

人工知能(AI)技術の急速な発展に伴い、高性能なハードウェアへの需要が急増している。この状況下で、AMDが新たな一手を打った。同社は2024年10月11日、サンフランシスコで開催された「Advancing AI」イベントにおいて、次世代AI GPUアクセラレーター「Instinct MI325X」および「Instinct MI355X」を発表した。これらの新製品は、AIワークロード処理の高速化と効率化を目指すAMDの野心的な戦略の一環であり、業界大手NVIDIAに対する明確な挑戦状となっている。
AMDのAI戦略の核心
AMDのCEO、Lisa Su氏は、イベントの基調講演で「我々の目標は、AMDをエンド・ツー・エンドのAIリーダーにすることです」と宣言した。この野心的な目標を達成するため、AMDは高性能なAIアクセラレーターの開発に注力している。
Instinct MI325XとMI355Xは、それぞれ異なるタイムラインで市場に投入される予定だ。MI325Xは2024年第4四半期に生産を開始し、2025年第1四半期には主要サーバーメーカーから製品が出荷される見込みである。一方、MI355Xは2025年後半の出荷を目指している。
これらの新製品は、AMDが急速に成長するAIインフラ市場で存在感を高めるための重要な布石となる。同社は既に、データセンターチップ市場の34%のシェアを獲得していることを報告しており、この新たな製品ラインナップによって、さらなる成長を見込んでいる。
AMDの攻勢は、Microsoft、Meta Platforms、Databricks、Oracleなどの大手テクノロジー企業や、Reka AI、Essential AI Labs、Fireworks AI、Luma AIといった新興企業からの支持を得ている。これは、AMDの技術力と市場戦略が業界全体から評価されている証左といえるだろう。
Instinct MI325X:AMDの次世代AIアクセラレーター

AMDのInstinct MI325Xは、同社のCDNA 3アーキテクチャを基盤とする最新のAI GPUアクセラレーターだ。この新製品は、前世代のMI300Xの基本設計を踏襲しつつ、メモリ容量と帯域幅を大幅に向上させている。
HBM3e採用により大きく向上したメモリ性能
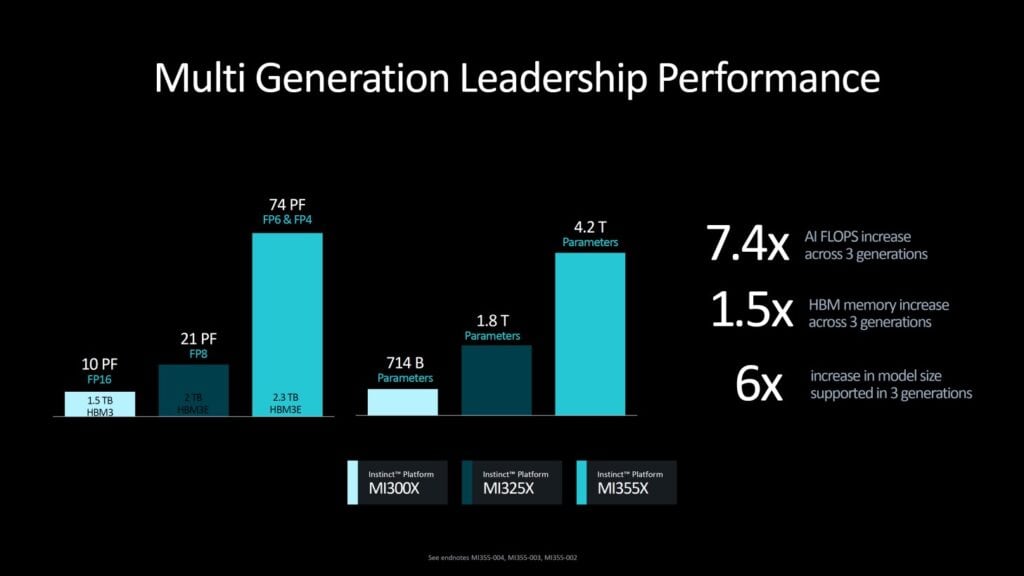
MI325Xの最大の特徴は、その圧倒的なメモリ性能にある。本製品は256GBのHBM3e(High Bandwidth Memory 3e)メモリを搭載しており、これは競合製品であるNVIDIA H200の192GBを大きく上回る。また、メモリ帯域幅も6TB/秒に達し、MI300Xの5.3TB/秒から約13%の向上を実現している。

AMDのGPUプラットフォーム部門バイスプレジデントであるBrad McCredie氏は、「MI325Xは、AI推論と学習ワークロードにおいて、MI300Xの2倍以上の性能を発揮します」と述べている。
計算性能と電力効率
計算性能に関しては、MI325XはFP16(16ビット浮動小数点)演算で1.3ペタフロップス、FP8(8ビット浮動小数点)演算で2.6ペタフロップスの性能を誇る。これらの数値は、前世代のMI300Xと同等であるが、より大容量かつ高速なメモリとの組み合わせにより、実際のAIワークロードではさらなる性能向上が期待できる。
一方で、MI325Xの消費電力は最大1000ワットに達し、MI300Xの750ワットから大幅に増加している。この電力増加は、主に高性能なHBM3eメモリの採用によるものと考えられる。
NVIDIA H200との性能比較

