

PCのTOPS競争が過熱している。先日のQualcommのSnapdragon X、そして昨日のAMD「Ryzen AI 300」に続き、Intelは本日「Lunar Lake」SoCの詳細を明らかにし、AI PC開発競争に本格的に参加する。だが、AI PCと言う面だけ見れば、Lunar Lakeに搭載されるNPU(Neural processing unit)は48TOPSのAIパフォーマンスを誇ると言い、AMDのRyzen AI 300が主張する50TOPSには少し及ばない。
ノートPC・モバイル向けSoCであるLunar Lakeは、昨年のMeteor Lakeをベースに電力効率の向上と全体的なパフォーマンスの最適化に焦点を当てて開発された。
Lunar Lakeは、高度なスケジューリング・メカニズムを活用することで、ワークロードの需要に基づいてタスクを効率的なコア(Eコア)またはパフォーマンス・コア(Pコア)に動的に割り当て、最適な電力使用とパフォーマンスを確保するように割り当てられる。このプロセスでは、Windows 11とともにIntel Thread Directorが重要な役割を果たし、ワークロードの強度に応じて効率と計算能力のバランスをリアルタイムで調整するようにOSスケジューラを導くという。
ここで注目すべきは、これまでIntelのCPUで象徴的だったハイパースレッディング(HT)が廃止されたことだ。HTは1つのCPUコア上で複数のスレッドの実行を可能にする機能で、多くの作業を同時進行で行うことが可能なものだが、Lunar Lakeからはこの機能が廃止される。(AMDは同様な機能をまだ継続するようだ)
理由は複雑だが、Intel曰く“不要だから”とのことで、Lunar LakeシリーズのPコアは、HTのマルチスレッド処理を無効にしても、前世代のMeteor Lake CPUの同じコアより14%高速とのことだ。これについては後述する。
| Alder/Raptor Lake | Meteor Lake | Lunar Lake | Arrow Lake | Panther Lake | |
|---|---|---|---|---|---|
| Pコアアーキテクチャ | Golden Cove/Raptor Cove | Redwood Cove | Lion Cove | Lion Cove | Cougar Cove? |
| Eコアアーキテクチャ | Gracemont | Crestmont | Skymont | Crestmont? | Darkmont? |
| GPUアーキテクチャ | Xe-LP | Xe-LPG | Xe2 | Xe2? | ? |
| NPUアーキテクチャ | N/A | NPU 3720 | NPU 4 | ? | ? |
| アクティブタイル | 1 (モノリシック) | 4 | 2 | 4? | ? |
| 製造プロセス | Intel 7 | Intel 4 + TSMC N6 + TSMC N5 | TSMC N3B + TSMC N6 | Intel 20A + その他 | Intel 18A |
| セグメント | モバイル + デスクトップ | モバイル | LP モバイル | HP モバイル + デスクトップ | モバイル? |
| 発売日 (OEM) | 2021年第4四半期 | 2023年第4四半期 | 2024年第3四半期 | 2024年第4四半期 | 2025 |
Lunar Lakeの概要
IntelのLunar Lakeは、Intelが“タイル”と呼ぶ様々な機能を持たせたチップを組み合わせたチップレット設計だ。
Lunar Lakeで特筆すべきは、このタイル全てをIntel自身が製造していない初めてのSoCとなることだろう。

Lunar LakeのPコアとEコアを含むコンピュート・タイル全体はTSMCのN3Bノードで製造され、SoCタイルはTSMCのN6ノードで製造される。2023年9月の発表では、これはIntel 18Aプロセスで製造され、GAAトランジスタであるRibbonFETとBSPDNのPowerViaが採用されるとされていたが、そのどちらも実現していない点から、Intelの開発が予定通り進んでいない可能性も考えられそうだ。

ただし、パッケージングに関してはIntelの技術が活きている。Foverosパッケージング技術が使用され、コンピュート・タイルとSoC(現在は「プラットフォーム・コントローラー」)タイルの両方がベース・タイルの上に配置され、タイル間の高速/低消費電力ルーティングを提供し、さらにチップの残りの部分やそれ以上への接続性を提供している。
ユーザーにとってそれ以上に重要なことは、Lunar Lake搭載PCはMacBookのようにユーザー自身でメモリの交換が出来なくなったことだろう。つまりLunar Lakeプラットフォームは、チップ・パッケージ自体に最大32GBのLPDDR5Xメモリを搭載されるのだ。LPDDR5Xメモリは、64ビットのメモリチップがペアで配置され、合計128ビットのメモリバス幅を提供する。そういうわけで、Lunar Lakeのメモリ構成は最終的に、IntelがどのSKUを出荷するかによって決定されることになる。

そして、これからの注目であるAI機能に関して、Lunar Lakeには「NPU 4」と呼ばれる新たなNPUが統合されている。NPU 4はINT8で最大48TOPSの性能を発揮し、Microsoftが定める「Copilot+ PC」の基準に対応する。
Lunar Lakeにはまた新たな統合GPUも搭載された。「Xe2」iGPUは67TOPSのAI性能と、Meteor Lakeの1.5倍のグラフィック性能を誇る。強化された XeSS カーネルにより、グラフィックスと計算パフォーマンスも向上している。
NPUやCPU、GPUを組み合わせたシステム全体のチップ性能としては、IntelはLunar Lakeは最高で120TOPSを実現すると述べている。
新たなパフォーマンスコア「Lion Cove」

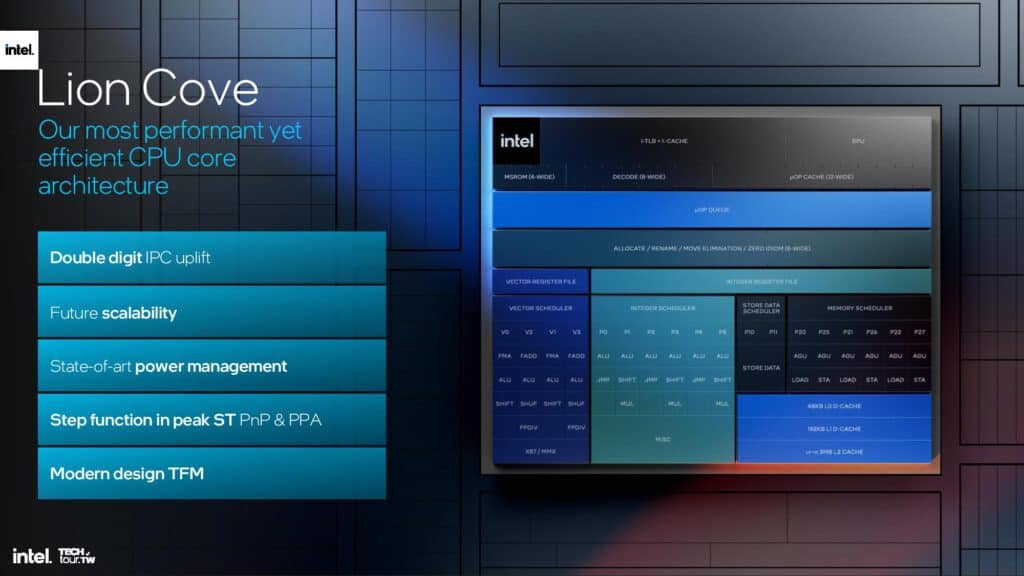
IntelがLunar Lakeで刷新したパフォーマンスコア(Pコア)には、新たに「Lion Cove」と呼ばれるアーキテクチャーが採用された。
Lion Coveでは、IPC(サイクル毎の命令実行数)が平均14%向上されており、大きな性能向上を果たしている。Intelはハイブリッド・アーキテクチャ用にコアを最適化する際に、ハイパースレッディング(HT)とその性能向上機能を実現するすべてのロジック・ブロックを削除するという大胆な決断に至った様だ。

