中国Alibabaは、学習コストを90%以上削減しながら、特定タスクで10倍以上の処理能力を発揮する驚異的な効率性を実現したという「Qwen3-Next」を発表した。カスタマイズされたMoEアーキテクチャを基盤としたQwen3-Nextは、AI業界が直面する計算コストの爆発という課題に対する、一つの明確な回答かもしれない。
AI開発のコストパラダイムを覆す一手
近年、AIモデルの性能向上は、そのパラメータ数を増大させることで達成されてきた。しかし、この「規模の追求」は、モデルの学習と運用に必要な計算資源、すなわち電力とコストの爆発的な増加という深刻な副作用を伴う。一部の巨大テック企業しか開発競争に参加できないという現状は、技術の健全な発展を阻害しかねない。
こうした状況に、AlibabaのQwenチームが投じた一石が「Qwen3-Next」である。 公式発表によると、この新アーキテクチャを基に開発されたQwen3-Next-80B-A3B-Baseモデルは、同社の旧世代の高性能モデルQwen3-32Bと比較して、わずか9.3%の計算コスト(GPU時間)で学習を完了させたという。
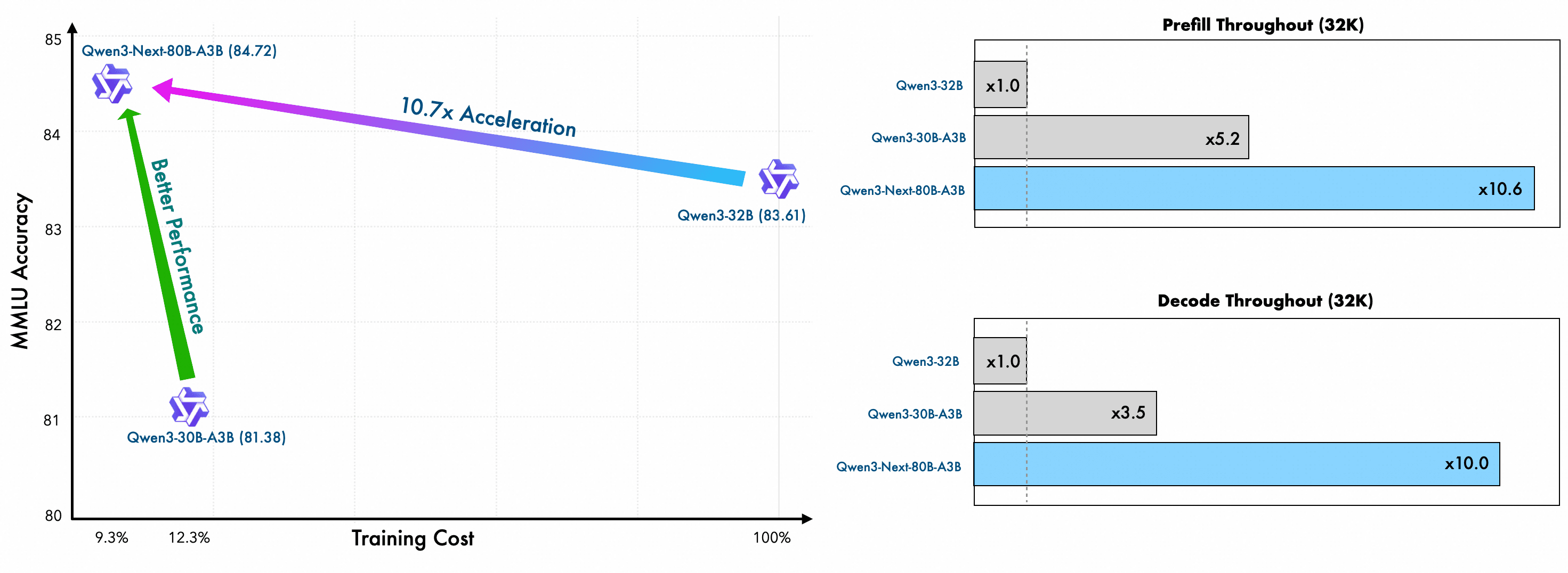
衝撃は学習コストだけにとどまらない。推論(AIが実際にタスクを処理する)段階では、特に32,000トークンを超えるような長文コンテキストを扱う場合、スループット(処理能力)は10倍以上に達する。 これは、より少ないコストで、より高速なAIを、より多くの開発者が利用できる未来を示唆している。まさにAI開発におけるコストパラダイムの転換点となる可能性を秘めた発表だ。
効率性の心臓部:Qwen3-Nextの革新的アーキテクチャ
