
オープンソースソフトウェアのエコシステムが、これまで直面したことのない法的・倫理的な問いに向き合っている。その引き金を引いたのは、Dylan Ayrey氏(Truffle Security創業者)とMike Nolan氏(国連開発計画ソフトウェアアーキテクト)の2名が公開した「malus.sh」というサービスだ。2026年3月初旬に登場したこのツールは、任意のオープンソースプロジェクトをAIを用いて「法的に別個のコード」として再実装し、GPLやAGPLといったコピーレフトライセンスを事実上無効化できると主張する。
表向きは風刺的なデモンストレーションとして提示されているが、実際にサービスとして稼働しており、小額の料金を支払えば依存パッケージのリストを送るだけで再実装コードが返ってくる。サイトのキャッチコピーは「No attribution. No copyleft. No problems.(帰属不要。コピーレフト不要。問題なし。)」。 同サービスの名前「malus」はラテン語で「悪」を意味し、提供元の企業名は「EvilCorp」、架空のユーザー推薦文の署名は「Chad Stockholder」という徹底したブラックユーモアで演出されている。しかし、その法的な構造は骨格まで真剣だ。
19世紀の著作権判例が仮定していなかったシナリオ
この問題を理解するには、米国著作権法の根本に遡る必要がある。1879年の連邦最高裁判例「Baker v. Selden」以来、著作権法が保護するのは「表現(expression)」であり、「アイデア(idea)」そのものではない。プログラムのソースコードはその表現であるが、そのコードが実装する機能やアルゴリズムの概念は著作権の保護対象外だ。
この判例を実務に応用したのが「クリーンルーム設計(clean-room design)」という手法である。最も有名な実例は1982年のPhoenix Technologiesによるものだ。同社はIBM PCのBIOSを再実装する際、2チームに分けて作業を進めた。第一チームはIBM BIOSの動作を観察・文書化し、機能仕様書を作成する。第二チームはその仕様書だけを渡され、元のコードを一切見ることなく独自に実装する。このプロセスによって生まれたコードには、元の著作権が及ばないという法的立場が確立された。
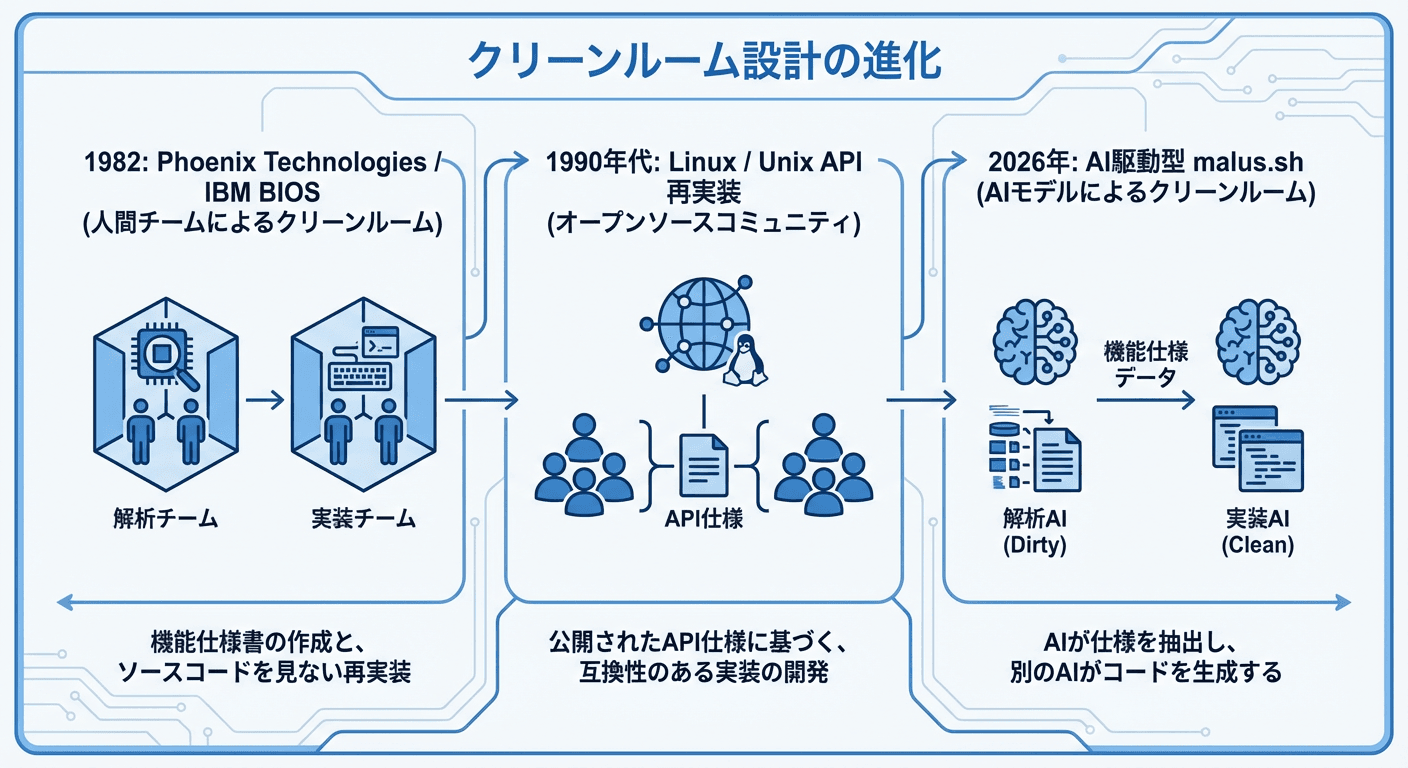
LinuxカーネルがいかにしてUnixのAPIを合法的に再実装できたか、WineがWindows Win32 APIを再実装できたかも、この先例なくしては語れない。
Ayrey氏とNolan氏が示したのは、このプロセスをAIが数分で代替できるという事実だ。AIに既存のオープンソースプロジェクトの公開ドキュメント、README、型定義などを読ませて仕様書を生成させ、別のAIにその仕様書から実装させる。2チームが数カ月かけて行っていた作業が、数回のプロンプトで完了する。
