
生成AI技術が飛躍的な進化を遂げ、人間と同等、あるいはそれ以上の推論能力を持つとされる最先端の大規模言語モデル(LLM)が次々と登場している。我々は日常的にAIと対話し、コードの記述から複雑なデータ分析、文章の要約まで、多岐にわたるタスクを委ねるようになった。しかし、最新のAIモデルは我々が期待するほど「対話」を理解していない可能性が浮上している。
Microsoft ResearchとSalesforce Researchの共同研究チームが共同で発表した論文「LLMs Get Lost In Multi-Turn Conversation(LLMはマルチターン会話において迷子になる)」が、AI開発コミュニティに衝撃を与えている。研究チームは、OpenAIのGPT-4.1やo3、GoogleのGemini 2.5 Pro、AnthropicのClaude 3.7 Sonnet、さらにはDeepSeek R1やLlama 4 Scoutといった、現時点で業界最高峰とされる15のLLMを対象に、20万回を超える大規模な対話シミュレーションを実施した。その結果明らかになったのは、一度の指示で完璧にタスクをこなす優秀なAIが、人間との自然な往復のやり取り(マルチターン会話)においては致命的なまでにパフォーマンスを落とすという「会話迷子(Lost in Conversation)」と呼ばれる現象である。
完璧な実験室から現実の対話へ:「会話迷子」の衝撃的な実態
現在のAI産業におけるベンチマークテストの多くは、タスクに必要な全ての情報が一度のプロンプトで提供される「シングルターン」の環境で行われている。これはAIにとって、ノイズのない完璧な実験室のような条件だ。しかし、現実世界における人間のコミュニケーションは決してそのようには進まない。人間には「最小努力の法則(Principle of least effort)」が働き、最初は漠然とした要求を投げかけ、AIの反応を見ながら徐々に詳細な条件を追加していくという、仕様が不完全な状態からの漸進的な対話を好む傾向がある。
情報の「シャード化」が暴いたLLMの真の実力
研究チームは、この現実世界の複雑な対話をシミュレートするため、「Sharding(シャード化)」という斬新なアプローチを導入した。これは、元々1つのプロンプトにまとめられていた詳細な指示を、情報量ごとに複数の小さな断片(Shard)に分割し、会話のターンごとに1つずつAIに提示していくという手法である。プログラミングタスクやデータベース検索(SQL生成)、数学の文章題から長文の要約に至るまで、全6種類の多様なタスクでこのシミュレーションが実行された。
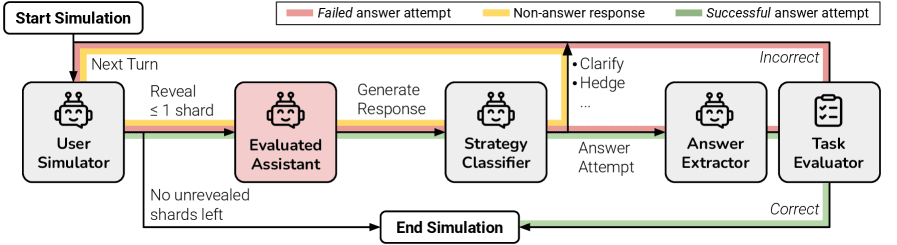
結果は極めて示唆に富むものであった。全ての情報を一度に与えられたシングルターンの環境において、テストされた最先端モデルは平均90%という驚異的なタスク成功率を記録した。しかし、同じ情報を複数回のターンに分けて小出しにするマルチターン会話へと形式を変更した途端、その成功率は平均65%へと急落したのである。全体の平均で39%ものパフォーマンス低下が確認され、この現象は小型のオープンソースモデルだけでなく、数千億パラメータを持つとされる超巨大な最先端モデルにおいても等しく観察された。
「知能の低下」ではなく「信頼性の崩壊」
このパフォーマンス低下の背景には、非常に興味深い統計的メカニズムが隠されている。研究チームがデータを詳細に分析した結果、AIモデルの純粋な「知能(Aptitude:最適条件下で発揮できる最高性能)」は、マルチターン会話においても約15%しか低下していなかった。つまり、AIは複数回の対話を経ても、タスクを解決するための基本的な能力そのものを喪失しているわけではない。