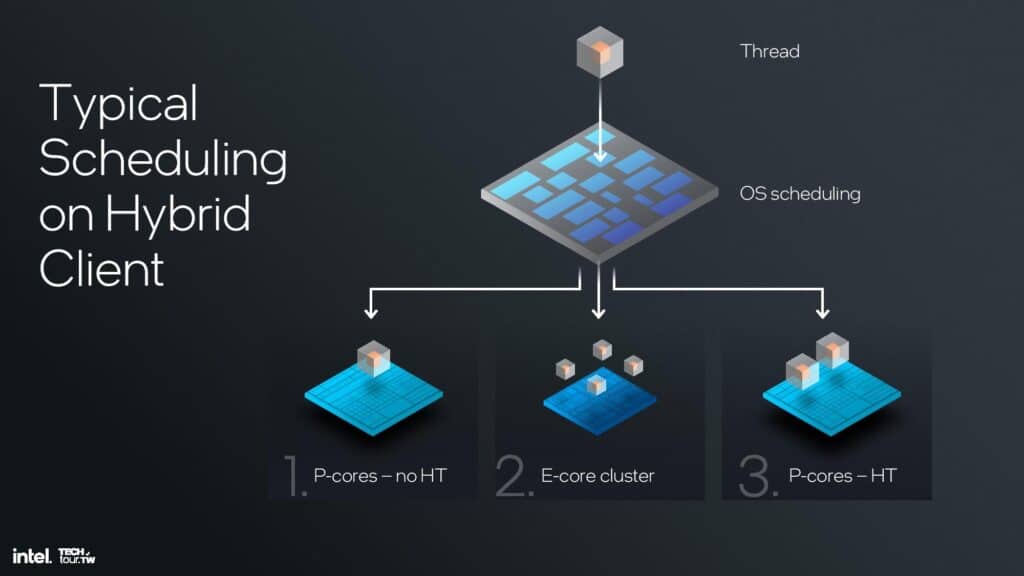
Intelのアーキテクトは、スレッドを多用するワークロードでIPCを約30%向上させるHTは、スレッドを多用するワークロードでより電力効率と面積効率の高いEコアを活用するハイブリッド設計ではそれほど意味がないと結論づけた。実際、スレッドは通常、コア上の余分なスレッドを活用することなく、まずすべてのPコアにスケジューリングされ、その後、追加のスレッドがEコアにスピルオーバーする。Eコアが飽和して初めて、Pコアで利用可能な余剰スレッドに追加スレッドがスケジューリングされ始めるのだ。
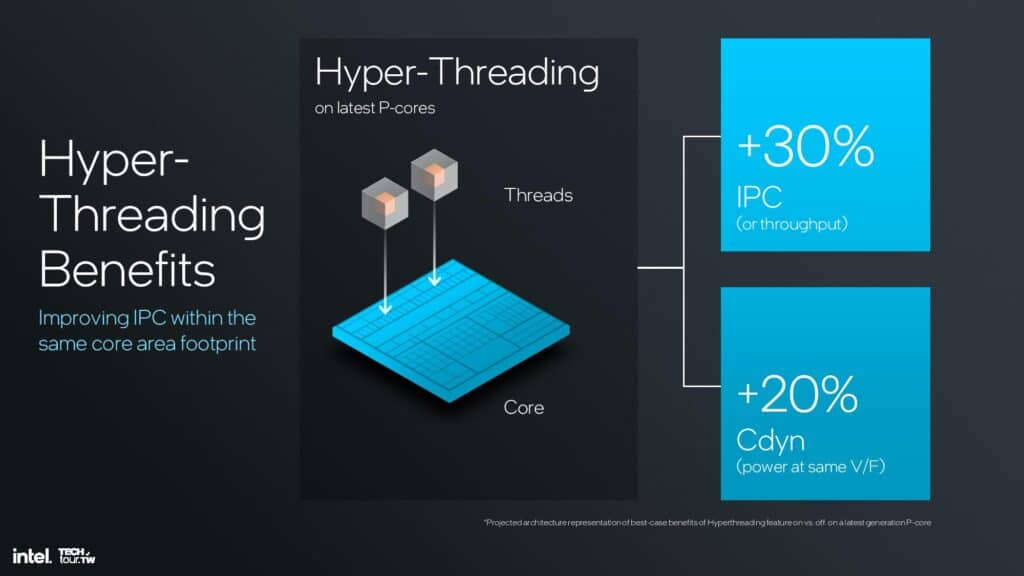

HTに必要な専用の公平性メカニズムと余分なセキュリティ機能を削除することで、コアはよりスリムになり、性能効率が15%向上し、面積あたりの性能が10%向上し、面積あたりの電力あたりの性能が30%向上した。これは、制御回路を残したままHTを無効にするだけよりもはるかに効果的であった。また、この新しいアプローチは、EコアやGPUコアの増設など、他の添加物のためにダイ面積を確保するものである。
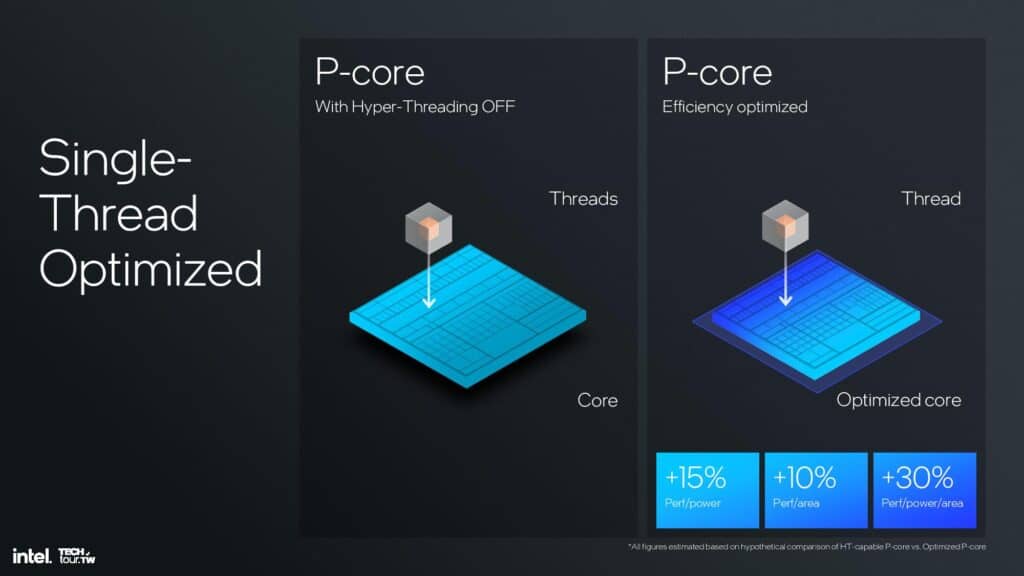
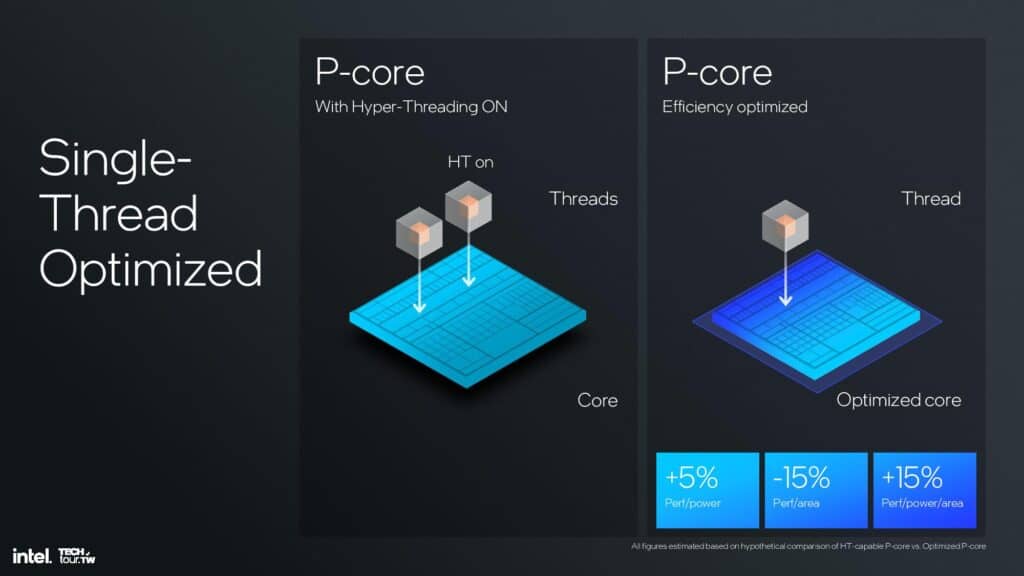
ただし、Intelは、すべてのユースケースでHTを廃止しているわけではなく、Pコアのみの設計にまだ大きな価値を見出している。そのため、IntelはLion CoveコアにHTありとなしの2つのバージョンを設計し、HTありのLion Coveコアを、近日発売のXeon 6プロセッサに見られるように、他のアプリケーションで使用できるようにしている。
また、Lion Coveは、さまざまな熱や電力のしきい値に対して電圧/周波数カーブ上の特定のポイントを割り当てるなど、さまざまな動作条件に対してあらかじめ定義された静的設定からの移行を意味する。現在では、よりインテリジェントな方法で動的に適応するために、AIセルフチューニングコントローラーが使用されている。クロック周波数も、以前は100MHz単位(ビン)でしか調整できなかったが、現在は16.67MHz単位で調整できるようになり、よりきめ細かな周波数と電力制御が可能になった。Intelはこれにより、シナリオによっては電力効率と性能のいずれかが1桁の割合で向上すると評価しており、効率優先のアーキテクチャではすべてのビットが重要であるとしている。