「トレーニングデータの汚染」という反論の限界
技術コミュニティから最も頻繁に聞かれる反論は「そのAIはオープンソースコードで学習しているから、クリーンルームとは言えない」というものだ。Hacker Newsでは1,400件を超えるコメントのうち、この点への言及が最も多かった。
この議論は直感的には正しい。実際、Claudeがchardet(Pythonの文字エンコーディング検出ライブラリ、LGPLライセンス)に対して行った再実装では、ライセンスヘッダーを含む元コードをほぼ逐語的に再現できることが実証されている。LLMのパラメータには、学習したコードの記憶が潜在的に埋め込まれている。
しかし、Remo H. Jansen氏をはじめとする複数の論者が指摘するように、この「汚染」問題はシステム設計の工夫で技術的には回避できる。具体的には:
ターゲットプロジェクトのソースコードを学習データから除外した専用モデル(LLM 2)を用意し、LLM 1が公開ドキュメントのみから仕様書を生成→LLM 2がその仕様書のみを見て実装、という2段階パイプラインを構築する。さらに、ベースモデルを変え、ホスティング管轄を複数国にまたがらせることで、法廷での立証をより困難にすることも可能だ。
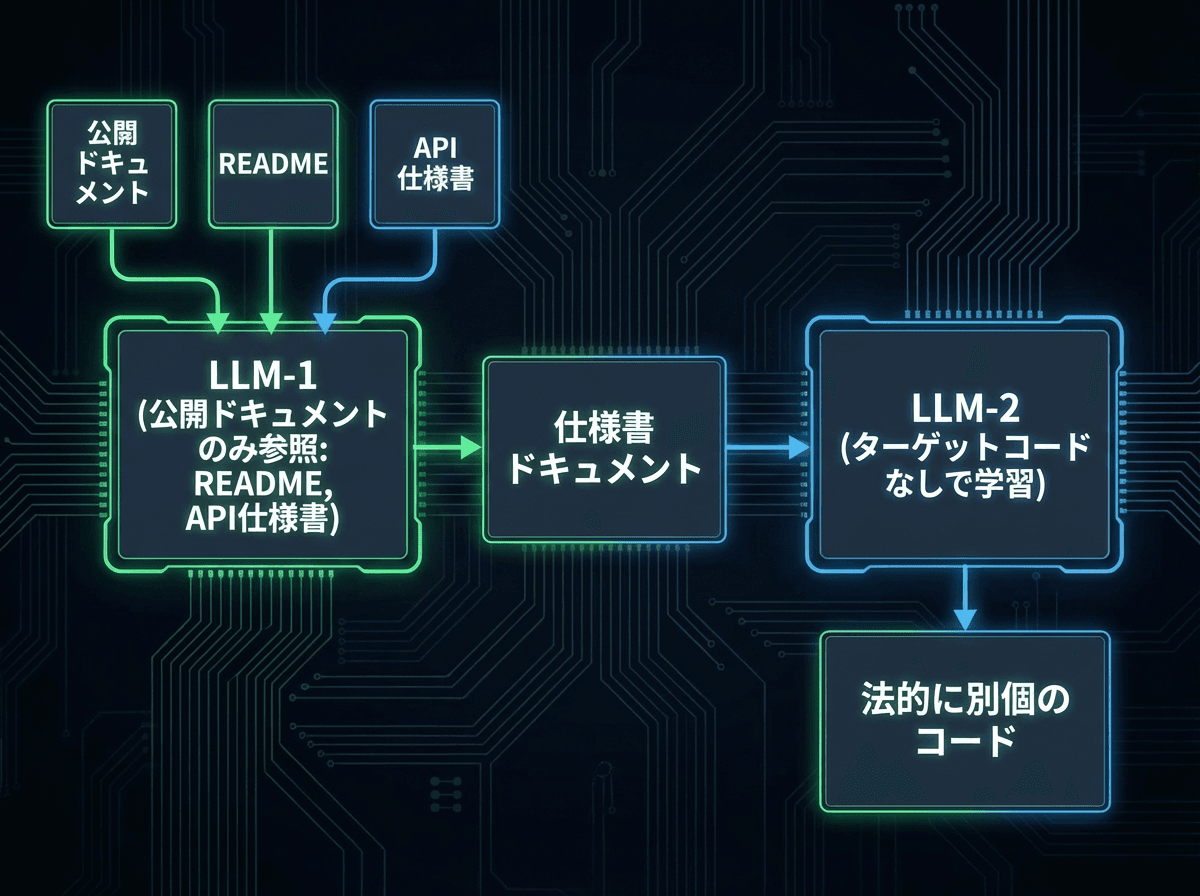
「学習データの汚染を証明せよ」という立証責任の問題も控えている。chardetの再実装を検証したメンテナー自身が、生成されたコードとオリジナルの類似度が1.5%しか検出できなかったと報告している。侵害の立証は原告側が行うものだが、数千万ものパラメータを持つモデルの「記憶」を法廷で証明するのは現実的に極めて難しい。
SaaSビジネスモデルへの波及:コードがコモディティになる世界
malus.shはオープンソース→プロプライエタリの方向性だけを扱うが、このロジックの逆方向もまた同様に機能する点が、より大きな産業構造への影響を示唆する。
SaaSサービスはソースコードを公開しないが、UIやAPIエンドポイントという「振る舞い」は観察できる。AIエージェントにUIを操作させ、APIのレスポンスを収集させ、それをもとに仕様書を生成し、別のモデルで実装する。このパイプラインにはクリーンルームとしての法的正当性が、オープンソースへの適用より強くある。ソースコードを「見て」いないため、著作権侵害のリスクがそもそも存在しにくいからだ。
Jansen氏の分析によれば、コードそのものを競争優位の源泉とするSaaS企業の大多数は「データモート(data moat)」を持たない限り存続が難しくなる。彼が例外として挙げるのは、LinkedInのソーシャルグラフ、Bloombergのリアルタイム金融データフィード、credit bureauの数十年にわたる信用履歴データといった、AIが複製できない独自データを保有する企業だ。逆に、機能の実装そのものが価値の本体であったSaaS企業には、急速にオープンソース代替品が出現するリスクがある。
