

Mark Zuckerberg CEOは25日、2025年のAI関連投資として600億から650億ドル規模の設備投資計画を発表した。これは前年比で約60%増となる過去最大規模の投資であり、同社のAI開発における野心的な展開を示している。
データセンターからAI開発まで―Metaの包括的な技術戦略
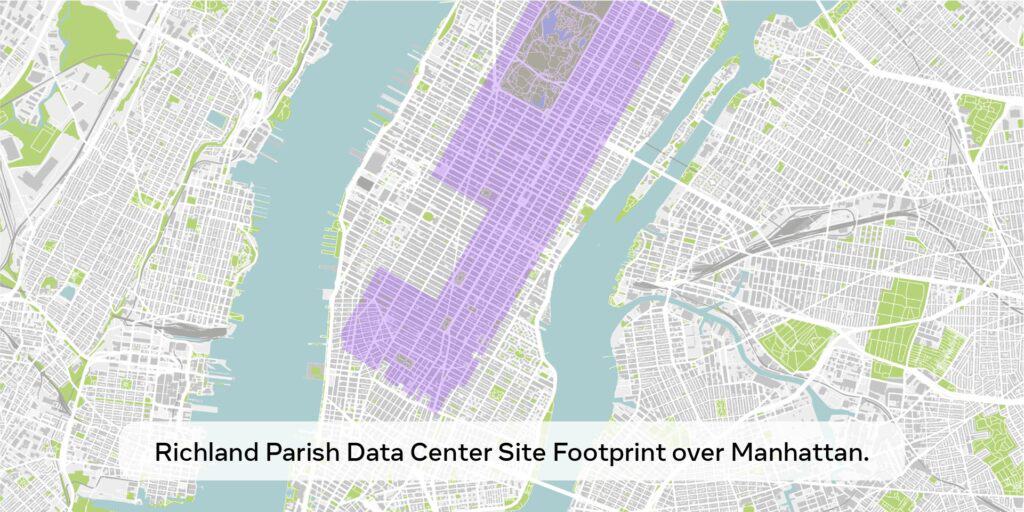
Metaの2025年に向けたAI戦略の中核となるのが、マンハッタンの「相当な部分をカバーする」規模の新データセンター建設計画だ。Zuckerberg CEOによれば、この施設は1ギガワット規模の計算能力を備え、年末までに130万台以上のGPUを収容する予定である。この計算能力は一般家庭約70万世帯分の電力消費量に相当し、同社のAI開発における野心的な展開を示している。
この大規模インフラを基盤として、同社は複数の重要なAIプロジェクトを推進している。その中心となるのが「Meta AI」と呼ばれるデジタルアシスタントの開発だ。Zuckerberg氏は10億人以上のユーザー獲得を目標に掲げており、これはChatGPTの月間アクティブユーザー数を大きく上回る規模となる。
さらに、同社はR&D部門の生産性向上を目指し、AIによるコード生成システムの開発も進めている。このAIエンジニアは、将来的に同社の研究開発プロセスに「増加的なコード貢献」を行うことが期待されている。
また、オープンソースの大規模言語モデル「Llama」シリーズの開発も継続している。2025年には新バージョンとなる「Llama 4」のリリースを予定しており、これまでのバージョンで培った技術的知見を活かしながら、さらなる性能向上を目指している。Zuckerberg氏は「我々は必要な資本を持っており、今後も数年にわたって投資を継続できる」と述べ、長期的な技術開発への強いコミットメントを示している。
これらの投資計画は、単なるインフラ整備にとどまらず、Metaの事業コアにAIを組み込み、米国のテクノロジーリーダーシップを強化することを目指したものだ。
激化するAI開発競争―効率性と投資規模の攻防
この大規模投資の発表を受け、Meta株は史上最高値となる647.49ドルを記録したが、AI開発をめぐる競争環境は一層の複雑さを増している。特に注目を集めているのが、中国のDeepSeekが開発した新モデルの突出した費用対効果だ。DeepSeekのV3モデルは、わずか2,048基のGPUと278万GPU時間、約600万ドルという投資で開発された。これはMetaのLlamaモデルが必要とした3,080万GPU時間、約6,000万ドルと比較して、驚異的な効率性を示す物だ。
この効率性の背景には、DeepSeekが採用するMixture-of-Experts(MoE)フレームワークがある。このアーキテクチャは処理時に必要なパラメータのみを活性化させることで、従来型モデルと比べて大幅な計算資源の削減を実現している。さらに、OpenAIの教師付き微調整(SFT)アプローチとは異なり、純粋な強化学習(RL)を採用することで、より自律的な推論能力の開発を可能にしている。
こうした技術革新は、APIの価格設定にも反映されている。DeepSeekは100万トークンあたり0.14ドルという価格設定を実現し、OpenAIの7.5ドルと比較して大幅なコスト削減を達成している。これは、高性能なAIモデルの開発には必ずしも巨額の投資が必要ではないことを示唆している。
一方で、MetaのZuckerberg氏は「我々には多年にわたる投資サイクルを支える資本力がある」と強調し、規模の経済を活かした開発アプローチに自信を示している。しかし、デジタル広告に依存する同社の収益構造を考慮すると、この大規模投資が収益化されるまでには相当の時間を要する可能性がある。
2025年は、このような効率性と規模の攻防が一層鮮明になる年となりそうだ。Metaの巨額投資とDeepSeekの効率重視のアプローチは、AI開発における異なる戦略を象徴している。市場は当面、これら両極のアプローチがもたらす成果を注視することになるだろう。
Sources








コメント