半導体設計の世界は、人類が構築した最も過酷で複雑な知的労働の舞台である。親指の先ほどのキャンバスに数百億のトランジスタを配置し、電流のタイミングをピコ秒単位で制御する。その工程は、アーキテクチャの定義、論理回路(RTL)の記述、果てしないシミュレーションによる機能検証、そして物理的な配置配線(プレース&ルート)と多岐にわたる。一度製造ラインに乗せれば、たった一つのバグが数千万ドルの費用を水泡に帰す。この圧倒的なプレッシャーと複雑さが、最先端チップの開発に数百人のトップエンジニアと数年の歳月、そして4億ドルを超える莫大な予算を要求してきた。プロセスの微細化が物理的な限界に近づく中、回路の集積度は高まり続け、それに伴う設計と検証のコストは指数関数的に膨張している。資金力のある一握りの巨大企業だけがこの特権的なプロセスを回し続ける構造が、長らく半導体産業の常識として君臨している。
既存のプロセスを効率化するため、EDA(電子設計自動化)ツールのプロバイダーたちはAIの導入を進めてきた。しかし、それらはあくまで特定の作業工程を支援する部分的な局所最適化にとどまっている。設計の初期段階から最終的な製造データに至るまで、ツール群を連携させながらプロジェクト全体を推進するのは、依然として人間の熟練エンジニアの仕事である。システムの一部をどれほど高速化しても、手動で処理しなければならない工程が残る限り、全体の処理時間はその手動部分の遅さに引っ張られる。チップ設計の全プロセスをエンドツーエンドで自律的に駆け抜けるシステムの構築は、きわめて困難な命題と考えられてきた。
この常識を根底から覆すブレイクスルーが、AIチップ設計スタートアップのVerkor.ioからもたらされた。彼らが開発した自律型AIエージェント「Design Conductor(DC)」は、人間のエンジニアが書いたわずか219語の英語の仕様書を入力として受け取り、そこから一切の人間的介入なしに稼働を続けた。そして12時間後、DCはRISC-Vアーキテクチャに準拠した完全なCPU「VerCore」の論理回路を組み上げ、徹底的な機能検証をくぐり抜け、最終的な製造用レイアウトファイル(GDSII)を出力することに成功したのである。仕様書の読み解きから工場のラインに流し込める「シリコンの型紙」の完成までを完全に自律化したこの成果は、ハードウェア設計の歴史において特筆すべきマイルストーンとなる。
巨艦主義の限界と「局所最適化」のジレンマ
半導体設計の自動化分野において、AIの導入自体は目新しいトピックではない。SynopsysやCadenceといった巨大EDAベンダーはすでに自社製ツールに高度なエージェント型のAIアシスタントを組み込んでいる。しかし、それらの立ち位置はあくまで人間のエンジニアを補助する「有能な副操縦士」にとどまる。限られた基板面積内での配線の最適化や、発熱を抑えるための特定ブロックの電力制御といった個別のタスクにおいては驚異的な速度を誇るものの、モジュール間の依存関係を考慮し、論理設計から物理レイアウトまで一貫した意思決定を下すのは人間の領域である。人間がツールの出力結果を評価し、各種パラメータを調整した上で、次のツールの入力フォーマットへと手動で整える「糊付け作業(グルー・ワーク)」が存在する限り、プロジェクト全体のボトルネックは根本的には解消されない。
この分断された設計ワークフローこそが、設計期間の短縮を妨げ、AIの恩恵を限定的なものにしてきた構造的要因である。Verkor.ioのアプローチは、このパラダイムに正面から挑戦する。個別のEDAツールを賢くするのではなく、設計プロセス全体を俯瞰し、自律的に外部ツールを呼び出しながら目標に向かって邁進する「オーケストラの指揮者」を創り上げたのである。
219語の要求から論理回路を紡ぎ出すオーケストレーション
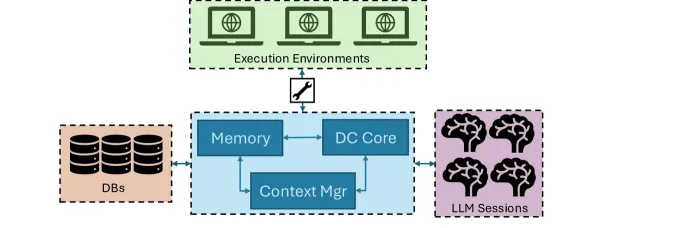
Design Conductor(DC)の核となるのは、単一の巨大なAIモデルがブラックボックスの中で回路を一息に出力する仕組みではない。DCは、複数の大規模言語モデル(LLM)を基盤に据え、特定の目標に向けて人間的なワークフローを強制する「ハーネス(手綱)」の役割を果たす。このシステムは自らを制御するためのメタ認知能力を持ち合わせており、設計の進捗に合わせて動的にサブエージェントを生成・破棄する。
ユーザーがDCに与えたのは「RV32IとZMMUL命令をサポートするRISC-V CPUを構築せよ」「5段のインオーダー・パイプライン設計」「1.6GHzのクロックレートを目標とし、CPI(1命令あたりの実行サイクル数)を1.5以下に抑えること」「ASAP7プロセスを使用すること」といった、219語の簡素なテキストデータのみである。DCはこの仕様書を受け取ると、設計計画エージェントやコード実装サブエージェント、そしてレビュー専門のエージェントへと自らのタスクを分割し、階層的な作業を開始する。
