

NVIDIAがHot Chips 2024カンファレンスで次世代AIプラットフォーム「Blackwell」の詳細を公開した。発表されたBlackwellは、性能と効率性の面で大幅な向上を実現しており、業界に大きな衝撃を与えるものだ。本稿では、NVIDIAが明らかにしたBlackwellプラットフォームの主要な特徴と技術革新について詳しく解説する。
Blackwellアーキテクチャの革新的技術
既にNVIDIAが予告していたように、Blackwellはチップそのものを指すだけではなく、それを取り巻く様々な技術を包含したプラットフォームとして紹介されている。

Blackwellプラットフォームの中核を成すのはもちろん、208億トランジスタを搭載した巨大なAIスーパーチップだろう。このチップはTSMC 4NPプロセスを用いて製造され、1600mm2を超えるダイサイズを持つ。NVIDIAは単一のGPUとしては過去最高のAI計算能力、メモリ帯域幅、相互接続帯域幅を実現したとしている。

Blackwellは1つのGPUでエキスパートモデルを扱えるほど大きく、強力だ。

特筆すべき技術革新の一つが、NV-HBI(NVIDIA High-Bandwidth Interface)と呼ばれる新しい高帯域幅インターフェースである。これにより、2つのGPUダイを10TB/sの双方向帯域幅で接続し、単一のGPUとして機能させることが可能となった。この技術により、Blackwellは従来のモノリシック設計の利点を維持しつつ、マルチダイアーキテクチャの利点も享受することに成功している。

ちなみに、NVIDIA GB200 Superchipは、NVIDIA Grace CPUと2つのNVIDIA Blackwell GPUをハーフワイドプラットフォームに搭載したものだ。 これを2つ横に並べると、各コンピュートトレイには4つのGPUと2つのArm CPUが搭載されることになる。

Blackwellの心臓部とも言える第5世代Tensorコアには、新たなMicro Tensor Scaled FP(浮動小数点)フォーマットが採用されている。FP4、FP6、FP8といった新しい低精度フォーマットをサポートすることで、AIワークロードの処理効率が劇的に向上している。例えば、FP4フォーマットはHopperアーキテクチャのFP8と比較して4倍の速度向上を実現している。
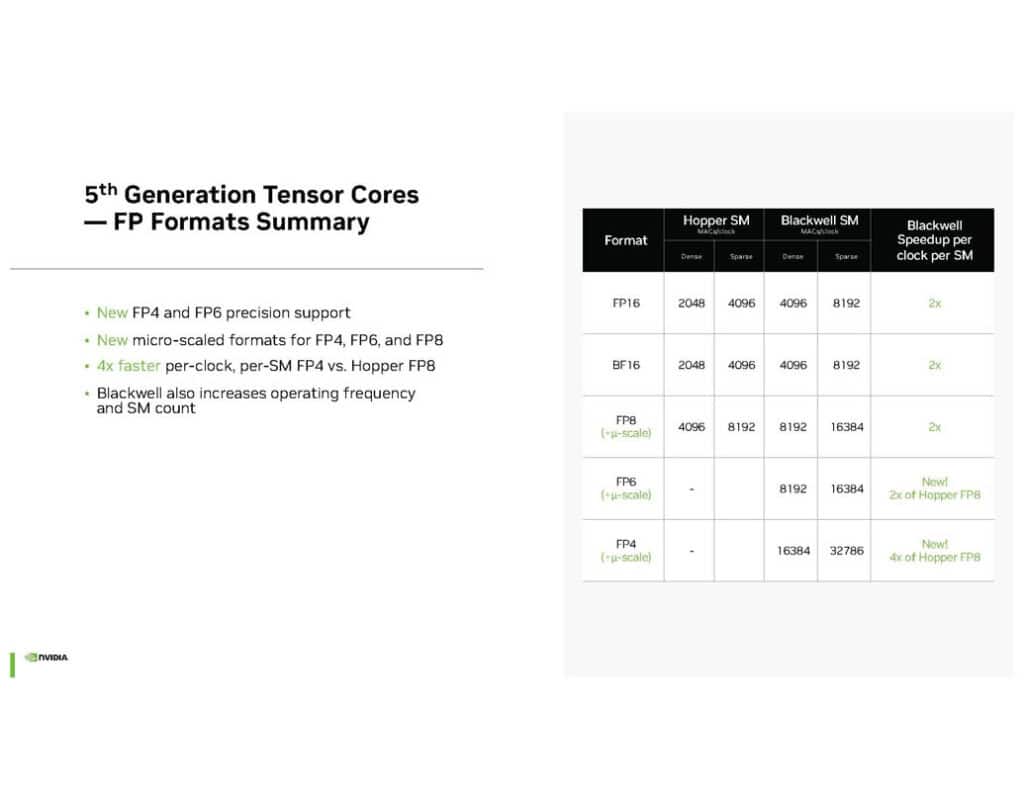
これらの新しいデータフォーマットは、Tensorコアの性能を最大限に引き出すために設計されている。従来のFP16やBF16フォーマットと比較して、新しいフォーマットはより少ないビット数で情報を表現することができる。これにより、同じハードウェアリソースでより多くの演算を並列に実行することが可能となり、結果として全体的な処理速度が向上する。NVIDIAによれば、推論用のFP4は、場合によってはBF16の性能に近づけることができるという。