マイクロアーキテクチャのフロントエンドは、x86命令をフェッチし、マイクロオペレーションにデコードしてアウトオブオーダー実行エンジンに供給する。目標は、ストールを防ぐためにエンジンのアウトオブオーダー部分を飽和させることであり、そのためには高速で正確な分岐予測が必要である。


Intelによれば、精度を維持しながら、予測ブロックを従来の8倍に広げたという。Intelはまた、命令キャッシュからL2へのリクエスト帯域幅を3倍にし、命令フェッチ帯域幅を毎秒64バイトから128バイトに倍増させた。さらに、デコード帯域幅は1サイクルあたり6命令から8命令に増加し、マイクロオペ・キャッシュはリード帯域幅とともに増加した。マイクロオペキューも144エントリから192エントリに増加した。
以前のPコア・アーキテクチャでは、実行ポート間で命令をディスパッチするスケジューラが1つだったが、この設計ではハードウェアのオーバーヘッドとスケーラビリティの問題が生じていた。これらの問題に対処するため、Intelはアウトオブオーダーエンジンを整数ドメインとベクトルドメインに分割し、独立したリネーマーとスケジューラを備えることで柔軟性を高めた。また、リタイアメント、命令ウィンドウ、実行ポートにもさまざまな改良が加えられ、整数およびベクトル実行パイプラインにも改良が加えられた。


メモリサブシステムには新しいL0キャッシュレベルが追加された。アーキテクトはデータキャッシュを完全に再設計し、既存のL1キャッシュとL2キャッシュの間に192KBの階層を追加した。その結果、既存のL1の名前がL0に変更された。最終的に、これにより平均ロード・トゥ・ユーズ時間が短縮され、IPCが向上し、容量の増加によるレイテンシの犠牲なしにL2キャッシュ容量を増やすことが可能になっている。その結果、L2キャッシュはLunar Lakeで2.5MB、Arrow Lakeで3MBに増加した(どちらもPコアにはLion Coveを使用)。


Intelはまた、独自の設計ツールの使用から、その使用に最適化された業界標準のツールに切り替えた。Intelの旧アーキテクチャは、手作業で描かれた回路で構成される数万セルの「Fub(機能ブロック)」で設計されていたが、現在は数十万から数百万セルの大きな合成パーティションを使用するようになった。人工的な境界を取り除くことで、設計時間が短縮され、利用率が向上し、面積が削減される。
また、設計にコンフィギュレーション・ノブを追加することで、カスタマイズされたSoC固有の設計をより高速にスピンオフできるようになり、リード・アーキテクトは、これによりLunar LakeとArrow Lakeに使用されるコア間でより多くのカスタマイズが可能になったと述べている。この設計手法はまた、設計の99%を他のプロセス・ノードに移行可能にするものであり、intelの新アーキテクチャがプロセス・ノードの大幅な遅延によって遅れるという(例えば10nmのような)過去に見られたつまずきを防ぐ重要な進歩でもある。
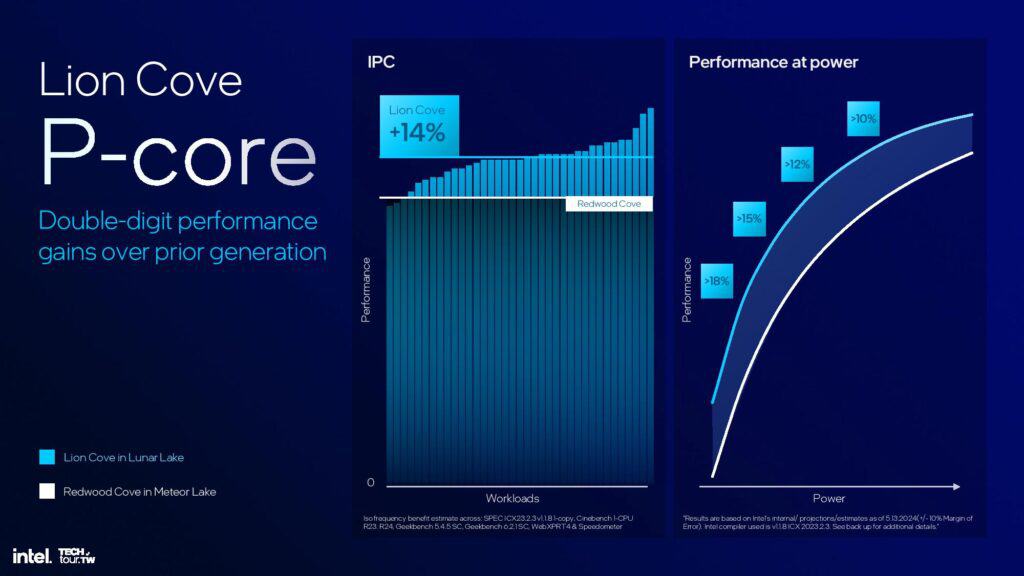
こうした変更により、Meteor Lakeで使用された前世代のRedwood Coveアーキテクチャと比較して、固定クロックレートでのIPCが14%向上した。Intelはまた、チップの動作電力に応じて、Meteor Lake比で10%から18%の全体的な性能向上も指摘している。注目すべきは、これらの消費電力と性能の向上は予測/推定に基づくものであるため、Intelは「消費電力時の性能」チャートの指標に±10%の誤差を与えていることだ。
高効率コア(Eコア)Skymontの性能向上は著しい

