

Microsoft Researchが、AIの世界に新たな可能性を示す超軽量大規模言語モデル(LLM)「BitNet b1.58 2B4T」を発表した。このモデルは、AppleのM2チップを含む一般的なCPUでも効率的に動作するほどの軽量性を持ちながら、既存の高性能モデルに匹敵する能力を持つとされる。
BitNet b1.58 2B4Tとは? – 驚異の軽量化を実現した1ビットAI
BitNet b1.58 2B4Tは、Microsoftの研究者チームによって開発された、20億(2B)のパラメータを持ち、4兆(4T)トークンという膨大なデータセットで学習されたオープンソースのLLMだ。特筆すべきはその「軽量性」であり、AIモデルの根幹をなす「重み(weight)」と呼ばれるパラメータを、極めて少ない情報量で表現する技術を採用している点にある。
なぜ「1.58ビット」なのか? 量子化技術の核心
一部では「1ビットAI」として紹介されているが、テクニカルレポートによれば、BitNet b1.58 2B4Tの重みは正確には「1.58ビット」で表現される。これは、各重みが「-1」「0」「+1」の3つの値しか取らない「3値(ternary)」の形式を採用しているためだ。情報を2進数で表現する場合、1ビットでは「0」か「1」の2値しか表現できない。3つの値を表現するには、単純な1ビットでは足りず、かといって2ビット(4値表現可能)は過剰となる。情報理論に基づくと、3つの状態を表すのに必要な最小ビット数は log₂(3) ≒ 1.58ビットとなるため、「1.58ビットモデル」と称されている。
これは、一般的なLLMが重みを表現するために32ビットや16ビットの浮動小数点数(より多くの情報量を持ち、細かい数値を表現できる形式)を使用するのとは対照的だ。BitNetでは、この重みの情報量を大幅に削減(量子化)することで、モデル全体のサイズを劇的に縮小しているのだ。
軽量化がもたらす絶大なメリット
重みを1.58ビットに量子化することによる恩恵は大きい。
- メモリ消費量の大幅削減: モデルを保存・実行するために必要なメモリ量が格段に少なくなる。BitNet b1.58 2B4Tの非埋め込み(non-embedding)メモリ使用量はわずか0.4GB (400MB)だ。これは、比較対象となったモデルの中で次に小さいGoogleのGemma 3 1B(1.4GB)の約30%以下であり、他のモデルと比較しても圧倒的に小さい。
- 計算効率の向上: 重みが単純な整数(-1, 0, +1)であるため、複雑な浮動小数点演算が不要となり、より高速な計算が可能になる。特に、ビット単位での演算(bitwise operation)は非常に高速であるため、推論(AIが応答を生成する処理)時のレイテンシ(遅延時間)短縮に繋がる。
- CPUでの動作可能性: 上記のメリットにより、高性能なGPU(Graphics Processing Unit)だけでなく、一般的なPCに搭載されているCPU(Central Processing Unit)でも効率的に動作させることが可能になる。例として、AppleのM2チップのようなCPUでも実行できるようだ。
ただし、この極端な量子化は、一般的にモデルの表現力を低下させ、精度(accuracy)の低下を招く可能性がある。BitNet b1.58 2B4Tは、この潜在的な欠点を、4兆トークン(推定で3300万冊以上の書籍に相当する量)という大規模なデータセットで学習することによって補っていると考えられる。
性能はいかに? – 主要モデルとのベンチマーク比較
軽量化は魅力的だが、実際の性能はどうなのだろうか? Microsoftの研究チームは、BitNet b1.58 2B4Tを、同程度のパラメータ数を持つ主要なオープンソース・フル精度LLMと比較評価している。比較対象となったのは、MetaのLLaMa 3.2 1B、GoogleのGemma 3 1B、AlibabaのQwen 2.5 1.5Bなどだ。