人間がコードを書いてはテストを繰り返すように、DCは自ら生成したモジュールごとにテストベンチを書き起こし、動作を徹底的に検証する。その検証プロセスは容赦がない。DCはRISC-Vの基準シミュレータである「Spike」と自身が生成した論理回路モデルを並行して稼働させ、MD5ハッシュ計算などのテストプログラムを実行し、サイクル単位での状態遷移やメモリアクセスが完全に一致するかを確認する。バグが発見されると、DCはVCD(Value Change Dump)ファイルと呼ばれる膨大な波形データを解析する。
これは例えるなら、数万人が参加するオーケストラの全楽器の音程と発音タイミングを記録した録音テープから、わずかにリズムのずれた一つのバイオリンの音を聞き分け、その演奏者にスコアの修正を指示するような極めて煩雑な作業である。実際の設計現場では数百ギガバイトにも及ぶこのデータを読み解くため、DCは自らの内部でデバッグ専用のPythonスクリプトを記述し、VCDデータをPandasライブラリを用いてCSV形式に変換するという離れ業をやってのけた。期待されるレジスタのトレースログとシミュレーションの実際の書き込み結果を自動で比較し、不一致の根本原因(パイプラインのフラッシュ機構の不具合による誤った命令実行など)を特定しては、Verilogコードを書き直していく。人間のエンジニアが数日を費やして目を酷使するデバッグ作業を、マシンパワーに物を言わせて数分で反復するシステムがそこにある。
クロックの壁を砕く自己最適化と「再発見」の妙
論理的な正しさが証明された後、DCはさらに苛烈なフェーズへと突入する。PPA(Power, Performance, Area)クロージャーと呼ばれる、面積、消費電力、動作周波数の物理的な制約を満たすための最適化作業である。論理的に動くだけではなく、現実のシリコン上で要求通りのスピードで信号が駆け巡らなければ、チップとしての価値はない。
最終的に生成された「VerCore」は、ASAP7という7nm相当の学術用プロセス設計キット上で、1.48GHzの動作周波数を達成した。ここで特筆すべきは、DCが性能目標をクリアするために、入力仕様書には全く書かれていなかった高度な回路構造を自ら「発見」し、実装した点である。
DCは乗算器の設計において、熟練したエンジニアが好んで用いるBooth-Wallaceツリーと呼ばれる高速演算アルゴリズムを自律的に選択し、4段のバランスの取れたステージを構築した。この乗算器単体であれば2.57GHzでの動作が可能である。さらにDCは、分岐命令に伴う遅延(ペナルティ)を最小化するため、2サイクルペナルティの設計と1サイクルペナルティの設計の両方を実際にGDSIIデータまで実装して比較検討を行った。1サイクルペナルティの設計は比較器の論理回路が複雑になるため、クロック信号が届くまでの時間的余裕(クリティカルパス)が厳しくなる。それでもDCは、全体の性能を最大化するためには1サイクルペナルティの設計が最適であると判断し、目標のタイミングに収めきった。これは、かつて名機と呼ばれた初期のMIPSアーキテクチャRISC CPUが採用したクリティカルパス構造を、AIが何の手引きもなしに再発見したことを意味している。
過去の遺産と比較される実力と、立ちはだかる「アーキテクチャ的直感」の壁
AIによって完全に自律設計されたVerCoreは、CoreMarkベンチマークにおいて3,261というスコアを記録した。キャッシュメモリを含まない面積は2,809µm²というコンパクトな領域に収まっている。
Verkor.ioの試算によれば、この性能は2011年中頃に登場したノートPC向けCPUであるIntel Celeron SU2300(Penrynアーキテクチャ・1.2GHz駆動)と同等の水準である。最新鋭のフラッグシップチップに比べれば、高度な分岐予測やアウトオブオーダー実行といった複雑な機能を持たないシンプルなプロセッサに見えるかもしれない。過去にも、中国のQiMengプロジェクトのようにGPTモデルを活用して短時間でRISC-V CPUを生成した例や、GPT-4に独自の8bitプロセッサを書かせた研究は存在した。DCがそれらと一線を画すのは、シミュレーション上の断片的なコード生成にとどまらず、商用レベルのEDAツールを自動駆動して物理的なタイミング制約と面積要件を満たした「製造手前のレイアウトデータ」まで、数千億トークンを消費しながら一気に到達した点にある。
| 比較項目 | 従来のトップエンド半導体設計 | 過去のAI設計(例: QiMeng等) | Design Conductor (本研究) |
|---|---|---|---|
