「大きければ大きいほど性能が良い」はテクノロジー業界における常識であり、不文律だった。特に生成AIの分野では、パラメータ数が多ければ多いほど、つまりモデルが巨大であればあるほど、生成される画像の品質は高まると考えられてきた。しかし、Snap(Snapchatの親会社)の研究チームが発表した最新の論文は、この常識に真っ向から挑むものだ。
彼らが開発した「SnapGen++」は、わずか0.4億(0.4B)パラメータという極小サイズでありながら、数百億パラメータを持つクラウド上の巨大モデル(Flux.1-devやStable Diffusion 3.5など)に匹敵、あるいは凌駕する画質を叩き出した。しかも、iPhone 16 Pro Max上で、1024×1024ピクセルの高解像度画像をわずか1.8秒で生成するという。
この成果は、これまでクラウドに依存していたAIの知能が、我々の掌(エッジデバイス)に完全移行する「オンデバイスAI」時代の到来を予見させるものだ。本稿では、公開された論文に基づき、その驚異的なパフォーマンスの裏にある技術的革新と、業界に与えるインパクトを見ていきたい。
巨人殺しのパフォーマンス:0.4Bが12Bを凌駕する「異常事態」
まず、SnapGen++が達成した数値的成果がいかに異常であるかを理解する必要がある。
圧倒的な速度と品質の両立

論文によると、SnapGen++(Smallモデル:0.4Bパラメータ)は、iPhone 16 Pro Max上で動作させた際、1024×1024の画像を1.8秒で生成することに成功している。前モデルであるSnapGen(U-Netベース)と比較しても、画質を大幅に向上させつつ、同等の推論速度を維持している。
さらに驚くべきは、その品質評価スコアだ。テキストと画像の整合性を測るベンチマーク「GenEval」や「DPG-Bench」において、SnapGen++は以下の巨大モデルと同等、あるいはそれ以上のスコアを記録した。
- Flux.1-dev (12Bパラメータ): 現在のオープンソース界の王者。SnapGen++の約30倍のサイズ。
- Stable Diffusion 3.5-Large: 安定性と画質に定評がある最新モデル。
- SANA (1.6B): 高効率な最新モデルだが、これをも上回る。
通常、パラメータ数を30分の1に減らせば、生成される画像は崩壊し、プロンプトの理解度は著しく低下する。しかし、SnapGen++は「フォトリアルな描写」「複雑なプロンプトの忠実な再現」「テキストの埋め込み」において、サーバーグレードのモデルと遜色ない結果を示している。これは、従来のAI開発における「スケーリング則(規模拡大則)」に対する強烈なアンチテーゼである。
技術的ブレイクスルー:なぜ「極小」で「最強」が作れたのか?
なぜこれほど小さなモデルが、巨人を倒すことができたのか。その秘密は、Snapの研究チームが採用した、徹底的に効率化されたアーキテクチャと学習手法にある。彼らは既存のモデルを単に「小さくした」のではなく、モバイルデバイスのために構造をゼロから再発明している。
U-NetからDiTへのパラダイムシフト
従来の軽量モデル(SnapGenなど)の多くは、Stable Diffusionなどで採用されている「U-Net」アーキテクチャをベースにしていた。しかし、SnapGen++は、SoraやStable Diffusion 3で採用された最新のトレンドであるDiffusion Transformer (DiT) を採用している。
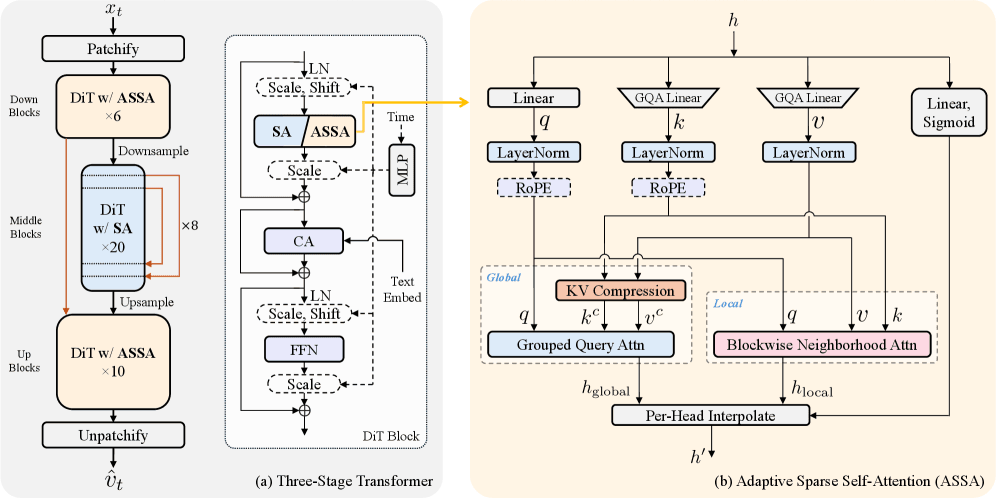
DiTはスケーラビリティと画質に優れる反面、計算コストが非常に高く、メモリ制約の厳しいスマホでの動作は「不可能」とされてきた。SnapGen++は、このDiTをモバイル向けに極限まで最適化することで、U-Netの限界を突破したのである。
2. 「適応型スパース注意機構」による計算コストの削減
DiTの最大のボトルネックは、画像内の全トークン(要素)同士の関係性を計算する「Attention(注意機構)」の計算量が、解像度の二乗で増大することだ。1024pxの画像生成において、この計算はスマホのメモリを食い尽くす。
SnapGen++は、Adaptive Sparse Self-Attention (ASSA) という独自機構でこれを解決した。
- グローバルな圧縮: 画像全体の大まかな構成を把握するために、キーとバリュー(KV)を圧縮して計算量を激減させる。