AIによるコード生成速度が向上するにつれて、「SaaSを購入する」という行為の意味が根本的に変わりうる。かつてMP3の台頭が音楽の「所有」という概念を溶解させたように、コードという財の「希少性」が失われる先には、ソフトウェアライセンスビジネスの構造的な再編が待っている。
法的グレーゾーンに手放しで飛び込む企業への警告
楽観的な見方をする者の中には「これがビジネスとして大規模に展開されれば、訴訟リスクで誰も使わなくなる」という声もある。しかし、歴史はその楽観を裏切る事例を積み重ねてきた。
Microsoft Copilotは、GitHubに公開されたコードを学習データとして利用し、著作権者の警告を無視して商業展開された。Microsoftはリスク補償という形で著作権訴訟の費用を肩代わりする「Copilot著作権コミットメント」を設けることで企業顧客の懸念を回避した。AI生成アートの領域でも、著作権侵害の訴訟が継続するなか多くの企業がサービスを継続している。法的不確実性は、大企業にとってリスクよりも先行者優位のコストとして計算されるケースが少なくない。
Hacker Newsのコメント欄で法学的に鋭い指摘をしたユーザーは「Google v. Oracle判決はAPIコピーを無条件に許可するものではなく、Campbellテストが依然として適用される。クローン製品が市場でオリジナルの代替品として機能するかどうかという『市場代替可能性』が判断軸になりうる」と述べた。AI clean-roomで生成されたコードが元のオープンソースプロジェクトのドロップイン代替として機能する場合、変革的な利用とは言えないという主張は法廷で十分に戦える。
一方で、RedditのLinuxコミュニティでは「クリーンルームの法的防御は著作権の回避策ではなく、独立した創作を証明するための手続き的な仕組みであり、ケースバイケースのフェアユース判断とは別軸で機能する」という指摘もある。現状の法体系の下では、malus.shが想定するシナリオが「完全に合法」と断言するには、まだ裁判例が不足している。
コピーレフトの哲学的逆説:解放の手段が解放を殺す
Richard Stallmanがthe GNU General Public Licenseを設計した思想的背景は、ソフトウェアの自由を永続的に保護するという確信にあった。改変したコードの公開を義務付ける「ウイルス条項」と呼ばれる仕組みによって、GPLコードの派生物はGPLのままでなければならない。この連鎖が、フリーソフトウェアの海を時間とともに拡大させるという設計だ。
malus.shが象徴するAIクリーンルームの登場は、この哲学に皮肉な反転をもたらす。GPLソフトウェアがAIで再実装されMITに変換され→その派生がプロプライエタリ化され→別のAIがそのプロプライエタリ製品を観察してオープンソース化する、という無限連鎖が生じれば、あらゆるソフトウェアは最終的に事実上のパブリックドメインへと収束する。コードという財の保護が技術的に不可能になる世界では、ライセンスという概念そのものが装飾になる。