Lunar Lakeにおいて、Pコア以上に重要なのがEコアの「Skymont」だろう。

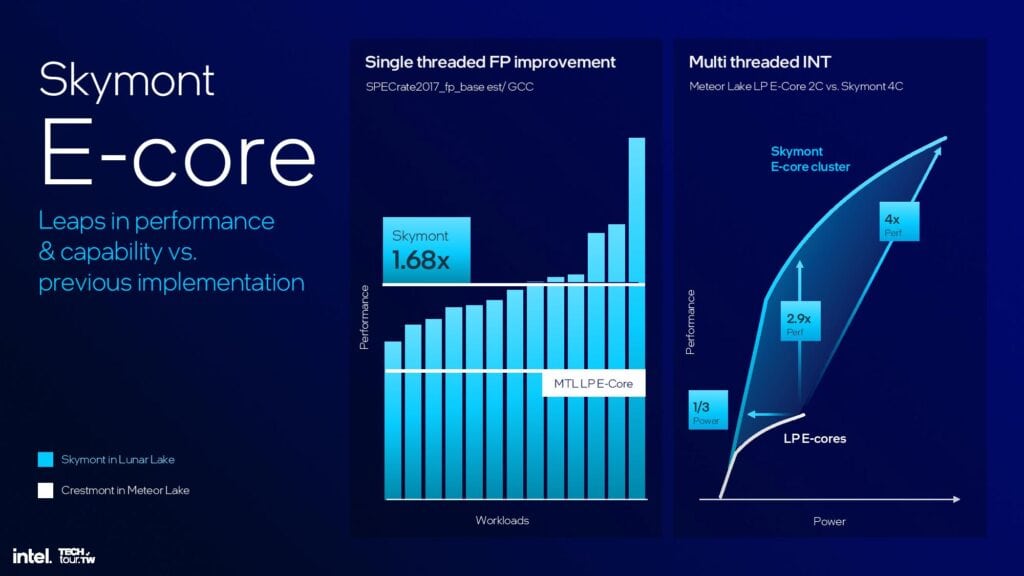
Pコア「Lion Cove」の14%のIPC向上も素晴らしいものではあるが、Skymontの整数演算でIPCが38%向上、浮動小数点演算でIPCが68%向上と言う性能向上は驚異的だ。これにより、Meteor Lake LP Eコアと比較して、シングルスレッド性能が最大2倍、マルチスレッドワークロードのピーク性能が最大4倍向上している。Intelはまた、ベクトル化AVXおよびVNNIワークロードのスループットも倍増させている。
Skymontアーキテクチャは、Alder LakeのGracemont、Meteor LakeのCrestmontに続く、Intelにとって3つ目のx86ハイブリッド・プロセッサ向けEコア設計となる。Meteor Lakeの設計では、極端な低消費電力ワークロード用にSoCタイルに2つのEコアを配置し、Pコアとともに4つのEコアをコンピュートタイルに追加していた。Lunar Lakeでは、Intelはコンピュート・タイル上に1つのクアッドコア・クラスターを採用し、ダイナミック・レンジを拡大することで、低消費電力のEコアと高出力のEコアの両方の役割に対応している。
Intelは、96命令バイトのパラレル・フェッチをデコード・エンジンに供給することで、分岐予測エンジンを最適化した。デコード・クラスタも、Crestmontの6ワイド(2×3)からSkymontの9ワイド(3×3)に拡張され、新しい設計ではどのコアも1クロックあたり9命令のデコードを維持できる。Skymontはまた、ナノコードを採用して並列マイクロコード生成を可能にし、3つのデコード・クラスタの並列実行頻度を高めている。また、フロントエンドとバックエンド間のバッファリングを増やすため、マイクロオペの容量も64エントリから96エントリに増加した。


Skymontのアウトオブオーダーエンジンのアロケーションは8ワイドで、Crestmontの6ワイドから増加した。また、Crestmontの8ワイドから倍増した16ワイドのリタイアに拡大し、ストール後に可能な限り早くリソースを解放することで、電力効率と面積効率を向上させている。アウトオブオーダーウィンドウは前世代より60%大きくなり、アーキテクチャはより大きなレジスタファイル、より深いリザベーションステーション、より深いロードバッファリングとストアバッファリングを備えている。並列性は、8つのALU、3つのジャンプ・ポートを含む26のディスパッチ・ポートを採用し、3ロード/サイクルをサポートすることで向上している。



Intelはベクター性能の2倍向上を目標としており、これは128ビットFPおよびSIMDベクターパイプを2本からSkymontでは4本にすることで実現した。ベクターエンジンに対するその他の改良点は、レイテンシの削減と浮動小数点丸め処理のサポートの追加である。Intelはまた、スライドに記載されているいくつかの機能強化により、ロード/ストアエンジンを強化した。
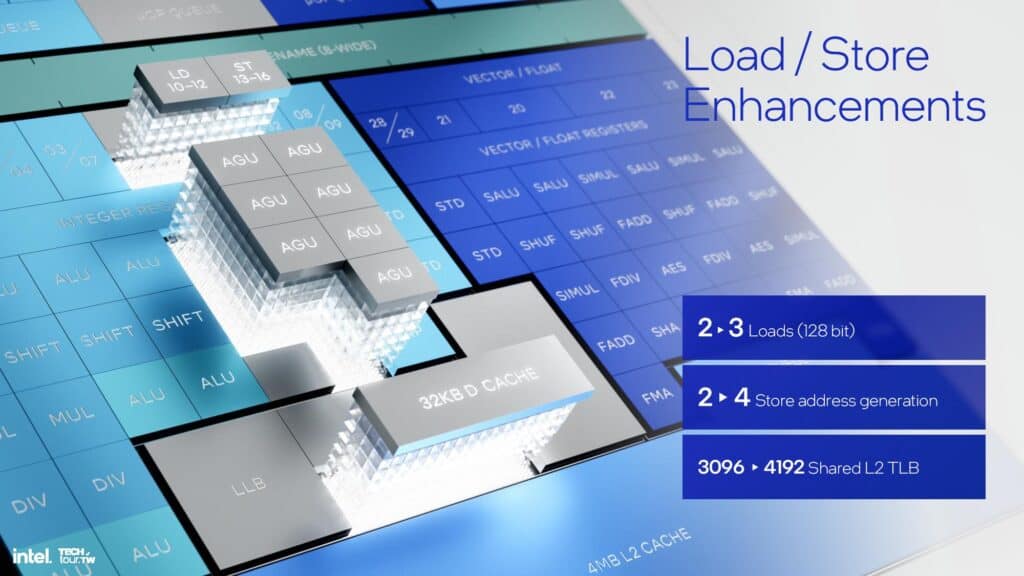