ベンチマーク結果:効率と性能の両立
評価は、言語理解、数学的推論、コーディング能力、会話能力など、多岐にわたる標準的なベンチマークテストを用いて行われた。
- 総合性能: BitNet b1.58 2B4Tは、多くのテストで比較対象モデルに対して良好なスコアを記録し、いくつかのベンチマーク(例えば、算数問題のGSM8Kや常識推論のPIQA、WinoGrandeなど)では最高性能を示した。11のベンチマークの平均スコアでは、Qwen 2.5 1.5Bにわずかに及ばないものの、LLaMa 3.2 1BやGemma 3 1Bを上回り、非常に競争力のある結果を示している (Average: BitNet 54.19 vs Qwen2.5 1.5B 55.23)。
- メモリ効率: 前述の通り、メモリ使用量(非埋め込み)は0.4GBと、比較対象の中で群を抜いて少ない(LLaMa 3.2 1B: 2GB, Gemma 3 1B: 1.4GB, Qwen 2.5 1.5B: 2.6GB)。
- 推論速度 (CPU): CPUでのデコード(文章生成)レイテンシも29msと、最も高速であった(LLaMa 3.2 1B: 48ms, Gemma 3 1B: 41ms, Qwen 2.5 1.5B: 65ms)。これは、TechCrunchが報じた「他の同サイズモデルより高速(場合によっては2倍)」という点を裏付けている。
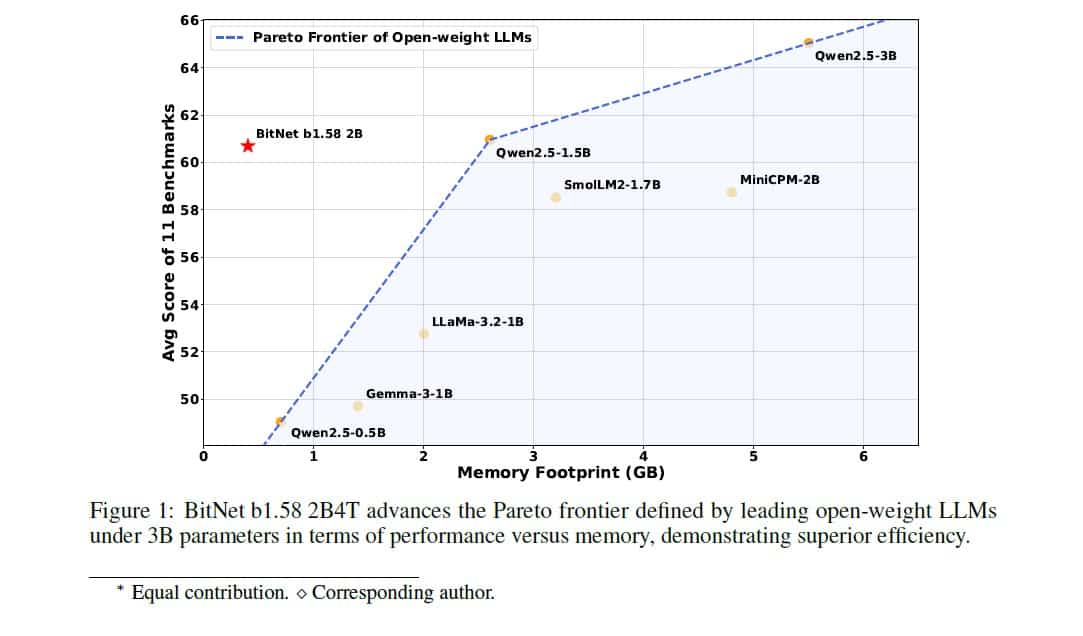
テクニカルレポートの図1(Figure 1)は、メモリ使用量(横軸)と平均ベンチマークスコア(縦軸)の関係を示しており、BitNet b1.58 2B4Tが、既存のオープンLLMが形成する「パレートフロンティア」(性能と効率のトレードオフを示す境界線)を大きく左上(より少ないメモリでより高性能)に押し上げていることを視覚的に示している。これは、BitNetが単に小さいだけでなく、「効率対性能」の観点から見て非常に優れたモデルであることを意味する。
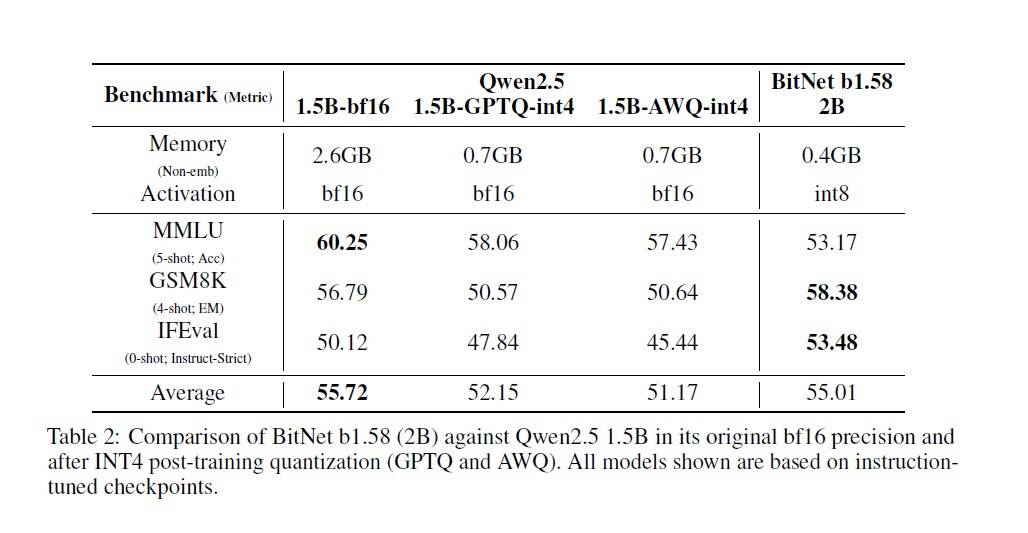
さらに、テクニカルレポートでは、既存モデルを後から4ビット整数(INT4)に量子化するPTQ(Post-Training Quantization)手法と比較しても、BitNet b1.58 2B4Tの方がメモリ効率が高く、かつ性能低下が少ない(むしろINT4版Qwen2.5 1.5Bより平均スコアが高い)ことを示している(Table 2)。これは、最初から1.58ビットで学習する「ネイティブ」なアプローチの有効性を示唆している。
なぜCPUで動くのか? – bitnet.cppフレームワークの役割
BitNet b1.58 2B4TがCPU上でその真価を発揮するには、モデル自体の軽量性だけでは不十分である。Microsoftは、このモデルのために特別に最適化された推論フレームワーク「bitnet.cpp」を開発し、オープンソースで公開している。
専用フレームワークの重要性
ちなみに、BitNet b1.58 2B4Tを、Hugging Faceなどで一般的に使われている標準的なtransformersライブラリ(たとえ必要なフォークを使ったとしても)で実行しても、期待されるメモリ効率や速度の向上は得られない。
bitnet.cppは、C++で書かれたライブラリであり、1.58ビットという特殊な量子化形式のモデルをCPU上で高速かつロスレス(学習時と同等の精度)で実行するために最適化されたカーネル(計算処理の中核部分)を提供する。GitHubリポジトリによれば、重みデータを効率的に処理し、低レベルでのビット演算などを活用することで、CPU上での推論を可能な限り高速化するように設計されている。