以下ははFP16推論とFP4を使った画像生成タスク。 これらのウサギは同じではないが、ぱっと見はかなり近い。

NVIDIAはこの新技術を「Quasar Quantization」と呼んでいる。これは低精度フォーマットを高精度データに変換する技術で、最適化されたライブラリ、ハードウェアおよびソフトウェアトランスフォーマーエンジン、低精度数値アルゴリズムを組み合わせて実現されている。NVIDIAによれば、量子化されたFP4フォーマットはBF16と同等のMMLU(Massive Multitask Language Understanding)スコアを達成し、340Bパラメータの大規模言語モデルでも同等の精度を維持できるという。
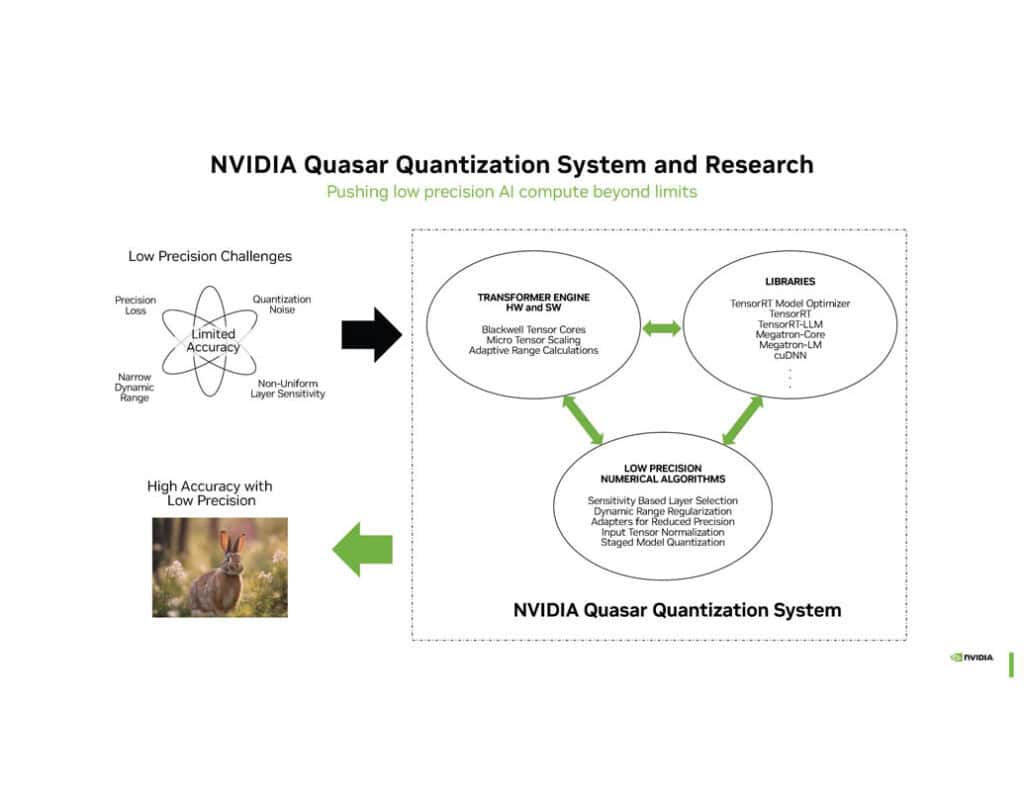
この技術の重要性は、AIモデルの推論(インファレンス)段階で特に顕著だ。Quasar Quantizationを用いることで、モデルのサイズを大幅に縮小しつつ、精度をほとんど落とすことなく推論を行うことができる。これは、エッジデバイスやモバイル機器でのAI実行を可能にし、データセンターの効率を大幅に向上させる可能性を秘めたものだ。
