
雑踏の中で友人の声を聞き取ろうとする時、私たちの脳は驚異的な信号処理を行っている。周囲の騒音をフィルタリングし、断片的に届く音の欠片から文脈を推測し、欠落した情報を補完する。人類は声帯と声道という物理的な器官を通じて、極めて繊細かつ複雑な音の波を紡ぎ出し、この「騒音」という障壁を乗り越えてきた。長らく、機械が生成する合成音声はこの複雑な音響特性を再現できず、騒音環境下では容易にかき消されてしまう不完全な代替品とみなされてきた。
しかし、人工知能による音声合成技術が、わずか数秒の音声サンプルから個人の声を忠実に再現する次元へと到達した現在、この前提は音を立てて崩れ去った。ユニバーシティ・カレッジ・ロンドンのPatti Adank氏とローハンプトン大学のHan Wang氏らの研究チームは、最新のAIボイスクローンが背景雑音の存在する環境下において、元の生身の人間の声よりも圧倒的に高い明瞭度を持つことを実証した。『Journal of the Acoustical Society of America』(2026年4月)に掲載されたこの研究は、機械が人間の身体的制約を超えて「より優れた言語伝達手段」を獲得しつつある事実を提示している。
聴覚の限界を試す。ノイズ環境下での13.4パーセントの圧倒的優位
研究チームは、ボイスクローン技術が実際のコミュニケーション環境でどのように機能するかを検証するため、緻密な音響実験を設計した。イギリス国内の異なる地域(イングランドの10地域)の出身者から採取した10名の音声をベースに、音声AIプラットフォーム「ElevenLabs」のモデルを使用してそれぞれのクローン音声を生成した。モデルの学習に用いられた音声データは平均して約348秒にすぎず、一部の検証ではわずか10秒のサンプルでも実用レベルの音声が生成可能であることが示されている。
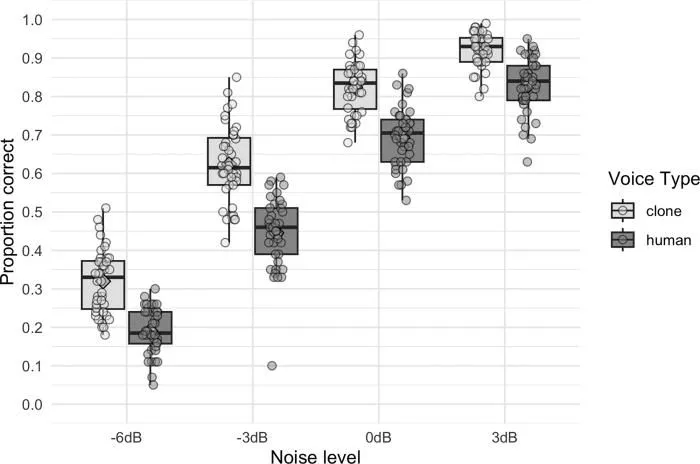
用意された「人間の生声」と「AIによるクローン音声」は、それぞれ4段階のノイズレベル(+3、0、-3、-6デシベル)の音声帯域雑音(Speech-shaped noise)と合成された。マイナス6デシベルという過酷な条件は、発話者の声よりも背景の雑音の方が物理的に大きい状態を意味する。80人の参加者は有線ヘッドフォンを通じてこれらの音声を聴き、聞き取れた文章のキーワードをタイピングするタスクを与えられた。
実験前、Adank氏自身も「クローン音声は元の声の不完全な模倣にすぎず、未だ人々の耳に馴染んでいないため、聞き取りにくいはずだ」と予想していた。しかし、結果は完全に直感に反するものだった。すべてのノイズレベルにおいて、クローン音声は人間の生声よりも高い正答率を叩き出したのだ。人間の生声の平均正答率が54.1パーセントであったのに対し、クローン音声は67.5パーセントを記録し、13.4パーセントポイントもの明確な優位性を示した。最も差が開いた音声ペアでは、その差は22.3パーセントポイントにまで達している。
驚くべきことに、この現象は実験条件を変えても一貫して観察された。研究チームは追試として、聴力が低下しがちな高齢者のボランティアや、元のイギリス英語のアクセントに不慣れなアメリカ人のリスナー、さらには人工内耳の聞こえ方を模倣した特殊な音響フィルターを通した状態での聞き取りテストも実施した。いかなる過酷な聴取環境に置かれても、クローン音声は人間の肉声に勝利したのである。
明瞭さの追求から「個人の模倣」へ。音声合成の歴史的転換点
今回の発見が持つ真の学術的意義を理解するには、音声合成技術が歩んできた歴史的文脈を俯瞰する必要がある。SiriやAlexaといった従来のテキスト読み上げ(TTS)システムは、プロのナレーターや声優を無響室などの録音スタジオに拘束し、何時間にもわたって発音のサンプルを収録することで構築されてきた。Google WavenetやAmazon Pollyに代表されるこれらの商用音声システムは、その設計の初期段階から「いかに万人に聞き取りやすく、極限までクリアに発音するか」という命題を背負わされた人工物である。
実際、過去のMa and Tangら(2024年)の研究において、これら商用TTSが騒音下で人間の声の明瞭度を上回ることはすでに報告されていた。しかし、それらはあくまで「聞き取りやすさを最適化されたプロの声」をベースにした結果である。