AMDは、MI325XがNVIDIA H200と比較して、特定のAIワークロードで優位性を持つと主張している。具体的には、以下のような性能差を示している:
- Mixtral 8x7Bモデルで40%高速
- Mistral 7Bモデルで30%高速
- Meta Llama 3.1 70Bモデルで20%高速
さらに、8基のMI325Xを搭載したプラットフォームでは、Llama 3.1 405Bモデルで40%、70Bモデルの推論テストで20%の性能優位性があるとしている。
市場投入時期と採用メーカー
AMDは、Instinct MI325Xの量産を2024年第4四半期に開始し、2025年第1四半期には主要サーバーメーカーからの製品出荷を予定している。Dell Technologies、Hewlett Packard Enterprise、Lenovo、Gigabyte Technology、Super Micro Computerなどの大手メーカーが、MI325Xを搭載したサーバーソリューションの提供を計画している。

MI325Xの登場により、AMDはAI市場における競争力を一段と強化することになる。
Instinct MI355X:AMDの次なる一手

AMDは、Instinct MI325Xの発表と同時に、次世代製品となるInstinct MI355Xの概要も明らかにした。この新製品は、AMDのAI戦略における重要な一歩となる見込みだ。
CDNA 4アーキテクチャの採用

MI355XはAMDの新しいCDNA 4アーキテクチャを採用する。AMDのデータセンターGPU部門バイスプレジデントであるAndrew Dieckmann氏は、CDNA 4を「ゼロから再設計されたアーキテクチャ」と表現している。この新アーキテクチャは、台湾TSMCの最新3nmプロセスノードを使用して製造される予定だ。
驚異的な性能向上
AMDは、MI355Xが前世代のMI325Xと比較して、以下のような性能向上を実現すると予告している:
- FP16演算性能:2.3ペタフロップス(約77%向上)
- FP8演算性能:4.6ペタフロップス(約77%向上)
- 新たにFP4およびFP6データ型をサポートし、最大9.2ペタフロップスの演算性能を実現

特筆すべきは、FP4演算性能が9.2ペタフロップスに達する点だ。これは、NVIDIAの次世代GPUであるBlackwell B200の9ペタフロップスとほぼ同等の性能である。
メモリ性能の更なる向上

MI355Xは、MI325Xの256GBをさらに上回る288GBのHBM3eメモリを搭載する予定だ。これは、現在のNVIDIAの製品ラインナップと比較して50%多いメモリ容量となる。また、メモリ帯域幅も8TB/秒に向上し、Blackwellと同等の性能を実現する見込みだ。
システムレベルでの性能
8基のMI355X GPUを搭載したノードでは、以下のような性能が期待できる:
- 合計2.3TBのHBMメモリ
- 最大74ペタフロップスのFP4演算性能
AMDによれば、この構成で約42億パラメータのAIモデルをFP4精度で1台のサーバーに収めることが可能になるという。
市場投入時期

AMDは、Instinct MI355Xを2025年後半に出荷開始する予定だ。これにより、NVIDIAのBlackwellシリーズと直接競合することになる。
MI355Xの発表は、AMDのAI市場における野心を示すものだが、いくつかの技術的課題も存在する。特に、複数のGPU間の相互接続技術や、大規模なAIモデルのスケーリングに関する詳細はまだ明らかにされていない。これらの要素は、実際のAIワークロードの性能に大きな影響を与える可能性がある。
NVIDIAは、Blackwellの発表時にGPU間の相互接続技術について詳細な説明を行っており、この分野でのリードを維持している。AMDがMI355Xで同等以上の相互接続性能を実現できるかどうかは、製品の成功を左右する重要な要素となるだろう。
AMDは、MI355Xの開発を通じて、AIワークロードに特化した新しいデータ型や最適化技術の導入を進めている。これらの技術革新が、実際のAI開発や運用にどのような影響を与えるかは、業界全体から注目されている。
AMDの新ネットワーキング技術:AIクラスターの性能を最大化
AMDは、AI向けGPUアクセラレーターの発表と同時に、次世代のネットワーキング技術も公開した。これらの技術は、AI処理の高速化と効率化に不可欠な要素となる。
Pensando Pollara 400:Ultra Ethernet規格に対応した世界初のNIC

AMDは、Pensando Pollara 400を2025年前半に発売する予定だ。これは、Ultra Ethernet Consortium(UEC)の規格に対応した世界初のネットワークインターフェースカード(NIC)となる。
Pollara 400の主な特徴:
- 単一の400GbEインターフェースを搭載
- パケットスプレーイングや輻輳制御技術を実装し、InfiniBandに匹敵する低遅延と低損失を実現
- プログラマブルなP4エンジンを採用し、進化するUEC規格に柔軟に対応可能
AMDのNetwork Technology and Solutions GroupのシニアバイスプレジデントであるSoni Jiandani氏は、ネットワーキングの重要性について次のように述べている:「バックエンドネットワークがAIシステムの性能を左右します。Metaによると、一般的にトレーニングサイクル時間の30%がネットワーキングの待機時間に費やされています。そのため、ネットワーキングはAI性能を向上させる上で不可欠かつ基礎的な要素なのです。」
Pollara 400の大きな利点は、NVIDIAのSpectrum-Xイーサネットネットワーキングプラットフォームとは異なり、超低損失ネットワーキングを実現するために互換性のあるスイッチを必要としない点だ。これにより、導入の柔軟性が高まり、既存のインフラストラクチャとの統合が容易になる。
Pensando Salina:フロントエンドネットワーク用DPU