以前のEコア・クラスタは2MBのL2キャッシュを共有していたが、現在は4MBに拡張され、L2バンド幅は2倍になった。L1からL1への転送帯域幅も改善された。

最終的な結果は印象的で、前述のようにシングルスレッド整数演算性能で38%、浮動小数点演算性能で68%向上しているが、これはコンピュート・ダイ上の標準的なクアッドコア・クラスターではなく、Meteor Lake SoCの低消費電力eコアと比較したものである。
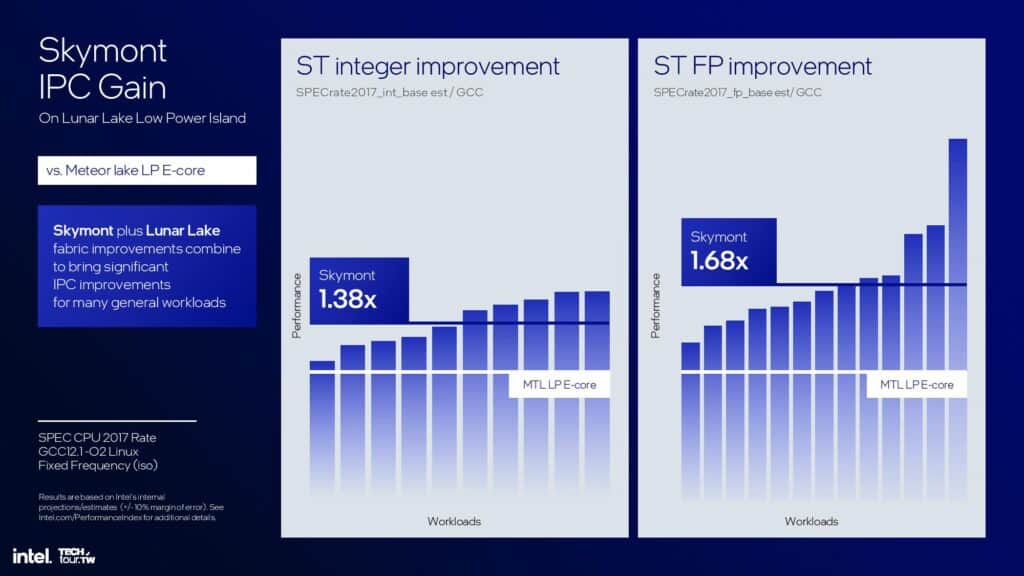
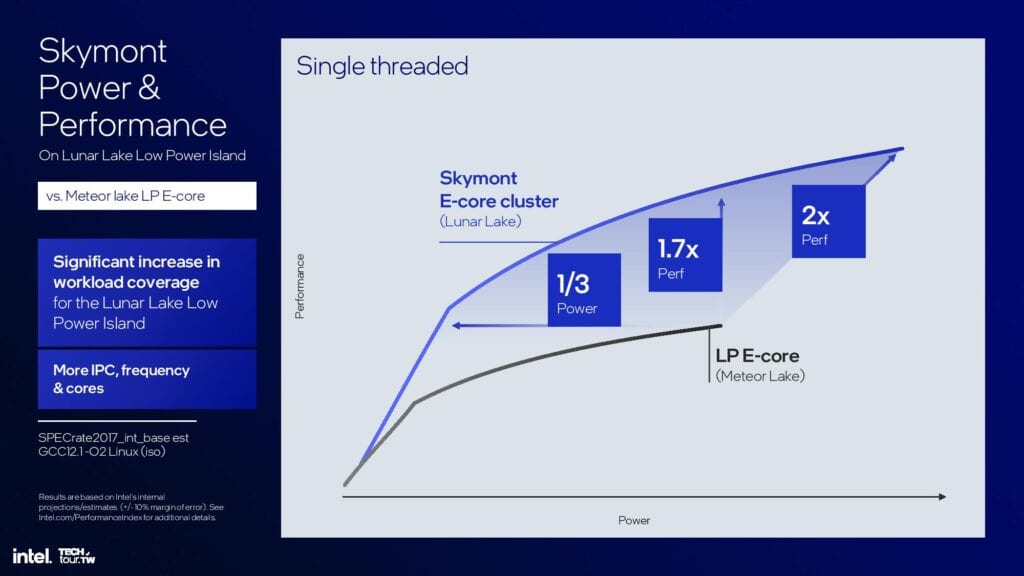
Skymontの消費電力とシングルスレッド性能曲線は、Crestmontよりも大幅に向上しているが、比較対象は今回もフルEコアではなく、低消費電力のMeteor Lake Eコアである。Crestmontのピーク性能と比較すると、Skymontは同レベルの性能を発揮するために3分の1の電力を消費する。しかし、同じ電力レベルで1.7倍の性能を発揮し、より多くの電力を消費している。全体として、Skymontのシングルスレッドのピーク性能は、Crestmont LP Eコアの2倍だ。
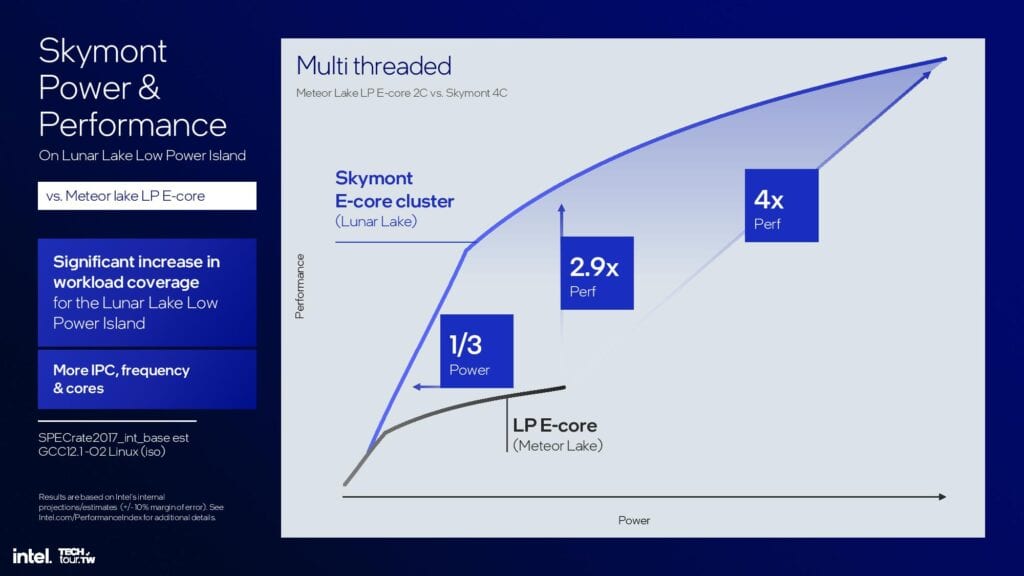
Intelは、SkymontのクアッドコアクラスターとMeteor Lakeのデュアルコア低電力Eコアクラスタを比較するのではなく、クアッドコアクラスターと比較しているため、マルチスレッドの消費電力/性能指標は少し不可解だ。そのため、これらの分野では、標準的なMeteor Lakeのクアッドコアクラスターと比較して、記載されている利点の半分が見られると予想される。
Intelはまた、Raptor Coveアーキテクチャを採用したSkymontとRaptor LakeのPコアの比較も行っている。Intelは、整数演算と浮動小数点演算でSkymontに2%の優位性があると主張している。
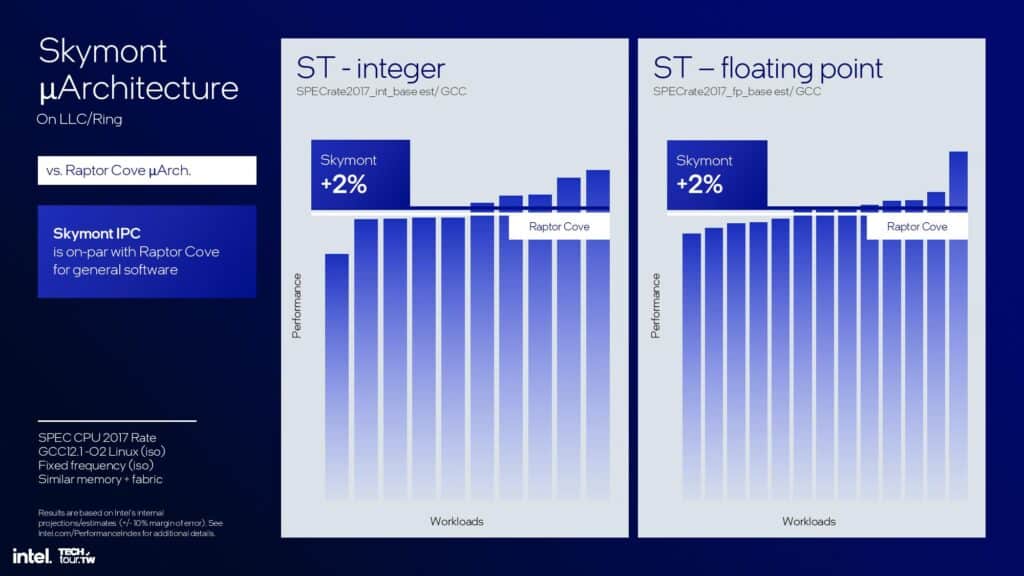
IntelがSkymontとRaptor Coveを比較した際の消費電力と性能のスライドは、誤解を招きやすい。最後の2つのスライドでは、Intelが低消費電力アイランドでのマルチスレッド・アクセラレーションに適切な電力エンベロープであるとする電力/性能曲線の領域を拡大していることがわかる。最後のスライドでは、SkymontはRaptor Coveと同じ性能で0.6倍の電力を消費し、同じ電力で1.2倍の性能を発揮するとしている。
48TOPSを誇る「NPU 4」
Intelは、「NPU 4」と名付けられた最新のNPUでいくつかの重要なブレークスルーを成し遂げた。AMDはComputexの基調講演で、より高速な50TOPSとなるNPUを公開したが、IntelはAIのピーク性能で最大48TOPSと主張している。NPU 4は、前モデルのNPU 3と比較して、ニューラル処理のパワーと効率を強化する上で大きな飛躍を遂げた。NPU 4の改良は、より高い周波数、より優れたパワー・アーキテクチャ、より多くのエンジンを実現することで可能となり、より優れた性能と効率を実現している。

NPU4では、これらの改良がベクトル性能アーキテクチャで強化され、計算タイルの数が増え、行列計算の最適性が向上した。これは、大量のニューラル処理帯域幅を発生させる。言い換えれば、超高速データ処理とリアルタイム推論を必要とするアプリケーションには不可欠だ。このアーキテクチャはINT8とFP16の精度をサポートし、INT8では1サイクルあたり最大2048回のMAC(乗積)演算、FP16では1024回のMAC演算が可能で、計算効率の大幅な向上を明確に示している。