対照的に、本研究で用いられた現在のボイスクローン技術は深層学習モデルを用い、対象者の日常的な声のサンプルから音色の特徴や抑揚のパターンを抽出して再構築する。これは「明瞭さ」ではなく「いかに特定の個人に似せるか(声の類似性)」を最優先するシステムである。元となる人間がぼそぼそと話す癖を持っていれば、理屈の上ではその不明瞭さも引き継がれるはずである。それにもかかわらず、結果的にクローン音声がノイズに強いという特性を獲得した事実は、生成AIのブラックボックスの中に、音響工学のセオリーを超える未知の最適化プロセスが存在することを示唆している。
| 比較項目 | 従来の商用TTS (Siri, Amazon Polly等) | 最新のボイスクローン (ElevenLabs等) | 人間の生声 |
|---|---|---|---|
| データ要件 | 数時間以上の専用スタジオ収録 | 最短10秒〜数分の日常的な音声 | 不要 |
| 設計の主目的 | 全体的な明瞭度と均質性の確保 | 特定の個人の音色・抑揚の忠実な模倣 | 自然発生的な発声 |
| 音響的特徴 | 意図的に平坦化された人工的な響き | 類似性を保ちつつ雑音成分が平滑化された響き | 微細な揺らぎや不規則なノイズを含む |
| 騒音下での伝達力 | 元々高い明瞭度を持つよう調整済み | 非常に高く、本人の声より13.4%優位 | 環境や発声者の体調に大きく依存する |
摩擦のない音波。機械が導き出した「聞きやすさ」の正体
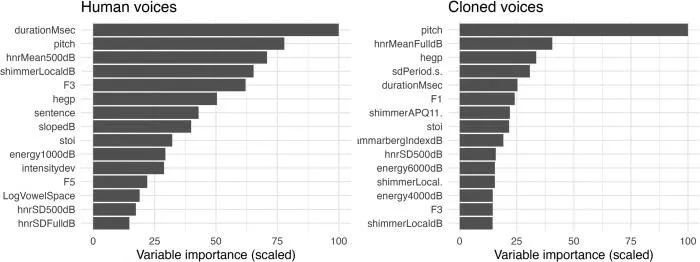
なぜクローン音声は騒音を切り裂いて人間の耳に届くのか。研究チームは47種類にも及ぶ音響指標を抽出し、主成分分析(PCA)を用いてこれらの膨大なデータを5つのコア要素に圧縮したうえで、線形判別分析(LDA)を通じて両者の声の物理的な違いを解剖した。
人間が発する声には、声帯の微細な振動の乱れに起因するジッター(周波数の揺らぎ)やシマー(振幅の揺らぎ)と呼ばれる不規則な微小ノイズが常に含まれている。私たちが他者の声に温かみを感じる理由の一部は、この物理的な不完全さにある。しかし、音響空間を飛び交うノイズの海の中では、この不完全さが伝達を妨げる致命的な弱点に変わる。
主成分分析の結果、AIによるクローン音声と人間の声を分かつ最大の要因は「声の安定性(Vocal Stability)」と「調和音対雑音比(Harmonic-to-Noise variability)」であることが判明した。クローン音声はジッターやシマーといった微細な揺らぎが劇的に少なく、声の波形が極めて滑らかであった。同時に、500ヘルツから3500ヘルツという、人間の音声認識において最も重要とされる中音域において、調和音成分が極めて強い(雑音が少ない)という明確な特徴を持っていた。
これを日常的な感覚に翻訳するならば、人間の声が「表面に細かな凹凸のある手作りのガラス細工」であるとすれば、AIのクローン音声は「工場で精密に研磨され、一切の曇りがないクリスタルガラス」である。人間が騒音に負けまいと唇や舌の動き(フォルマント空間の拡大)で言葉の輪郭をはっきりさせようと努力するのに対し、AIは音の響きそのものから不要な濁りを消し去り、純度の高いエネルギーの束として音波を射出している。
さらに主観評価において、クローン音声は元の声が持っていた地域の訛り(アクセント)が薄れ、より標準的な発音に近づいていると評価されている。AIは単に音声を複製する過程で、無意識のうちに言語としての伝達効率を最適化する「音の研磨」を行っていたのである。
見破られる完全性。人間が「不気味の谷」で感じる違和感の正体
クローン音声がこれほどまでに明瞭であるならば、私たちはもはや人間と機械の声を聞き分けることができないのだろうか。実験の最終段階で行われた二肢強制選択(2AFC)タスクの結果は、人間の知覚の奥深さを静かに物語っている。
参加者に同じ文章の「人間の声」と「クローン音声」を連続して聞かせ、どちらが本物の人間かを当てさせたところ、70.4パーセントの精度で正解を導き出した。つまり、私たちはクローン音声を情報伝達の手段として明確に認識しながらも、脳の深層ではその完全すぎる滑らかさに違和感を覚え、「これは生身の人間ではない」という識別を行っている。