AMDはまた、Pensando Salinaというデータプロセシングユニット(DPU)も発表した。Salinaの主な特徴は以下の通りだ:
- デュアル400GbEインターフェースを搭載
- フロントエンドネットワークのサービスを担当
- ソフトウェア定義ネットワーキング、セキュリティ、ストレージ、管理機能をCPUからオフロード
SalinaとPollara 400は、AIクラスター内でそれぞれ異なる役割を果たす。Salinaはフロントエンドネットワークを担当し、ユーザーからのデータ入力やリクエストを処理する。一方、Pollara 400は、バックエンドネットワークで複数のGPUノード間の高速なデータ転送を可能にする。
ネットワーキング技術の重要性
IDCのアナリスト、Brandon Hoff氏は、AIワークロードにおけるネットワーキングの重要性を次のように説明している:「AIワークロード、特に生成AIワークロードは、サーバーノード内のすべての計算、メモリ、ストレージ、ネットワーキングリソースを消費する最初のワークロードです。また、AIは単一のAIファクトリーノードを超えてスケールするため、すべてのGPUが相互に通信する必要があります」。Hoff氏はさらに、「AIファクトリーノード間の通信時間は’ネットワーク内時間’と呼ばれ、トレーニングやマルチノード推論AIの実行時間の最大60%を占める可能性があります。言い換えれば、ハイパースケーラーが10億ドルをGPUに費やした場合、4億ドル分の仕事しか行われず、6億ドル分のGPUがアイドル状態になってしまうのです。高性能ネットワーキングは不可欠であり、GPUに次いで2番目に重要な要素です」と、指摘している。
これらの新しいネットワーキング技術の導入により、AMDはAIインフラストラクチャ市場において総合的なソリューションを提供する能力を強化している。GPUアクセラレーターとネットワーキング技術の緊密な統合は、AIワークロードの処理効率を大幅に向上させ、AMDの競争力を高めることが期待される。
AI市場におけるAMDの戦略と展望
AMDの一連の新製品発表は、同社がAI市場において積極的な攻勢に出ていることを明確に示している。高性能なGPUアクセラレーターと先進的なネットワーキング技術を組み合わせることで、AMDはAIワークロード全体を最適化する総合的なソリューションの提供を目指している。この戦略により、エンド・ツー・エンドの性能最適化が可能となり、導入の容易さと潜在的なコスト効率の向上が期待される。
AMDの新製品は、AI市場で圧倒的なシェアを持つNVIDIAに対する直接的な挑戦となる。両社の競争は技術革新の加速、価格競争の可能性、そしてAI関連のソフトウェアやツールの選択肢拡大につながる可能性がある。しかし、Creative Strategies社のCEOであるBen Bajarin氏は、「AMDはデータセンター市場で依然として優位な立場にありますが、AI加速とGPU市場ではNVIDIAが依然として優位にあり、それは近い将来変わる可能性は低いでしょう」と分析している。
AI市場は急速に拡大しており、IDCの予測によると、2027年までに全世界のAIソフトウェア、ハードウェア、サービス市場が5,800億ドルに達するとされている。この成長市場において、AMDには大きな機会が存在する。Microsoft、Meta、Oracleなどの大手クラウドプロバイダーとの関係を活かした市場シェアの拡大、Instinct GPUの技術をエッジデバイスに適用した新たな市場の開拓、そしてROCmソフトウェアスタックの継続的な改善による開発者コミュニティの拡大などが考えられる。
しかし、AMDが今後AI市場でさらなる成功を収めるためには、いくつかの課題に取り組む必要がある。NVIDIAのCUDAに匹敵する開発環境とライブラリの整備、ChatGPTやGPT-4のような大規模言語モデル(LLM)に対する最適化、そしてTSMCの先端プロセスノードの生産能力確保による需要に応じた供給の実現が重要となる。
AMDのCEO、Lisa Su氏は、「我々は長期的な視点でAI市場に取り組んでいます。継続的な技術革新と顧客との緊密な協力により、AIの可能性を最大限に引き出すソリューションを提供していきます」と述べている。この姿勢は、AMDが短期的な成果だけでなく、持続可能な成長と技術革新を重視していることを示している。
AMDの新製品と戦略は、AI市場に新たな競争をもたらし、業界全体の技術革新を加速させる可能性がある。クラウドプロバイダーや企業のAI導入が進む中、AMDがどのように市場シェアを拡大し、NVIDIAとの差を縮めていくか、そして両社の競争がAI技術の発展にどのような影響を与えるか、今後の市場動向と技術の進化に大きな注目が集まっている。










コメント