Blackwellプラットフォームのもう一つの重要な要素が、第5世代NVLinkテクノロジーである。これにより、最大576基のGPUを相互接続し、1.8TB/sの帯域幅を実現している。さらに、第4世代NVLinkスイッチチップは800mm2を超える面積を持ち、72基のGPUを接続可能な「GB200 NVL72」ラックでは7.2TB/sの全対全双方向帯域幅を提供している。
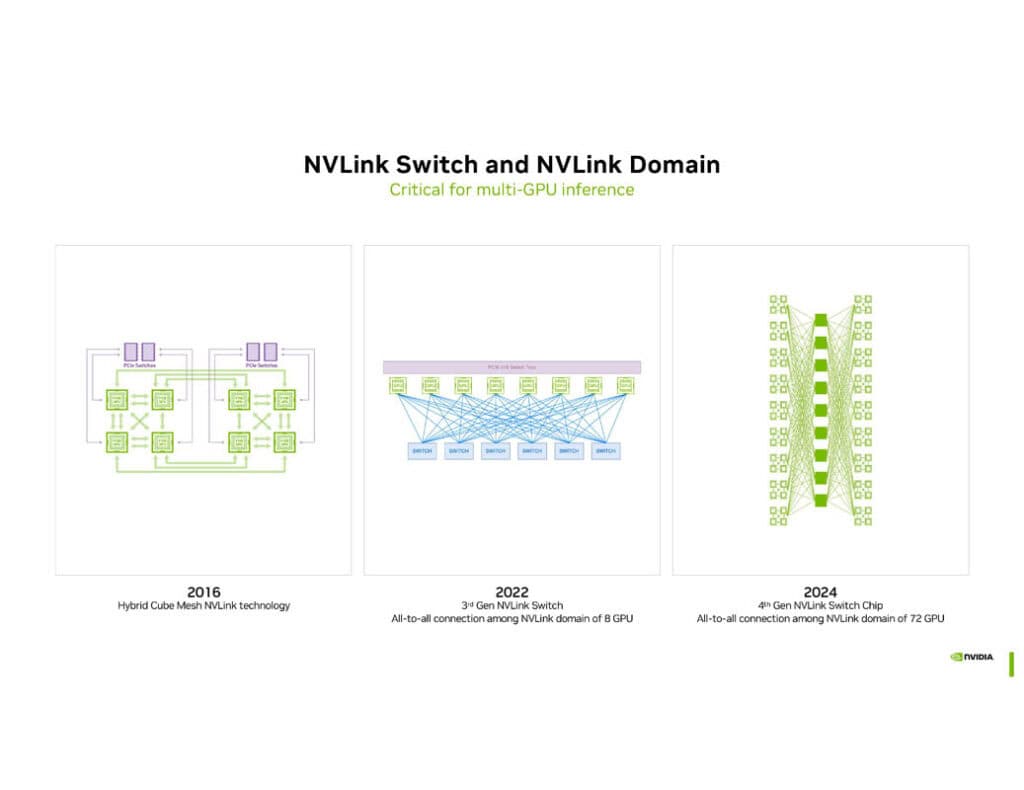
この高度な相互接続技術は、大規模なAIモデルの学習と推論において重要な役割を果たす。複数のGPUを効率的に連携させることで、数兆パラメータ規模のモデルでも高速に処理することができる。NVIDIAは、この技術によりGPT-MoE 1.8Tのような巨大モデルの処理が可能になったと主張している。
さらに、BlackwellプラットフォームにはSpectrum-Xと呼ばれる新しいイーサネットファブリックが導入されている。これは、Spectrum-4スイッチチップとBluefield-3 DPUから構成され、AIワークロード向けに最適化されたネットワークインフラストラクチャを提供する。Spectrum-4は100億トランジスタを搭載し、51.2Tの帯域幅を実現している。

