”というその名の通り、一辺が21.5センチの正方形のチップで、300ミリのシリコンウェハーをほぼ丸ごと使って1チップを作っている。ダイサイズは46,225mm2で、NVIDIA H100の826mm2より57倍大きい。どちらのチップもTSMC 5nmプロセスノードをベースにしている。H100は、16,896コアと528Tensorコアを搭載し、市場で最高のAIチップの1つとみなされているが、WSE-3はチップあたり90万個のAI最適化コアを提供し、その数は52倍となる。
WSE-3はまた、メモリ帯域幅が毎秒21ペタバイト(H100の7,000倍)、ファブリック帯域幅が毎秒214ペタビット(H100の3,715倍)だ。このチップには44GBのオンチップ・メモリが搭載されており、H100の880倍となっている。
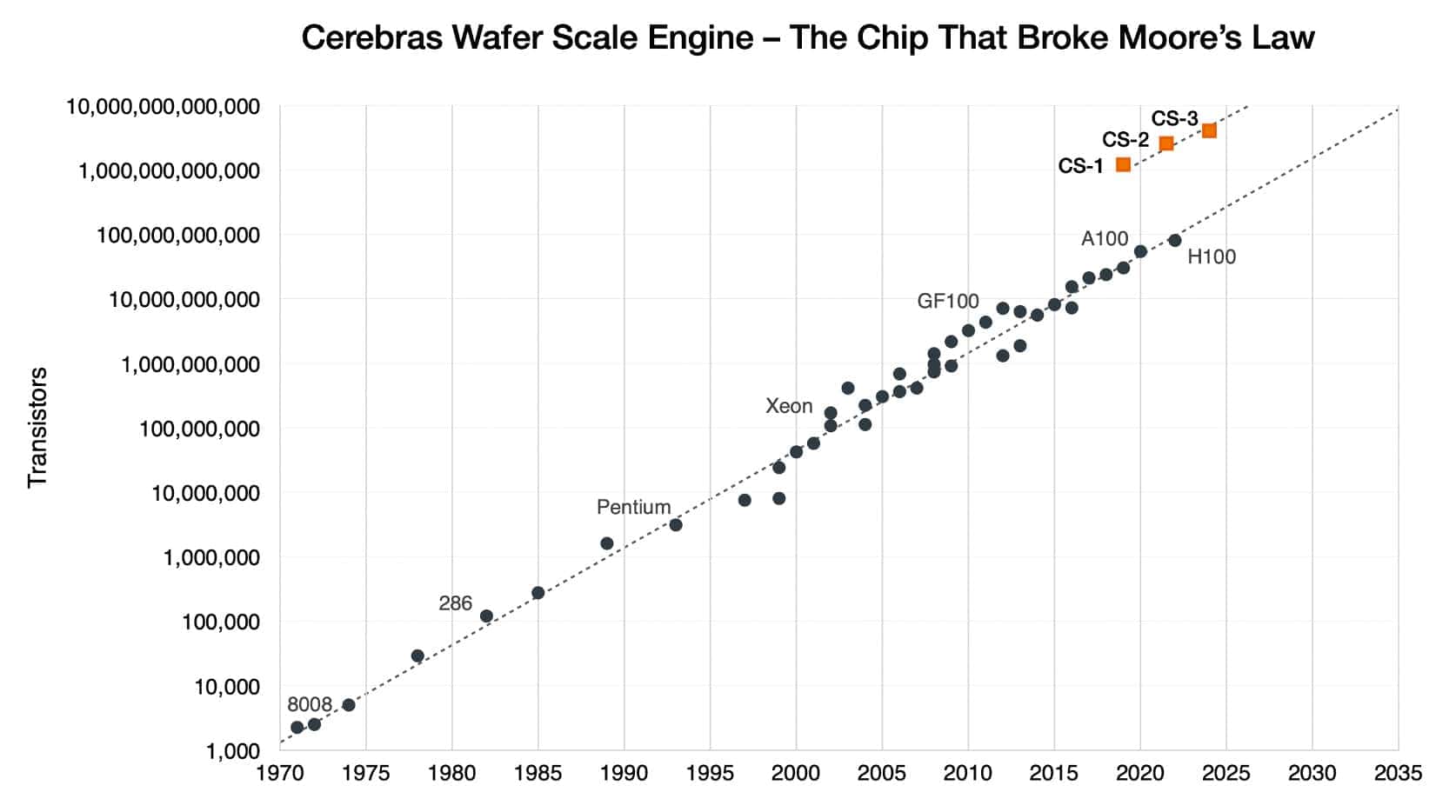
2019年にデビューした最初のチップは、TSMCの16nmプロセスを使って作られた。2021年に登場したWSE-2では、CerebrasはTSMCの7nmプロセスに移行した。WSE-3はTSMCの5nmプロセスで製造される。
トランジスタの数はWSE-1から3倍以上に増えている。その一方で、トランジスタが何に使われるかも変化している。例えば、チップに搭載されるAIコアの数は大幅に減少し、メモリの量や内部帯域幅も減少した。とはいえ、1秒あたりの浮動小数点演算(flops)のパフォーマンス向上は、他のすべての指標を上回っている。
WSE-2と比較して、WSE-3チップはコア数が2.25倍(900,000対400,000)、SRAMは2.4倍(44GB対18GB)、およびはるかに高速なインターコネクトを、すべて同じパッケージサイズで提供する。また、WSE-3のトランジスタ数は54%増加している(4兆対2.6兆)。
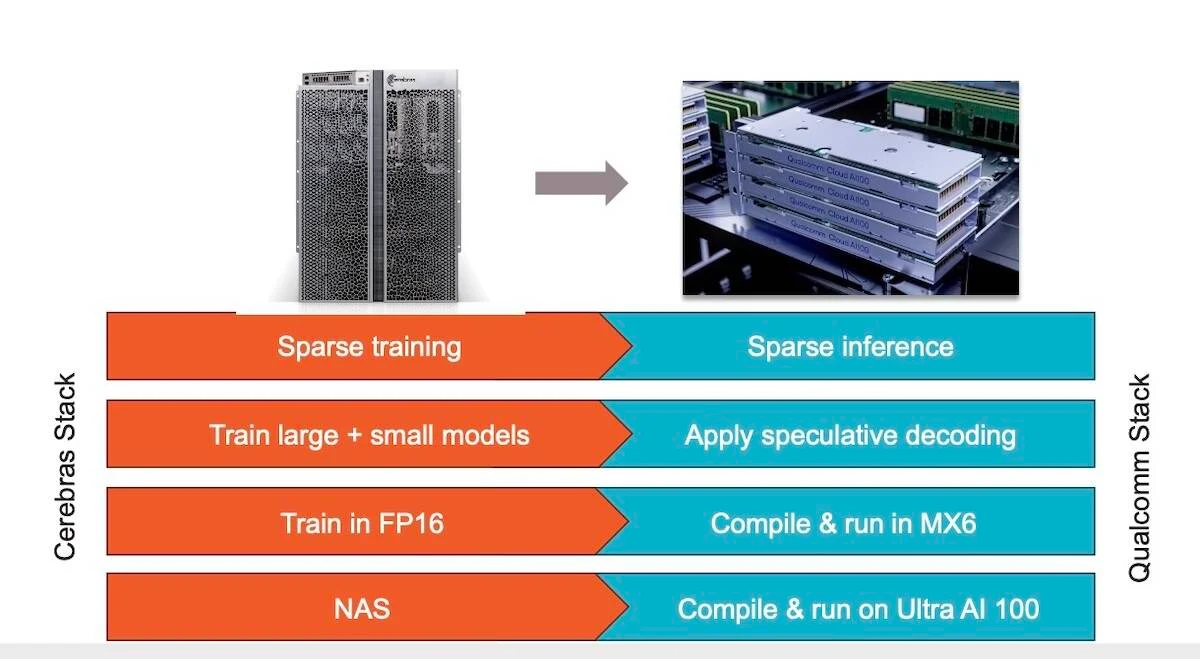
この新しいAIチップを搭載したコンピューター「CS-3」は、OpenAIのGPT-4やGoogleのGeminiの10倍の大きさを持つ、新世代の巨大言語モデルを学習するために設計されている。同社によると、CS-3は、他のコンピューターが必要とする一連のソフトウェアトリックに頼ることなく、現在最大のLLMの10倍以上である24兆パラメーターサイズまでのニューラルネットワークモデルを訓練できるという。Cerebrasによれば、CS-3で1兆パラメータのモデルを訓練するのに必要なソフトウェアは、GPUで10億パラメータのモデルを訓練するのと同じくらい簡単だということだ。