- ローカルな詳細化: 細部のテクスチャを描写するために、Blockwise Neighborhood Attention (BNA) を導入。画像をブロックに分割し、各ピクセルが近隣のピクセルのみを参照するように制限する。
これにより、「全体像の把握」と「細部の書き込み」を両立させつつ、計算コストを劇的に削減することに成功した。これは人間が絵を描く際、全体のアタリを取ってから細部を書き込むプロセスに似ており、極めて理にかなったアプローチだ。
3. エラスティック・トレーニング(Elastic Training)
SnapGen++のユニークな点は、その学習方法にもある。彼らは単一の固定モデルを作るのではなく、「スーパーネットワーク」と呼ばれる巨大な構造の中で、異なるサイズ(Tiny, Small, Full)のサブネットワークを同時に学習させた。
これにより、一つのモデル構造から、用途に応じて「0.3Bの超軽量版」や「0.4Bの高性能版」を切り出すことができる。この手法により、各サブモデル間で知識が共有され、単独で学習させるよりも高い精度と安定性を獲得した。
4. 知識蒸留と4ステップ生成の魔法
極めつけは、推論ステップ数の削減だ。通常の拡散モデルは、ノイズ除去を20〜50回繰り返して画像を生成するため時間がかかる。SnapGen++は、K-DMD (Knowledge-Guided Distribution Matching Distillation) という手法を用いている。
これは、巨大な教師モデル(Qwen-Imageなど)の「知識」を生徒モデル(SnapGen++)に注入し、さらに敵対的生成ネットワーク(GAN)のようなアプローチで、わずか4ステップで完全な画像を生成できるよう訓練する技術だ。これにより、推論にかかる時間が物理的に数分の一に短縮された。
この技術がもたらす「不可逆な変化」
SnapGen++の登場は、単に「スマホで綺麗な絵が出せる」以上の意味を持つ。これは、IT業界全体のパワーバランスを変える可能性を秘めている。
クラウドコストからの解放とプライバシーの確立
現在、AIサービスの多くはGPUクラウドの莫大な運用コストに苦しんでいる。ユーザーが画像を1枚生成するたびに、企業のサーバー代が課金される構造だ。しかし、SnapGen++のように推論が完全にデバイス側で完結すれば、サービス提供側の推論コストは実質ゼロになる。
さらに、ユーザーのプロンプトや生成画像が一度もクラウドに送信されないため、プライバシー保護の観点からも最強のソリューションとなる。これは、Appleが推進する「Apple Intelligence」の方向性とも完全に合致しており、今後のモバイルAIの標準となるだろう。
SnapのAR戦略との融合
Snapにとって、この技術は同社のコアビジネスであるAR(拡張現実)と密接に関わる。同社が開発するARグラス「Spectacles」において、目の前の現実にリアルタイムでAI生成オブジェクトを重ね合わせるためには、低遅延かつ低消費電力な生成モデルが不可欠だ。SnapGen++は、スマホだけでなく、将来的にはスマートグラス上で動作する基盤技術となる可能性が高い。
「量より質」のエンジニアリング競争へ
長らく続いた「パラメータ数競争」は、ここで一つの転換点を迎えた。GoogleやOpenAI、Metaといった巨人は、単にモデルを大きくするのではなく、「いかに小さく、賢くするか」という高密度化の競争(Dense Intelligence)にリソースを集中せざるを得なくなるだろう。半導体業界においても、メモリ帯域幅に依存する巨大モデル向けチップだけでなく、こうした軽量モデルを高速に回すNPU(Neural Processing Unit)の重要性がさらに増すことになる。
ポケットの中のスーパーコンピューター
SnapGen++が示した事実は衝撃的だ。我々が「サーバーグレードのGPUが必要だ」と思い込んでいた処理の多くは、実はアルゴリズムの最適化不足による贅肉だったのかもしれない。
iPhoneの画面上で、わずか1.8秒で生成される高精細な画像。それは、クラウドの向こう側にあった「知能」が、物理的に我々の手元へと降りてきた瞬間である。SnapGen++は、AIの民主化を加速させ、クリエイティビティの場所を「接続された端末」から「あらゆるエッジデバイス」へと拡張する、真のゲームチェンジャーとなるだろう。
論文
参考文献