論文の考察部分でも触れられている通り、この現象はロボット工学やCG分野で知られる「不気味の谷(Uncanny Valley)」の聴覚版と言える。AIがジッターやシマーといった微細な揺らぎを過剰に平滑化する現象は、現在のモデルが学習データのノイズ成分をうまく処理しきれず、結果として理想化された平均値に収束してしまうことに起因すると推測される。私たちは他者の声の中に、無意識のうちに微妙な音響的・韻律的な揺らぎを期待している。その「人間らしいノイズ」が欠落した過度に整えられた音は、人間に特有の不気味さを感じさせる。皮肉なことにその不自然さこそが、現在のディープフェイク音声を人間が見破るための防波堤となっているのである。
ささやきが凶器に変わる時。ディープフェイク詐欺への脅威

この技術的ブレイクスルーは、決して学術的な好奇心を満たすだけのものではない。たった10秒の音声から「本人以上に聞き取りやすいクローン」が生成できるという現実は、サイバーセキュリティの領域において深刻なパラダイムシフトを引き起こす。
近年急増している「オレオレ詐欺」やビジネスメール詐欺(BEC)の進化系であるディープフェイク音声詐欺において、犯罪者たちは被害者の声のサンプルをSNSの短い動画などから容易に調達できる。これまで、生成された合成音声の不自然さを隠すために、詐欺師は意図的に背後に雑音を混ぜたり、通信状態が悪いふりをしたりする手法を用いてきた。
しかし本研究のデータは、騒音環境下であればあるほど、クローン音声の伝達力が人間の生声のそれを圧倒することを示している。激しい雨音、交通渋滞のクラクション、あるいは雑踏の喧騒といったノイズの中で電話を受けた時、人間の耳はクローン音声の異常に滑らかな波形を「非常に聞き取りやすいクリアな声」として無批判に受け入れてしまう危険性が高い。犯罪の文脈において、AIが生成する「摩擦のない声」は、被害者の警戒心を解くための極めて鋭利な凶器となる。
声の再定義。テクノロジーがもたらす社会的インパクトと展望
本研究の成果は、社会インフラや医療機器の設計思想に対し、根本的な変革を迫るほどの力を持っている。
最大の恩恵を受けるのは、音声補助技術や聴覚デバイスの領域である。脳卒中やパーキンソン病、あるいは筋萎縮性側索硬化症(ALS)などにより自らの声を失いつつある人々にとって、合成音声は世界と繋がる最後の生命線となる。自身の過去の音声データからクローンを生成し、それをリアルタイムで合成するシステムが実用化されれば、聞き取りにくくなった肉声の代わりに、かつての自分の声色を保ったまま、騒音下でも周囲に的確に意思を伝えることが可能になる。また、補聴器や人工内耳のシステムにこのボイスクローン技術を組み込み、配偶者や家族の声をあえてAIでリアルタイム処理してから耳に届けることで、周囲が騒がしくても大切な人の声を明瞭に認識できる未来も現実味を帯びてくる。
空港や駅のプラットフォームなど、複雑な反響と騒音が渦巻く空間での公共アナウンスメントにおいても、クローン音声の採用は情報伝達の確実性を飛躍的に高める。緊急時の避難誘導など、一言の聞き逃しが命に関わる局面において、13.4パーセントの明瞭度向上は計り知れない価値を生むだろう。
一方で、未解明の課題も残されている。今回検証されたのは「音声帯域雑音」という連続的なノイズ環境下での結果であり、複数の人間が同時に話している状況(カクテルパーティー効果が試される情報的マスキング)や、通信回線の劣化といった異なる条件下でも同様の優位性が保たれるかは検証されていない。さらに、商用AIモデルの内部処理は完全にブラックボックス化しており、アルゴリズムがなぜ特定の倍音構造を強調するのかという因果関係の完全な解明には至っていない。
Adank氏ら研究チームは今後、音声合成エンジニアと協力し、デジタル信号処理の観点からこの最適化メカニズムをリバースエンジニアリングしていく計画を進めている。
機械は人間の声を単に模倣する段階を終え、独自の音響的進化を遂げ始めた。私たちが日常的に耳にする声の風景は、近い将来、より滑らかで、より透き通った「作り物の響き」によって静かに塗り替えられていくことになる。
論文
- The Journal of the Acoustical Society of America: Voice clones are easier to understand in noise than their human originals: The voice cloning intelligibility benefit
参考文献