
Google Research、Google DeepMind、そしてマサチューセッツ工科大学(MIT)による共同研究チームが、AI業界における支配的なナラティブを覆す論文『Towards a Science of Scaling Agent Systems』を発表した。
現在、シリコンバレーをはじめとするテック業界では「Agentic AI(エージェント型AI)」が次のフロンティアとして熱狂的に迎えられている。「1つのAIモデルで解決できないなら、複数のAIエージェントを協力させれば良い」──この「More Agents Is All You Need(エージェントは多ければ多いほど良い)」という直感的な仮説は、多くの開発現場で事実上の標準戦略となりつつあった。
しかし、今回発表された大規模かつ厳密な実証実験は、その楽観論に冷や水を浴びせるものだ。研究結果は残酷なほど明確である。「エージェントの追加は、特定の条件下ではパフォーマンスを劇的に向上させるが、別の条件下では壊滅的な劣化(最大70%の低下)を招く」。
本稿では、180におよぶ構成実験、3つの主要LLMファミリー(GPT、Gemini、Claude)を横断した分析から導き出された「エージェント・スケーリングの科学」を紐解く。なぜあなたのマルチエージェントシステムは失敗するのか? その「見えない力学」を見てみよう。
「数の暴力」が通用しない
研究チームは、単なる概念実証ではなく、金融分析(Finance-Agent)、Webナビゲーション(BrowseComp-Plus)、ゲームプランニング(PlanCraft)、ワークフロー実行(Workbench)という、現実世界の複雑性を模した4つの多様なベンチマークで徹底的な検証を行った。
使用されたのは、OpenAI(GPT-5 series)、Google(Gemini 2.0/2.5 series)、Anthropic(Claude 3.7/4.0/4.5 series)という現行最高峰のモデル群だ。これらを「シングルエージェント(SAS)」と、独立型・集中型・分散型・ハイブリッド型という4つの「マルチエージェントシステム(MAS)」アーキテクチャで比較した結果、驚くべきデータが明らかになった。
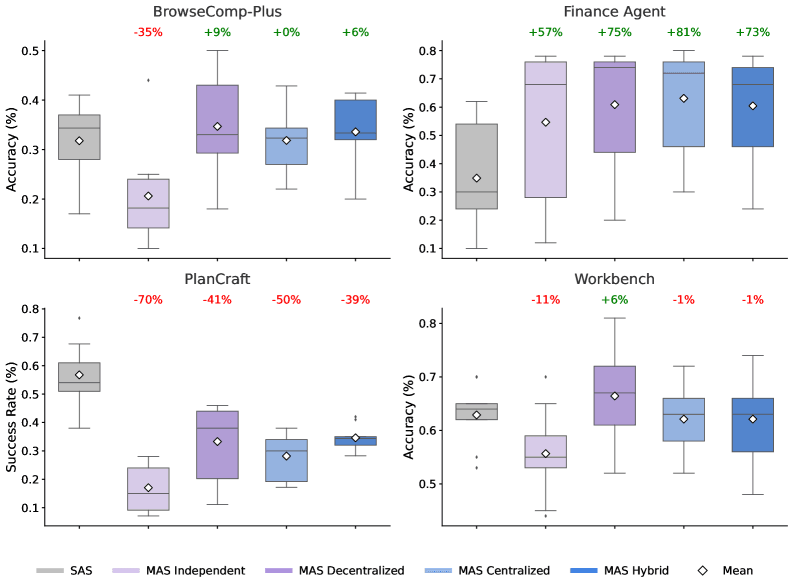
1. タスクによる「天国と地獄」の二極化
最も注目すべきは、マルチエージェント化によるパフォーマンスの変動幅だ。
- 金融分析タスク(Finance-Agent): 集中型のマルチエージェント構成にすることで、シングルエージェントと比較して最大80.9%のパフォーマンス向上を記録した。ここでは、複数のエージェントが並列して市場データやコスト構造を分析し、統合するアプローチが功を奏した。
- 逐次プランニングタスク(PlanCraft): 一方、Minecraft環境での製作計画においては、あらゆるマルチエージェント構成がパフォーマンスを悪化させ、最大で70%もの精度低下を招いた。
なぜこれほどの差が生まれるのか? この二極化こそが、本研究が解明した「スケーリングの法則」の核心である。
マルチエージェントを殺す「3つの見えない敵」
研究チームは、単に結果を羅列するのではなく、パフォーマンスを決定づける要因を数理モデル化(\(R^2=0.513\))することに成功した。そこから浮かび上がったのは、エージェントシステムを崩壊させる3つの支配的な力学である。
① ツールと協調のトレードオフ(The Tool-Coordination Trade-off)
「複雑なタスクほど、多くのエージェントで手分けすべきだ」という直感は、データによって完全に否定された。
研究データは、使用可能なツール(Web検索、コード実行など)の数が増えれば増えるほど、マルチエージェントシステムの効率が悪化することを示している。具体的には、ツールが豊富な環境では、エージェント間の「調整コスト(Coordination Tax)」が肥大化し、推論のためのトークン予算(計算リソース)を食いつぶしてしまうのだ。
- データ: シングルエージェントの効率性スコア(\(E_c\))が0.466であるのに対し、ハイブリッド型マルチエージェントは0.074まで低下する。
- 分析: 多くのツールを使いこなすには深い文脈理解が必要だが、エージェント間でメッセージをやり取りする際に情報が圧縮・断片化され、結果として「浅い」使い手が増えるだけの結果となる。
② 能力の飽和と「ベースラインのパラドックス」(Capability Saturation)
これは、高性能なモデルを使っている開発者にとって最も痛烈な発見だろう。
「シングルエージェント単体での正答率が45%を超えている場合、エージェントを追加しても効果は薄いか、むしろマイナスになる」
研究チームはこれを「ベースラインのパラドックス」と呼ぶ。モデル自体が十分に賢い場合、他者(他のエージェント)と合意形成するためのコミュニケーションコストが、協力による利益を上回ってしまうのだ。逆に、単体性能が低いモデルほど、群れることの恩恵(「三人寄れば文殊の知恵」効果)を受けやすい。しかし、GPT-5やGemini 2.5のようなフロンティアモデルを使用する場合、安易なマルチエージェント化はリソースの浪費に終わる可能性が高い。