アーキテクチャーをさらに詳しく見てみると、NPU 4ではレイヤー化が進んでいることがわかる。この第4バージョンのニューラル・コンピュート・エンジンにはそれぞれ、MACアレイと異なるタイプの演算に対応する多数の専用DSPからなる、非常に優れた推論パイプラインが組み込まれている。パイプラインは多数の並列演算のために構築されており、性能と効率を高めている。新しいSHAVE DSPは、前世代の4倍のベクトル計算能力に最適化されており、より複雑なニューラルネットワークを処理することができる。

NPU 4の大幅な改良点は、クロック速度の向上と、NPU 3と同じ電力レベルで性能を倍増させる新しいノードの導入である。この結果、ピーク性能は4倍となり、NPU 4は要求の厳しいAIアプリケーション向けの強力なプロセッサとなる。新しいMACアレイは、チップ上に高度なデータ変換機能を備えており、オンザフライでのデータ型変換、融合演算、最小のレイテンシでデータフローを最適化する出力データのレイアウトが可能だ。

NPU 4の帯域幅の向上は、特に変換言語モデルベースのアプリケーションで、より大きなモデルやデータセットを扱うために不可欠だ。このアーキテクチャは、より高いデータフローをサポートするため、ボトルネックを軽減し、稼働中でもスムーズに動作する。NPU 4のDMA(ダイレクトメモリアクセス)エンジンは、DMA帯域幅を2倍にする。これは、ネットワークのパフォーマンスを向上させ、重いニューラルネットワークモデルを効果的に処理するために不可欠な機能だ。トークン化の組み込みなど、さらに多くの機能がサポートされ、NPU 4でできることの可能性が広がっている。

NPU4の大幅な改良点は、行列乗算と畳み込み演算にあり、これによりMACアレイは、INT8では最大2048、FP16では最大1024のMAC演算を1サイクルで処理できる。これによりNPUは、より複雑なニューラルネットワーク計算を高速かつ低消費電力で処理できるようになる。NPU4は512ビット幅である。これは、1クロック・サイクルでより多くのベクトル演算ができることを意味し、ひいては計算の効率につながる。
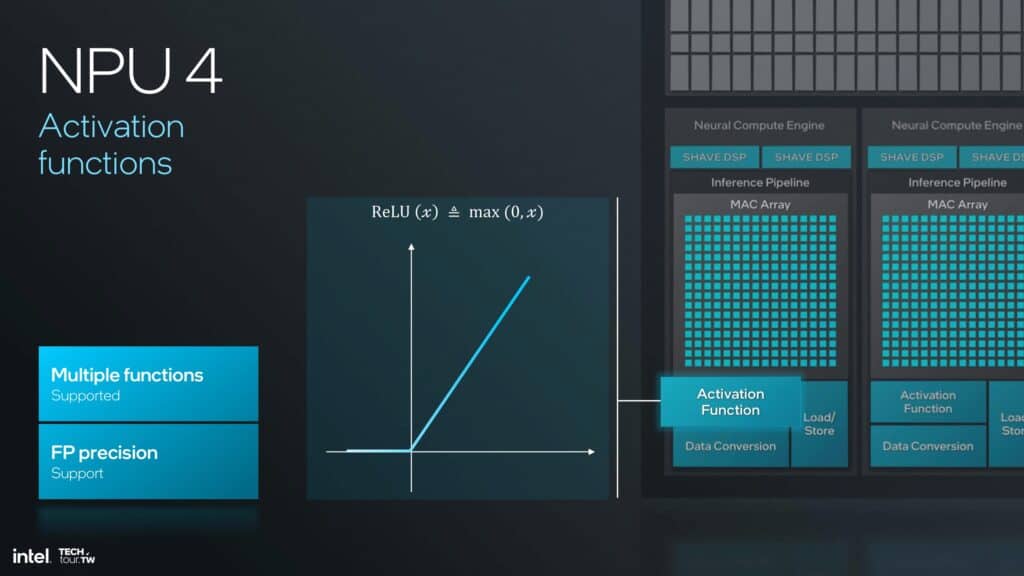
NPU 4は活性化関数をサポートし、浮動小数点演算をサポートするために精度を選択できるようになり、計算がより正確で信頼できるものになるはずだ。改良された活性化関数と推論のための最適化されたパイプラインは、より複雑で微妙なニューロネットワークモデルを、より優れたスピードと精度で実行する力を与えてくれるだろう。

NPU 4内のSHAVE DSPにアップグレードすることで、NPU 3と比較してベクトル演算能力が4倍になり、ベクトル性能全体が12倍向上する。これは、Transfomerと大規模言語モデル(LLM)の処理に最も有効で、より迅速でエネルギー効率が高くなる。クロックサイクルあたりのベクトル演算の増加は、より大きなベクトルレジスタファイルサイズを可能にし、NPU 4の計算能力を大幅に向上させる。
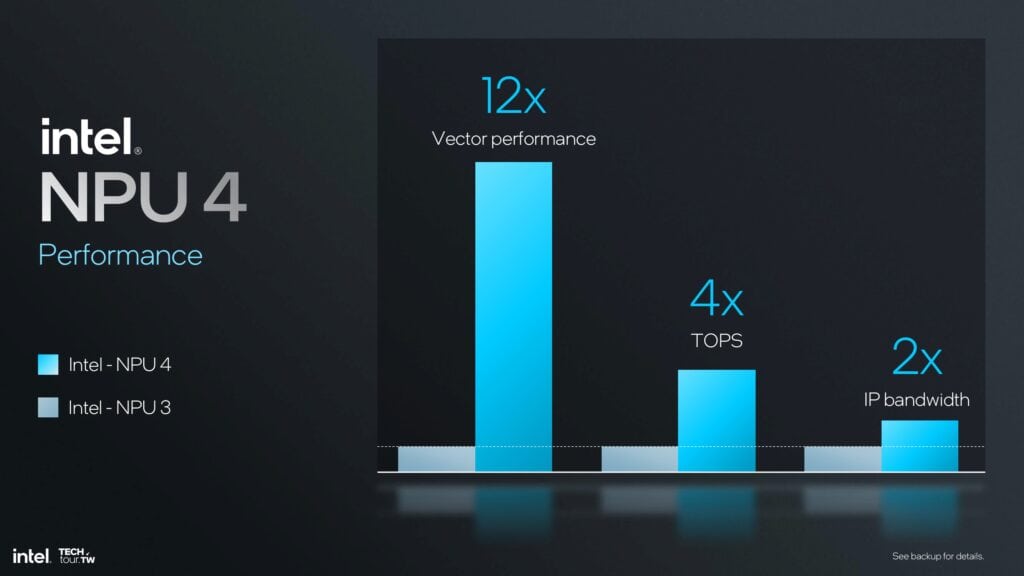
一般的に、NPU 4はNPU 3に比べて性能が大幅に向上しており、ベクトル性能は12倍、TOPSは4倍、IP帯域幅は2倍となっている。これらの改善により、NPU 4は、性能とレイテンシが重要となる最新のAIおよび機械学習アプリケーションに、高性能かつ効率的に適合する。これらのアーキテクチャの改善と、データ変換および帯域幅の改善により、NPU 4は、非常に要求の厳しいAIワークロードを管理するための最高級ソリューションとなっている。
第2世代統合GPU「Xe2 GPU」
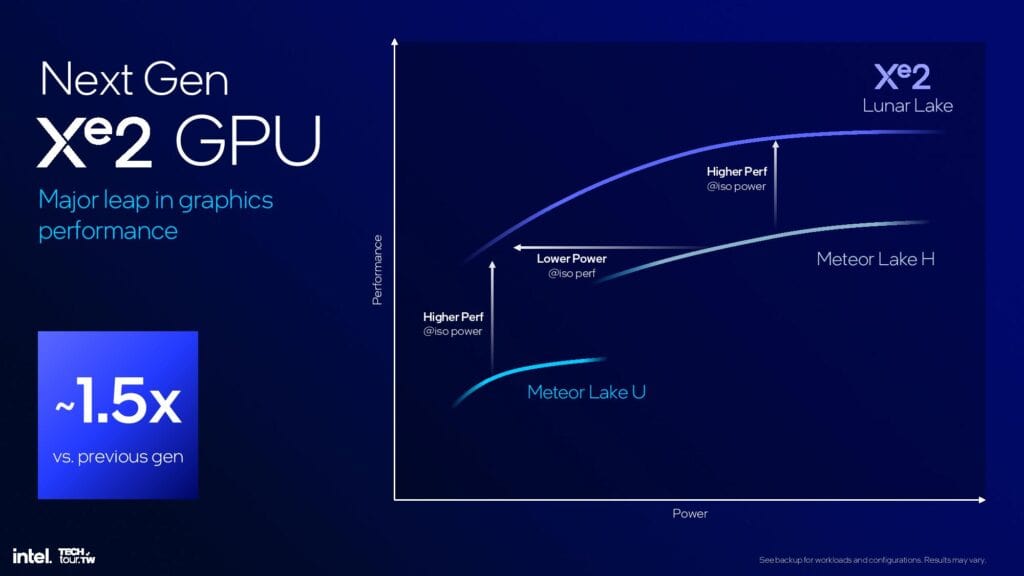
新しいXe2 iGPUは、Meteor LakeのArc Graphicsよりもグラフィックス性能が最大1.5倍向上し、AI性能は最大67TOPSとなる。今回、GPUアーキテクチャの名称が簡素化され、旧世代のXeアーキテクチャで使用されていたXe-LP、Xe-HP、Xe-HPGという接尾辞とは対照的に、すべての構成で単にXe2と呼称が改められた。
Intelの新たなXe2アーキテクチャは、Lunar Lakeプロセッサーに搭載されるだけでなく、今後発売されるBattlemageディスクリート・ゲーミングGPUにも採用される予定だ。しかし、アーキテクチャは同じでも、Lunar Lakeはより低消費電力のトランジスタを使用するのに対し、Battlemageはより高速のトランジスタを採用して性能を最大化する。つまり、Lunar Lakeの性能予測をそのままBattlemage GPUの性能予測に当てはめることはできない。