ここで注目すべきは、この変換が一方向ではないという点だ。Redditのlinuxコミュニティでは「プロプライエタリソフトウェアを逆にこのツールでオープンソース化できる」という声があり、事実、同様のパイプラインは双方向に機能する。AIがプロプライエタリなアプリのUI操作を観察し仕様書を生成してGPLコードとして出力する——その経路において「ソースコードを見ていない」という事実は、法的保護の根拠をさらに薄くする。つまりAIクリーンルームが本格的に普及した先では、オープンソースとプロプライエタリという二項対立そのものが意味を失う。境界が溶解した状態では、著作権レジームが前提としてきた「誰が何を所有しているか」という問い自体が答えを持てなくなる。
これはGPLが目指した自由とは似て非なるものだ。Stallmanは、ユーザーが自由にコードを実行・修正・共有できる世界を望んだが、その前提には「共同体として発展させる」という動機があった。AIによる自動化が生み出す「擬似的なパブリックドメイン」は、共同体的開発の動機をむしろ根絶する可能性がある。オープンソースで優秀なソフトウェアを書いても、数時間でプロプライエタリ化されるなら、なぜコミュニティに貢献するのか——その問いへの答えが変わるかもしれない。
ライセンスの未来:AIを射程に入れた第4世代へ
一部の開発者コミュニティでは「AIによるトレーニングを明示的に禁止もしくは制限する」条項を含む新たなライセンスの必要性が議論されている。「Non-AI License」や「Responsible AI License (RAIL)」といった取り組みはすでに存在するが、OSIのオープンソース定義との整合性の問題や、管轄を越えた執行困難性という壁がある。
政府レベルの対応策を論じるうえでも選択肢は乏しい。特許制度の拡張はソフトウェア特許の乱用を再燃させる。国際的な著作権の強化は、クラウドやVPNで管轄を跨ぐことが容易な現代では執行が機能しない。EUは消費者価値を重視する傾向があり、ソフトウェアが安くなること自体は歓迎される前提がある。地理的な規制の非対称性が存在する限り、最もゆるい管轄に「解放済みコード」がホストされ続けるという現実から逃れるのは難しい。
Ayrey氏とNolan氏の発表を締めくくった、AIが生成した映像の言葉が示唆するのはこの点だ——毎日餌を与えられる七面鳥は「人間は善意を持って自分を養ってくれる」と信じ込む。感謝祭の前日まで。オープンソースコミュニティが長年守り育ててきたコードベースが「感謝祭前日」を迎えていないと言い切るには、現時点では根拠が薄い。
Sources
- malus.sh
- Dev.to: Source code is now a common good, and SaaS is mostly dead
- Copyleft Currents: “Malus”: Is Copyleft Dead?