現状の制約と今後の展開
記事執筆時点でbitnet.cppはCPU実行に最適化されており、AI処理で広く使われているGPUや、近年のプロセッサに搭載され始めているNPU(Neural Processing Unit)といったAI専用ハードウェアへの最適化は「今後対応予定」とされている。これは、BitNetの潜在能力を最大限に引き出す上での課題であり、今後の開発が待たれる部分である。
とはいえ、特別なハードウェアがなくとも、手元のPCのCPUで最新のLLMを試せるようになった意義は大きい。モデルの重みはHugging Faceで、bitnet.cppのコードはGitHubで公開されており、誰でもダウンロードして実験することが可能である。
技術的背景 – BitNetを支えるアーキテクチャと学習法
BitNet b1.58 2B4Tの驚異的な効率と性能は、単なる量子化だけでなく、モデルのアーキテクチャや学習方法における工夫によって支えられている。
アーキテクチャ:Transformerを1ビット向けに最適化
- ベース: 基盤となっているのは、近年のLLMで標準的に用いられるTransformerアーキテクチャである。
- BitLinearレイヤー: 最大の変更点は、Transformer内の主要な計算要素である線形レイヤー(torch.nn.Linear)を、カスタム設計された「BitLinear」レイヤーに置き換えたことである。このレイヤー内で、前述の1.58ビット重み量子化(absmean方式)と、後述する8ビット活性化量子化が行われる。
- 活性化量子化: 重みだけでなく、ネットワーク内を流れる信号である「活性化(activation)」も8ビット整数(int8)に量子化される(absmax方式、トークンごと)。これにより、計算時のメモリ使用量をさらに削減し、演算を高速化する。モデル全体としては「W1.58A8」(Weight 1.58bit, Activation 8bit)形式となる。
- 正規化: 学習の安定性を高めるために、subln(Sub-LayerNorm)という正規化手法が採用されている。これは量子化されたモデルの学習において特に有効とされる。
- 活性化関数: 一般的なSwiGLUの代わりに、ReLUを2乗した「ReLU²」が活性化関数として用いられている。これは1ビットの文脈において、モデルのスパース性(計算に関与しない要素の割合)を高め、計算特性を改善する可能性があるという研究に基づいている。
- 位置エンコーディング: RoPE(Rotary Position Embeddings)が使用されており、これは現代的な高性能LLMの標準的な手法である。
- バイアス除去: LLaMAなどのアーキテクチャと同様に、ネットワーク内の全てのバイアス項(計算のオフセット値)が除去されている。これにより、パラメータ数を削減し、量子化を単純化する効果も期待される。
学習プロセス:効率と性能を引き出す3段階
BitNet b1.58 2B4Tは、ゼロから(from scratch)学習されている。学習は大きく3つの段階で構成される。
- 事前学習 (Pre-training): 4兆トークンという膨大なテキスト・コードデータを用いて、モデルに広範な知識と言語能力の基礎を叩き込む段階。学習率や重み減衰(過学習を防ぐ手法)を2段階で調整する特殊なスケジュールを採用。特に初期段階では、フル精度モデルよりも安定している1ビットモデルの特性を活かし、比較的高めの学習率で積極的に学習を進める。