③ トポロジー依存のエラー増幅(Topology-Dependent Error Amplification)
「独立したエージェントを並べて多数決を取れば(アンサンブル)、エラーは減るはずだ」という考えも、条件付きでしか成立しない。
- 独立型(Independent)の罠: エージェント同士が対話せず独立して動く構成では、エラーがシングルエージェント比で17.2倍に増幅された。チェック機能が働かず、各個体の幻覚(ハルシネーション)がそのまま出力されるためだ。
- 集中型(Centralized)の防壁: 一方、リーダー役(オーケストレーター)がサブエージェントの出力を検証する集中型構成では、エラーの増幅は4.4倍に抑えられた。
これは、組織論における「管理なき並列化は混乱を招く」という原則が、AIエージェントの世界でも数学的に成立することを証明している。
アーキテクチャの戦略的選択:いつ、何をどう使うか
本研究の白眉は、「とりあえずエージェントを増やせ」というヒューリスティクス(経験則)を廃し、タスクの性質に基づいた科学的なアーキテクチャ選定基準を提示した点にある。
1. 並列化可能なタスク → 「集中型(Centralized)」
金融分析のように、問題を「売上分析」「コスト分析」「市場調査」といった独立したサブタスクにきれいに分割できる場合、集中型のマルチエージェントシステムは劇的な効果を発揮する(+80.9%)。オーケストレーターがタスクを配分し、結果を統合するトップダウン型のアプローチが最適解だ。
2. 動的な探索が必要なタスク → 「分散型(Decentralized)」
Webブラウジングのように、検索結果によって次の一手が動的に変化し、広範な探索空間を持つタスクでは、リーダーを持たない分散型のアプローチが有効だった(+9.2%)。対等なエージェント同士が議論することで、局所解への陥没を防ぎ、多様な視点を確保できる。
3. 逐次的な依存関係があるタスク → 「シングルエージェント(SAS)」
ここが最大の落とし穴だ。Minecraftのクラフト計画やコーディングのように、「ステップAの結果がステップBの前提条件になる」という強い順序依存性があるタスクでは、マルチエージェント化は百害あって一利なしである。
情報がエージェント間で伝言ゲームされる過程で、文脈(Context)の微細なニュアンスが欠落し、後の工程で致命的な不整合を引き起こす。この場合、1つの強力なモデルが巨大なコンテキストウィンドウを維持しながら、一気通貫で思考する方が圧倒的にパフォーマンスが高い。
「協調のコスト」の経済学
ビジネス視点で見逃せないのが、コストの問題である。研究では、エージェント数を増やすと、推論ターン(やり取りの回数)が超線形(Superlinear)に増加することが判明した。
$$T \propto n^{1.724}$$
つまり、エージェント数を2倍にすると、必要な対話コストは2倍どころか約3.3倍に跳ね上がる。固定された予算(トークン量)の中でこれを行うと、1エージェントあたりに割り当てられる思考リソースが急速に枯渇し、浅薄な議論しかできなくなる。
研究チームは、「固定予算下では、エージェント数は3〜4体が限界」というハードキャップ(上限)を示唆している。これを超えると、コミュニケーションのオーバーヘッドが推論能力を食い尽くしてしまうのだ。
ベンダー別の興味深い特性(OpenAI vs Google vs Anthropic)
論文では、使用するLLMファミリーによって適したアーキテクチャが異なるという、極めて実務的な知見も示されている。
- OpenAI: 「ハイブリッド型」との相性が良い。階層的な指示と水平的な議論を組み合わせた複雑な構成でも高いパフォーマンスを発揮した。
- Anthropic (Claude): 「集中型」で安定する傾向がある。保守的だが確実な指示系統を好む特性が見られる。
- Google (Gemini): アーキテクチャ間での性能差が少なく、どの構成でも一貫したパフォーマンスを示した。これは、モデル自体の汎用性が高いか、あるいはプロンプトへの感度が他社と異なる可能性を示唆している。
AI開発者が明日から変えるべきこと
この研究は、エージェント型AIの可能性を否定するものではない。むしろ、無邪気な「量での解決」から、成熟した「質と構造による設計」への転換を促すマニフェストである。
筆者が分析するに、今後のAI開発における指針は以下の3点に集約される。
- 「45%ルール」の徹底: まずシングルエージェントでPoCを行う。その正答率が45%を超えているなら、安易なマルチエージェント化は避けるべきだ。コスト増に見合うリターンは得られない可能性が高い。
- タスクの構造解析: 対象タスクが「並列可能(Parallelizable)」か「逐次依存(Sequential)」かを見極めること。逐次依存タスクにマルチエージェントを適用するのは、現在の技術レベルではアンチパターンである。
- 検証ボトルの設置: 複数のエージェントを使う場合、必ずその出力を検証するゲートキーパー(オーケストレーター)を置くこと。放任主義(Independent)はエラーのカオスを生むだけだ。
「銀の弾丸」は存在しない。AIエージェントの設計は、魔法ではなく、物理法則にも似た厳密なエンジニアリングの領域に入ったのだ。
論文