Intelが導入したXe2アーキテクチャは、Meteor LakeのXe-LPGと比較して、最大67のTOPを提供し、レイトレーシング・ユニットを増加させることで、計算能力を大幅に向上させる。Intelによると、第2世代XeコアはMeteor Lakeより1.5倍高速なグラフィックス性能を提供し、これは新しいXMXエンジンによって助けられ達成されている。強化されたXeSSカーネルは、グラフィックス性能と演算性能の向上を実現する。
Lunar LakeのXe2で大きな変更の1つが、より柔軟で高品質なディスプレイ出力を提供することだ。Displayエンジン内では、デュアルピクセルパイプラインのストリームを組み合わせてマルチストリームトランスポートを行うことができる。このアーキテクチャでは、ポートが4箇所に用意され、柔軟な接続が可能になる。Intelの構成では、eDPポートも提供され、ハイエンド、プレミアム、高性能ディスプレイの出力に高解像度とリフレッシュレートを設定するためにディスプレイを増強する。
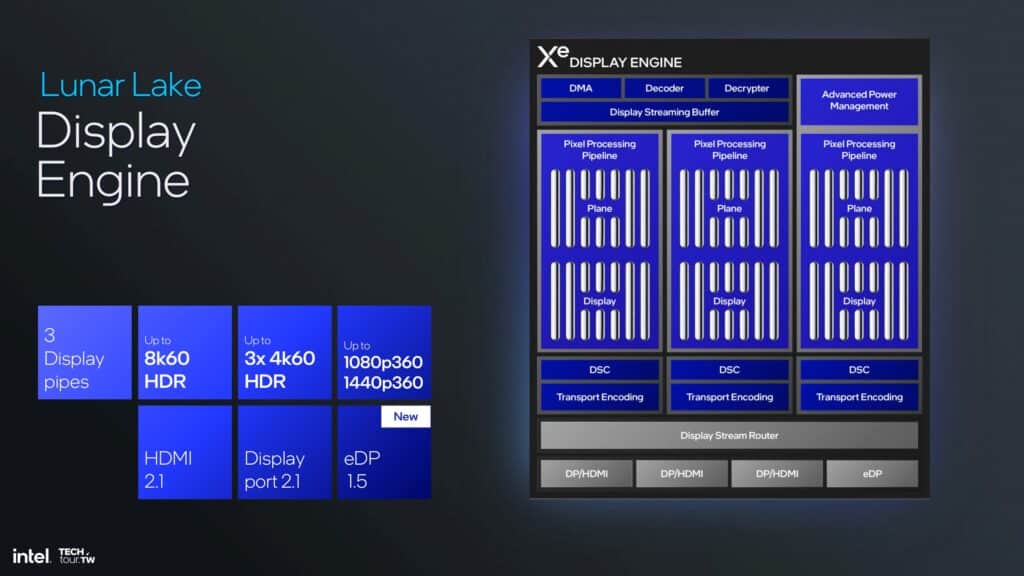
また、のeDisplayPort 1.5には、適応同期および選択的更新メカニズムに統合されたパネル再生機能が含まれている。これは、ディスプレイ全体ではなく、画面の変化する部分のみを更新することにより、消費電力を削減するのに役立つ。これらの技術革新は、エネルギーを節約するだけでなく、ディスプレイの遅延を減らし、同期の精度を高めることによって、視覚体験を向上させるという。

ピクセル処理パイプラインの描写は、Intelのディスプレイエンジンの基本的な基盤の1つであり、高度な色変換と合成のためにパイプラインごとに6つのプレーンを可能にする。さらに、カラーエンハンスメント、ディスプレイスケーリング、ピクセルチューニング、HDR知覚量子化のハードウェアサポートを統合し、スクリーン上のグラフィックスが鮮やかで正確であることを保証する。この設計は非常に柔軟で、電力効率に優れ、様々な入出力フォーマットに対応できるように設計されている。Intelは今のところ、定量化可能な電力指標、TDP、その他の電力要素を提示していない。
圧縮とエンコーディングを考慮すると、アーキテクチャXe2は、HDMIとDisplayPortプロトコルのトランスポートエンコーディングを含め、最大3:1のディスプレイストリーム圧縮を視覚的にロスレスで拡張する。これらのチップ機能は、データ負荷をさらに軽減し、ビジュアル品質を失うことなく出力時の高解像度を維持する。
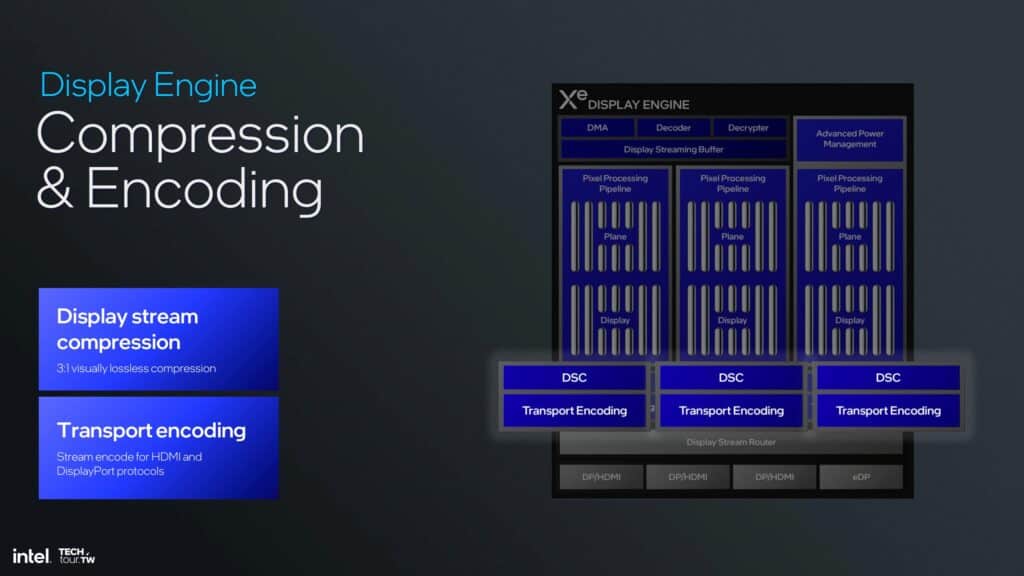
また、Lunar Lakeにおいて、IntelはVVCコーデックを採用した。このコーデックは、アダプティブ解像度ストリーミングと360度動画やパノラマ動画用の高度なコンテンツ・コーディングによってサポートされ、AV1と比較してファイルサイズを最大10%削減する。これにより、最新のマルチメディア・アプリケーションに不可欠な品質を損なうことなく、より低いビットレートでストリーミングが可能になる。