真の要因は、モデルの「非信頼性(Unreliability)」が112%という劇的な割合で急増したことにあった。非信頼性とは、同じタスクに対する最高スコアと最低スコアのブレ幅、すなわち出力のランダム性を指す。マルチターン会話に突入した途端、AIモデルは文脈を正確に維持できるかどうかのサイコロを振っているような状態に陥り、一貫した論理的判断を下すことが極めて困難になるのである。知能の高さにかかわらず、対話が長引くにつれてAIは自身の推論の軌道を見失い、二度と正しい答えに戻ってこられない「会話迷子」の状態に陥るというわけだ。
AIの論理を崩壊させる4つのメカニズム
なぜ、一度の指示なら完璧にこなせる高度なシステムが、情報を分けて伝えられるだけで機能不全に陥るのだろうか。20万回以上のシミュレーションログを解析した結果、AIがマルチターン会話で迷子になる根本的な原因として、以下の4つの振る舞いが特定された。
1. 早すぎる解決策の提示と仮定への固執
AIモデルは、ユーザーからの情報が不完全な初期の段階で、早急に最終的な解決策を導き出そうとする強い傾向を持っている。要件が全て出揃っていない状態であるにもかかわらず、AIは自らの学習データに基づいて欠落している情報を「仮定」し、答えを生成してしまう。
問題は、その後にユーザーから新たな情報や訂正が提供されても、AIが自身の初期の誤った仮定を修正できない点にある。新たな条件を既存の思考フレームワークに無理やり適合させようとするため、論理の矛盾が拡大していく。研究のデータによると、会話の最初の20%の段階で解答を試みたケースの成功率はわずか30.9%であったのに対し、最後の20%まで解答を保留し、文脈の確認に徹したケースでは64.4%まで成功率が上昇している。早とちりによる仮定の形成が、致命的な論理崩壊の引き金となっているのである。
2. 回答の肥大化と幻覚の定着
マルチターン会話が進行するにつれ、AIの出力する回答は徐々に肥大化していく現象も確認された。シングルターンの場合に比べ、複数回のやり取りを経た後の回答は20%から最大300%も長くなる傾向がある。
この「回答の肥大化」は、単に文章が長くなるだけでなく、AIが自身の出力の中に事実無根の前提や推論(ハルシネーション:幻覚)を紛れ込ませる余地を広げてしまう。LLMは自己回帰型のアーキテクチャを採用しているため、過去の自身の出力を次の推論の入力として使用する。そのため、一度出力された冗長な説明や誤った仮定は、会話の「恒久的なコンテキスト」として定着し、雪だるま式にエラーを増幅させていくのである。
3. 中間ターンの情報の忘却
長文を処理するLLMにおいて、入力テキストの最初と最後の情報はよく記憶されるが、中間の情報は無視されやすいという「Lost-in-the-middle(中間部分の喪失)」現象が広く知られている。本研究では、この現象が単一の長文テキストだけでなく、時系列で進行するマルチターン会話の履歴においても発生することが証明された。
AIは、対話の最初のターンで示された全体的な目的と、直近のターンで示された指示には過剰に反応する一方で、その間のターンで提示された重要な条件や制約事項を驚くべき頻度で忘却してしまう。その結果、会話の全体像を統合的に理解することができず、文脈が断絶した不自然な回答を生成してしまうのだ。
4. 冗長な応答による注意の自己逸脱
さらに、AI自身が生成する長文の応答そのものが、ユーザーからの短い指示を見失わせる原因となっている。会話においてAIが冗長に語りすぎると、コンテキストウィンドウ(AIが一度に考慮できる情報の枠)の大部分がAI自身のテキストで占められてしまう。結果として、ユーザーが提示した新しい仕様や微細なニュアンスに対する「アテンション(注意機構)」が相対的に薄れ、対話の軌道修正が極めて困難になるという自己矛盾に陥っている。
追加の計算資源やパラメータ調整は救世主となるか?