- 教師ありファインチューニング (SFT – Supervised Fine-tuning): 事前学習済みモデルに対し、指示応答形式や会話形式のデータセットを用いて、ユーザーの指示に従う能力や対話能力を向上させる段階。ここでも、フル精度モデルよりもやや高めの学習率と、より多くの学習エポック(データセットを繰り返し学習する回数)が必要であったとされる。
- 直接選好最適化 (DPO – Direct Preference Optimization): SFT後、人間の好み(どちらの応答が良いか)に関するデータを用いて、モデルの応答がより「役に立ち」「安全」になるように微調整する段階。これにより、報酬モデルを別途学習する必要がある従来のRLHF(人間フィードバックからの強化学習)に代わる効率的な方法で、モデルの挙動を人間の期待に近づける。
これらのアーキテクチャ上の工夫と段階的な学習プロセスが組み合わさることで、極端な量子化を行いながらも高い性能を維持することを可能にしている。
BitNetの意義と将来性 – AIの民主化は進むか?
BitNet b1.58 2B4Tの登場は、AI分野、特にLLMの開発と利用において、いくつかの重要な意味を持つ。
AIの省エネ化とローカル実行への道
LLMの学習と運用には膨大な計算資源と電力が必要であり、環境負荷やコストが課題となっている。BitNetのような軽量モデルは、その根本的な解決策の一つとなり得る。
- エネルギー効率: 消費電力が大幅に削減されるため、AI運用に伴うエネルギー問題の緩和に貢献する可能性がある。
- データセンター依存の低減: 高価なGPUクラスターを持つ巨大なデータセンターに頼らずとも、ローカルな環境(個人のPCやスマートフォン、エッジデバイスなど)で高度なAIを実行できる可能性が広がる。
- アクセシビリティの向上: 最新の高価なプロセッサ(NPU内蔵など)や強力なGPUを持たないユーザーでも、AIの恩恵を受けられるようになるかもしれない。これは、AI技術の「民主化」を加速させる可能性がある。
今後の課題と展望
BitNet b1.58 2B4Tは大きな可能性を示したが、まだ発展途上の技術でもある。
- 互換性と最適化: 現状ではbitnet.cppのような専用フレームワークが必要であり、GPUやNPUへの最適化は今後の課題である。既存のAIエコシステムとの互換性も重要となる。
- さらなる性能向上: 現状でも高い性能を示しているが、フル精度の最先端モデルにはまだ及ばない部分もある。技術レポートで示されているように、より大規模なモデル(7B、13Bパラメータ以上)での1ビット学習や、さらなる学習データの拡充による性能向上が期待される。
- ハードウェアとの協調設計: 1ビット演算に最適化された新しいハードウェア(CPU, GPU, NPU)が登場すれば、BitNetのようなモデルの性能と効率は飛躍的に向上する可能性がある。ソフトウェアとハードウェアが連携して進化していくことが重要になるだろう。
- 応用範囲の拡大: 現在は英語中心だが、多言語対応や、テキスト以外のデータ(画像など)を扱うマルチモーダルへの応用も今後の重要な研究方向である。
Microsoft BitNet b1.58 2B4Tは、「LLMは巨大でなければならない」という常識に一石を投じる、画期的な成果と言えるだろう。オープンソースとして公開されたことで、世界中の研究者や開発者がこの技術を試し、改良し、新たな応用を生み出していくことが期待される。AIがより身近で、より持続可能な技術となる未来への、大きな一歩となるかもしれない。
Source
- Hugging Face: microsoft/bitnet-b1.58-2B-4T
- via TechCrunch: Microsoft researchers say they’ve developed a hyper-efficient AI model that can run on CPUs