これは、人気のあるLLM Llama 70Bをゼロからトレーニングするのに1日かかるような構成である。しかし、同社によれば、そこまで大規模なものはまだ開発中だという。最初のCS-3ベースのスーパーコンピューター、Condor Galaxy 3は64台のCS-3で構成され、8エクサフロップスのAI演算性能を実現する。CS-2ベースの兄弟システムと同様、アブダビのG42がこのシステムを所有している。Condor Galaxy 1、2と合わせると、16エクサフロップスのネットワークとなる。
Cerebras のコンピューターはトレーニング用に作られているが、Cerebras のCEOであるAndrew Feldman氏は、AI導入の本当の限界は推論、つまりニューラルネットワークモデルの実行にあると言う。Cerebras の試算によると、地球上のすべての人がChatGPTを使用した場合、年間1兆ドルのコストがかかるという。(運用コストはニューラルネットワークモデルのサイズとユーザー数に比例する)
そこでCerebras とQualcomm は、推論コストを10分の1にすることを目標にパートナーシップを結んだ。Cerebras によると、このソリューションは、重みデータの圧縮やスパース性(不要な接続の刈り込み)、投機的デコーディング、MX6、ネットワーク・アーキテクチャ検索などといったニューラルネットワークの技術を応用するものだという。
スパース性を適切に実装すれば、アクセラレーターの性能を2倍以上にできる可能性がある。投機的デコーディングとは、初期応答を生成するために小型で軽量なモデルを使用し、その応答の精度をチェックするために大型のモデルを使用することで、展開中のモデルの効率を向上させるプロセスだ。
両社はモデルのメモリフットプリントを削減するためにMX6に注目している。MX6は量子化の一種で、重みを低精度に圧縮することでモデルを縮小するために使用できる。一方、ネットワーク・アーキテクチャ検索とは、特定のタスクに対応するニューラルネットワークの設計を自動化し、その性能を高めるプロセスである。
Cerebras が訓練したネットワークは、Qualcomm の新しい推論チップ「AI 100 Ultra」上で効率的に実行されるという。
Source








コメント