AI業界では、推論能力を高めるための新たなアプローチとして、OpenAIのo3やDeepSeek R1に代表されるような、出力前に追加の計算時間をかけて内部で論理を組み立てる推論モデル(Reasoning models)が注目を集めている。これらのモデルは、テスト時計算(Test-time compute)と呼ばれるプロセスを通じて、複雑なタスクの解決能力を飛躍的に向上させてきた。
しかし、今回の研究において、これら最新の推論モデルであっても「会話迷子」現象を回避できないことが明らかになった。追加の「思考トークン」を用いて深く論理を展開する能力は、シングルターンの問題解決には極めて有効であるものの、不完全な情報が飛び交うマルチターン環境においては、むしろ誤った仮定に基づく長大な内的思考を生み出し、混乱を深める結果を招くことが示唆されている。推論の深さと、対話の柔軟性は別次元の能力なのだ。
また、開発者がLLMの出力の一貫性を保つためによく用いる手法として、「Temperature(温度)」パラメータを0に設定し、生成のランダム性を最小限に抑えるというアプローチがある。しかし、この一般的な解決策も、マルチターンの文脈崩壊の前ではほぼ無力であった。初期ターンのわずかな解釈のズレが連鎖的に拡大していくマルチターン会話においては、出力を決定論的にしたところで、根本的な文脈の喪失を防ぐことはできないのである。
人類とAIの対話はどう変わるべきか
このMicrosoftとSalesforceによる先駆的な研究は、現在のAI開発の方向性と、我々のAI利用手法に対して重大なパラダイムシフトを迫っている。現在のベンチマークが示す「AIの知能の高さ」は、あくまで完璧な入力が与えられた条件下の幻影であり、現実の人間との協働においては、全く異なる評価基準が必要とされている。
ユーザーに向けた実用的な自己防衛策
現段階で、我々ユーザーが最新のAIモデルのポテンシャルを最大限に引き出すためには、直感に反するアプローチを取る必要がある。それは「AIを自然な対話のパートナーとして扱うことをやめる」という方法だ。
研究のデータが示す通り、最も確実で信頼性の高い結果を得るためには、必要なデータ、背景、制約条件、具体的な指示を、対話の中で小出しにするのではなく、1つの包括的な「メガプロンプト」として最初に全て提示する「Everything-upfront」の手法が推奨される。
もし、既にAIとの対話が進行しており、AIが頓珍漢な回答を繰り返す「迷子」の状態に陥っていることに気づいた場合は、その文脈の中で軌道修正を試みるのは得策ではない。AIに「これまで話した要件を一度全て箇条書きでまとめてください」と指示し、そのまとめをコピーした上で、完全に新しいチャットセッションを開始することが、現状において最も合理的な解決策となる。
AI業界と開発者への警鐘
システム開発の観点からは、LangChainやAutoGenといったエージェント構築フレームワークを用いて対話履歴を機械的に要約し直すアプローチ(RecapやSnowball手法)もテストされたが、単一の完全なプロンプトを与える手法(Concat)のパフォーマンスには及ばなかった。
これは、外部システムによる対話履歴の操作には限界があり、LLMの基盤モデルそのものが「ネイティブなマルチターン処理能力」を獲得する必要があることを強く示唆している。モデル開発企業は、シングルターンのベンチマークスコアによる知能(Aptitude)の競争から脱却し、複雑で不完全な情報が飛び交う現実の対話環境における「信頼性(Reliability)」の向上へと、直ちに舵を切らなければならない。
AIが真の意味で人類の知的パートナーとなるためには、単に膨大な知識を吐き出すだけでなく、人間が意図する曖昧な言葉の裏を読み取り、適切なタイミングで質問を返し、文脈の海で決して「迷子」にならない強靭な対話能力の獲得が不可欠である。その進化の道筋は、我々が直面しているこの本質的な欠陥を直視することから始まる。
論文
参考文献