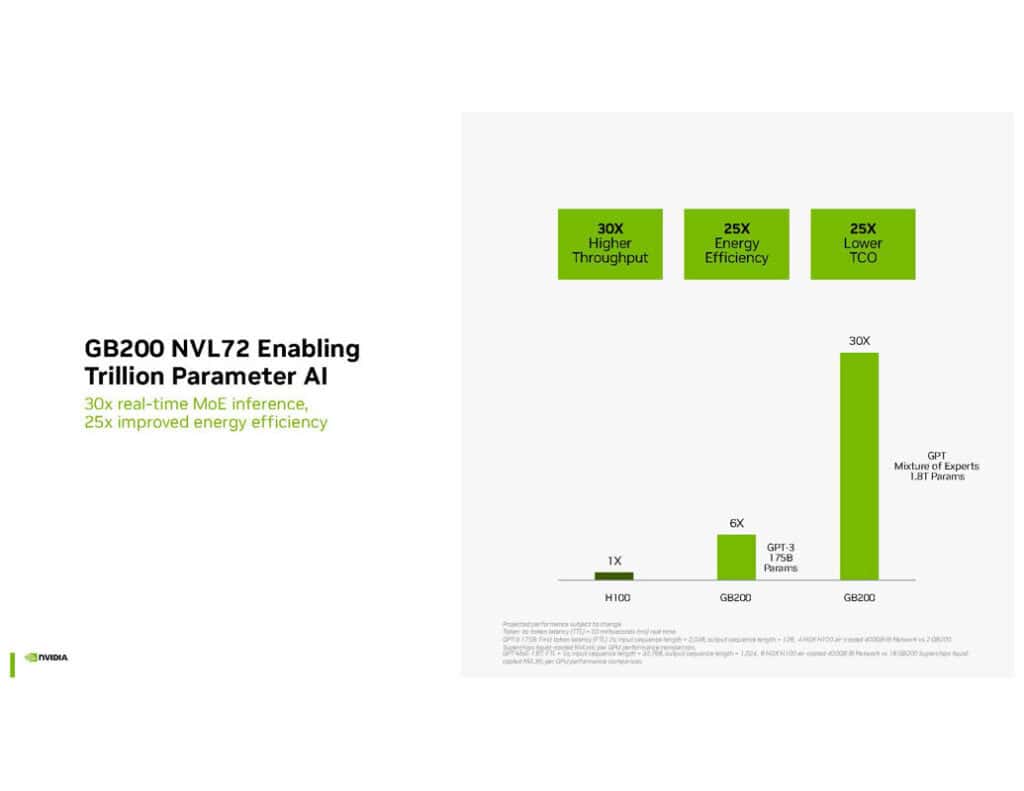
NVIDIAは、Blackwellプラットフォームが従来のHopperアーキテクチャと比較して、リアルタイム推論で30倍、エネルギー効率で25倍の性能向上を実現したと主張している。これらの数字は、AIの研究開発や産業応用に大きな影響を与える可能性がある。
さらに注目すべきは、NVIDIAの今後のロードマップである。2025年には計算密度とメモリを強化した「Blackwell Ultra」、2026年から2027年にかけてはHBM4メモリと新アーキテクチャを採用した「Rubin」および「Rubin Ultra」の投入を予定しているという。これは、NVIDIAがAI技術の急速な進化に合わせて、継続的にイノベーションを推進していく姿勢を示している。
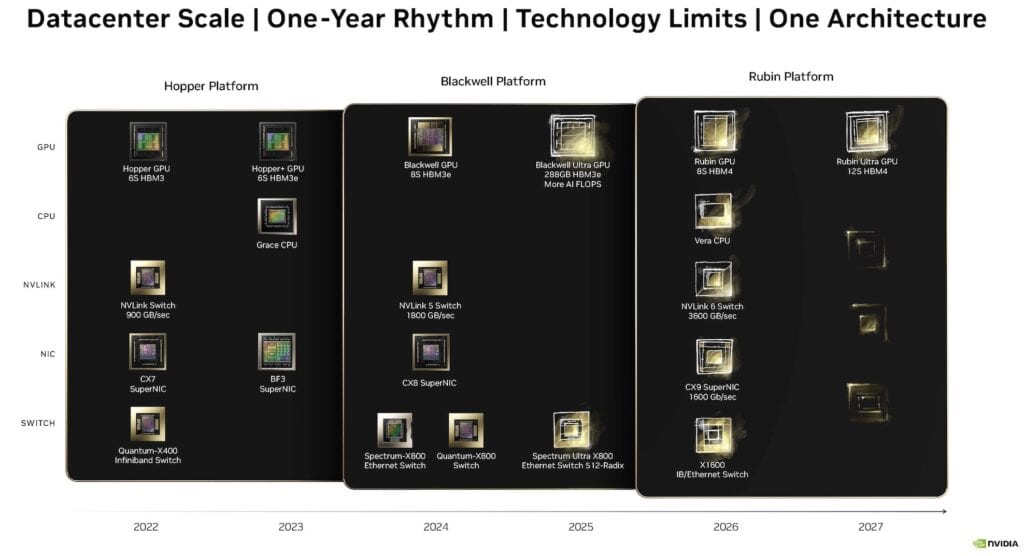
このように、NVIDIAのBlackwellプラットフォームは、AIコンピューティングの限界を押し広げる革新的な技術の結集といえる。新しいデータフォーマット、高速な相互接続技術、効率的な量子化システムなどの組み合わせにより、これまで不可能だと思われていたスケールのAIモデルの学習と推論が現実のものとなりつつある。今後のAI開発や大規模言語モデルの進化に与える影響は計り知れず、業界全体に大きな変革をもたらすことが予想される。Blackwellの登場により、AIの応用範囲はさらに拡大し、新たなイノベーションの波が起こる可能性が高い。










コメント