では、この驚異的な効率性はいかにして実現されたのか。Qwen3-Nextの核心には、既存技術のトレードオフを巧みに克服する、いくつかの独創的なアーキテクチャ上の工夫が存在する。
「良いとこ取り」の妙技:ハイブリッドアテンション
LLMの性能を支える根幹技術の一つが「アテンションメカニズム」だ。これは文章中の単語間の関連性を計算する仕組みだが、従来の標準的なアテンション(Standard Attention)は、高い精度を持つ一方で、計算量がコンテキスト長の二乗に比例して増加するという致命的な弱点を抱えていた。
この問題を解決するために、計算量を線形に抑える「線形アテンション(Linear Attention)」も研究されてきたが、こちらは速度と引き換えに精度、特に文脈から特定の情報を正確に思い出す能力(リコール能力)に課題があった。
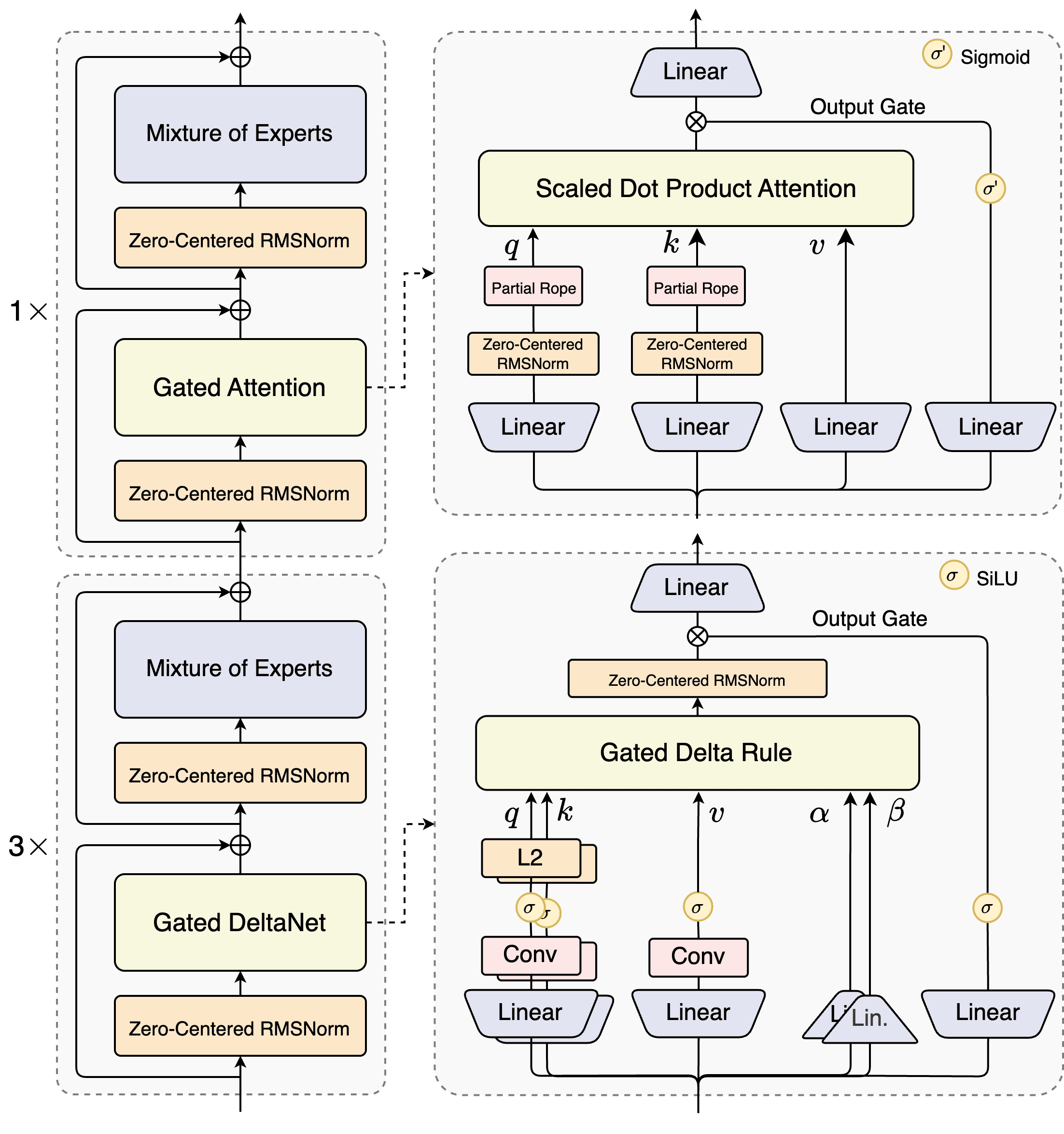
Qwen3-Nextが採用したのは、この両者の「良いとこ取り」を目指したハイブリッドアーキテクチャだ。具体的には、高速だがリコール能力に優れた「Gated DeltaNet」と呼ばれる線形アテンションと、高精度な標準アテンションを3:1の比率で組み合わせている。 つまり、モデル内のほとんどの層(75%)は高速なGated DeltaNetで処理を効率化し、要所となる層(25%)にのみ計算コストの高い標準アテンションを配置することで、全体の性能を損なうことなく、劇的な高速化を達成したのだ。これは、限られた資源を最も効果的な場所に集中投下するという、極めて洗練された設計思想と言えるだろう。
賢く、そして怠惰に:超スパースMoEの威力