Intel Xe2と第2世代のArc Xeコアは、性能、効率、柔軟性を大幅に向上させるだろう。
I/O:Thunderbolt 4、Thunderbolt Share、Wi-Fi 7搭載
Lunar LakeのI/Oに関する主なハイライトには、ネイティブThunderbolt 4接続、新しいThunderbolt Share機能、Wi-Fi 7ワイヤレス接続へのアップグレードが含まれる。
Thunderbolt 4は、コントローラーの観点からは目新しいものではないが、接続性と帯域幅が強化されている。すべてのノートパソコンにThunderboltポートが3つ搭載できるようになったことで、この機能は非常に柔軟で使い勝手がよくなった。
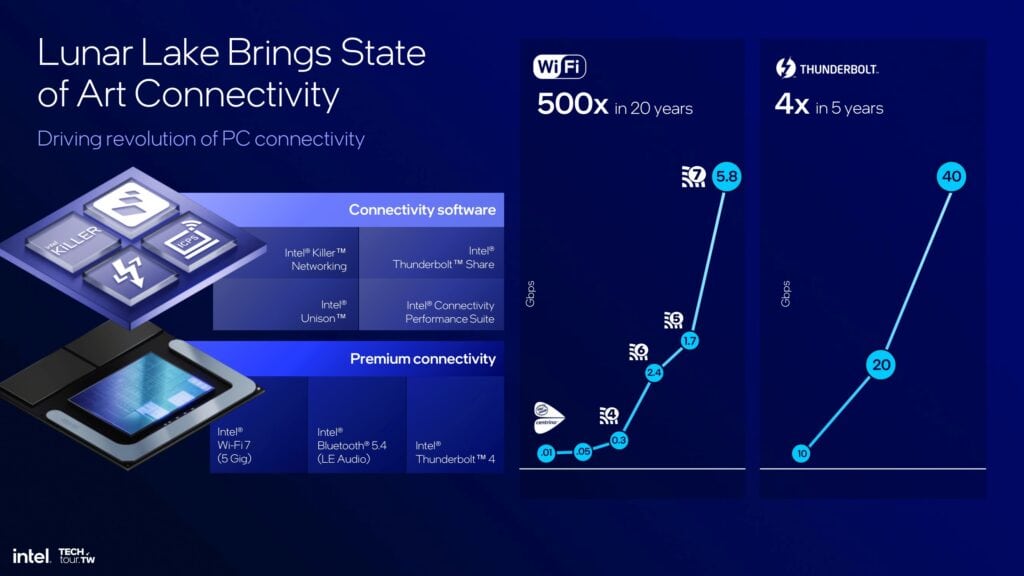
Thunderbolt 5 SSDのもう1つの改良点は、読み取り速度と書き込み速度が25%向上したことだ。これにより、全体的なデータ転送速度が向上し、ファイル転送にかかる時間が短縮される。これは、ビデオ編集や相当なサイズのファイルでの作業など、高いデータ転送速度を必要とするアプリケーションにとって重要なことで、ユーザーが作業中にラグを生じたり、最小限の速度で遅延したりすることがなくなる。

Thunderbolt Shareにより、複数のPCがシステム間でスクリーン、モニター、キーボード、マウス、ストレージを最大60フレーム/秒で簡単かつ高速に共有することができる。

特に、共同作業環境では、データの共有が簡単かつ迅速に行えるため、ワークフローが改善され、非常に重要である。生産性タスクにおけるこのユーティリティは、フォルダの同期を可能にし、PC間でのドラッグ・アンド・ドロップによる高速ファイル共有機能を備えている。

Wi-Fi 7はLunar Lakeプラットフォームにも統合されており、Meteor Lakeはワイヤレス接続の面で省略されている。このWi-Fi 7のマルチリンク動作機能は、ワイヤレス信号の整合性と信頼性を追加し、上記のすべてのリンクでパケットを複製することで、より少ないレイテンシでスループットを向上させる。これは、要求の厳しいアプリケーションにおいても、よりスムーズなパフォーマンスと優れた負荷分散を意味する。Wi-Fi 7の新機能による最大のメリットは、帯域幅を必要とするタスクを処理する際にユーザーにもたらされる。これは、ユーザーが安定した効果的なワイヤレス接続を行えるように設計されている。

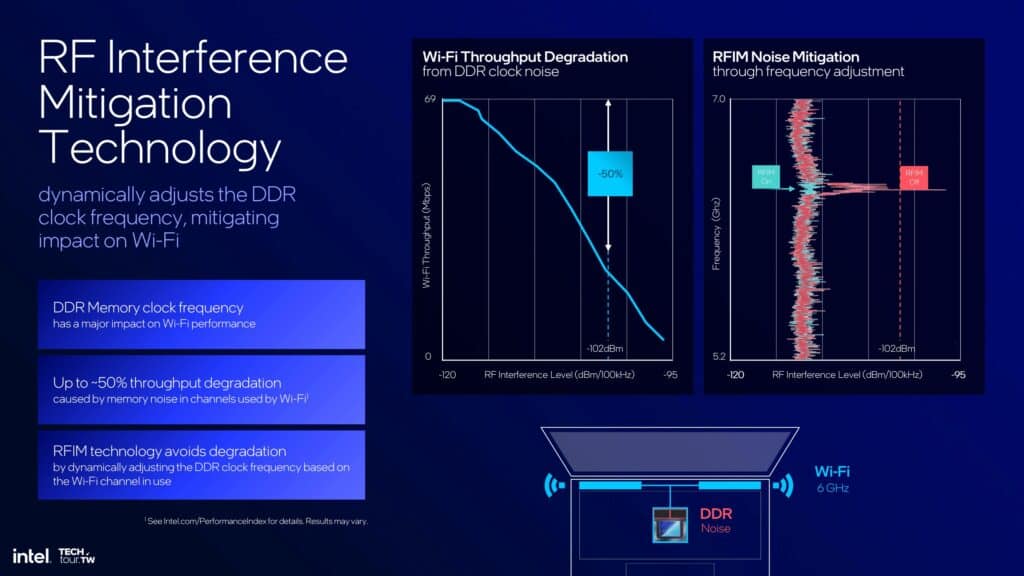
また、DDRクロック周波数がWi-Fi信号との干渉を最小限に抑えるように自動的に調整されるRF干渉緩和技術も搭載されている。この機能により、メモリ・ノイズによるスループット低下を50%削減できるため、理論的にはワイヤレス・ネットワーク全体のパフォーマンスを向上させることができる。ユーザーが期待できるもう一つのプラス効果は、非常に要求の厳しい環境であっても堅牢な接続性である。
IntelはMetaとの提携を勧めており、このWi-Fi 7テクノロジーを活用してVR体験を強化する。これにより、ビデオ遅延性能がさらに最適化され、干渉が低減されるため、少なくともワイヤレス接続の観点からは、VRアプリケーションがよりシームレスで魅力的なものになる。Wi-Fi 7の新たな機能強化は、VRアプリケーションにおける最も困難なニーズを満たすために、低遅延で信頼性の高い高速性を提供する。

Lunar Lakeに搭載される、Thunderbolt 4、Thunderbolt Share、Wi-Fi 7によって、Meteor Lakeから全面的なアップグレードが望める。これらのテクノロジーは、エンドユーザー体験を拡張・改善することを目的として、有線・無線接続の両方で速度と信頼性を向上させ、大規模なデータスワップが行われるなど、全面的な強化をもたらすだろう。
Lunar Lakeは2024年第3四半期に出荷される予定だ。Intelは、SKUやその性能、価格に関する情報を共有していないが、今後これらも明らかになるだろう。








コメント