| 設計にかかる時間 | 18〜36ヶ月 | 数時間〜数日 | 12時間 |
| チーム規模 | 数百人の専門エンジニア | 少数(主にRTL生成の補助) | AIエージェント+少数の指導者 |
| 自律的カバー範囲 | 個別ツールの操作は人間が担当 | RTL(論理コード)生成が中心 | 仕様書入力からGDSII出力まで完全自律 |
| デバッグ・検証手法 | 人間による波形解析と修正 | 単純なテスト環境での確認 | VCD波形解析、自律的Pythonスクリプト生成 |
しかし、この挑戦によって、LLMが抱える根本的な弱点も同時に露呈している。DCは時として、熟練の人間アーキテクトが直感的に避けるような泥沼の「ウサギの穴」に迷い込む。 例えば、クロック周波数の制約をどうしてもクリアできない局面に陥った際、DCは単純なデータ依存関係の整理に目を向けるのではなく、パイプラインの段数を無闇に深くするという大掛かりなアーキテクチャ変更に走ろうとした。これは設計全体を根本から揺るがす過剰な修正であり、結果として膨大なトークンと計算リソースを浪費することになる。経験を積んだ人間であれば一瞥して「配線の取り回しを変えれば済む」と判断できる問題に対し、AIは力技のコンピュート資源で殴りかかってしまうのである。
ソフトウェアの文法でハードウェアを語る危うさ
さらに根深い問題は、LLMが「時間」と「並行性」の概念をどう解釈するかという点にある。ハードウェアを記述するVerilogという言語は、多数の回路モジュールがクロック信号に合わせて一斉に動作する「イベント駆動型」の性質を持っている。ところが、現代のLLMは膨大なソフトウェアプログラム(上から下へ順次実行されるコード)を学習の土台としているため、Verilogのコードをあたかもシーケンシャルに実行されるソフトウェアのように推論してしまう癖がある。
論文によれば、DCは「依存するコードの行数を減らせば、チップ上の電気信号の伝達経路(クリティカルパス)も短くなる」という、ハードウェア物理学の観点からは的外れな推論を行った。コードの短さが必ずしも物理的な伝搬速度の向上を意味しないというハードウェアの鉄則を、汎用的なLLMは十分に理解していないのである。EDAツールから返される実際のタイミングレポートを参照することで最終的にはこの間違いを自己修正したが、このような回り道がシステム全体の速度を著しく低下させている。物理的なシリコンでの製造検証がまだ行われておらず、高度なチップになるほど要求される計算量が非線形に爆発するという現実も、今後の商用スケールアップにおける重い課題として横たわっている。
「ツール操作」からの解放。物理空間へ踏み出すエコシステム
12時間でRISC-V CPUを練り上げるDesign Conductorの登場は、人間のエンジニアから仕事を奪うという単純な未来を示すものではない。むしろ、極度に細分化された「EDAツールの操作」という作業からトップエンジニアを解放し、彼らを本来の「アーキテクト」の座へと引き戻す原動力となる。
現在、VerCoreはあくまでシミュレーション上の存在であり、物理的なシリコンとしてテープアウト(工場へのデータ引き渡し)された実績はまだない。ASAP7という学術用プロセスモデルを使用している点も、実際のTSMCやSamsungの最新ノードでの歩留まりや寄生容量といった過酷な物理的ノイズにどう対応するかという疑問を残している。しかし、Verkor.ioはこの設計手法の正当性を証明するため、来るDesign Automation Conference(DAC)にて、FPGA上に実装されたVerCoreのデモンストレーションを予定している。この実証が成功すれば、業界からの懐疑的な視線は確信へと変わるだろう。
これがビジネスにもたらすインパクトは計り知れない。自律型AI設計システムの普及は、これまで「数百億円の予算がないため採算が合わない」と切り捨てられてきた少数ロットの専用チップ市場(IoTデバイス、特定用途向けのエッジAI、専用制御システムなど)に対し、強烈なコスト破壊をもたらす。これからのハードウェア開発は、数名の専門家がAIにアーキテクチャの方向性と厳密な指標を与え、AIが数え切れないほどの設計バリエーションを並行してGDSIIまで実装し、その中から最良のものを選択するというプロセスに移行していく。これまで数百人が3年をかけていた複雑なチップの開発が、少数のチームによって数ヶ月で完遂される世界が目前に迫っている。
たった219語の要求が、一晩のうちに数十億のトランジスタの精緻な配置へと結実する。砂から知性を作り出す現代の錬金術は、自律型AIという新たな伴走者を得た。人間の直感とAIの無尽蔵の試行回数が交差するこのアプローチは、半導体産業が抱える開発期間のボトルネックを破壊し、知的創造のエコシステムそのものを再定義しようとしている。
論文