Qwen3-Nextのもう一つの心臓部が、「超スパース(極めて疎な)Mixture-of-Experts(MoE)」アーキテクチャである。
MoEとは、巨大な一つのニューラルネットワークの代わりに、それぞれが異なる専門知識を持つ多数の小さな「専門家(Expert)」ネットワークを用意し、入力されたタスクに応じて最適な専門家チームを動的に選んで処理させる仕組みだ。これにより、モデル全体のパラメータ数が巨大であっても、実際に稼働するのはその一部で済むため、計算コストを大幅に削減できる。
Qwen3-Nextは、このMoEの「スパース性」を極限まで高めた。総パラメータ数は800億に達するが、一つのタスクを処理する際にアクティブになるパラメータは、わずか30億(全体の約3.7%)に過ぎない。 これは、いわば800人の専門家集団の中から、案件ごとに最適な30人だけのドリームチームを編成して対応するようなものだ。
この設計は、旧世代のQwen3モデル(128人の専門家から8人を選択)と比較しても、専門家の総数を512人に増やしつつ、選択する人数を10人程度に抑えるという、より高度な専門分化と効率化を推し進めている。 この「賢く、そして怠惰に働く」アーキテクチャこそが、学習コスト90%削減という驚異的な数字の最大の立役者なのである。
安定と高速化を支える縁の下の力持ち
大規模モデルの開発現場は、常に「学習の不安定さ」との戦いでもある。Qwen3-Nextでは、この課題に対処するための地道な改良も複数盛り込まれている。
- Zero-Centered RMSNorm: 学習中の数値的不安定性を抑制し、大規模な学習がスムーズに進行するように貢献する正規化技術。
- MoEルーターの正規化: 学習初期段階で各専門家が偏りなく選ばれるように工夫し、学習プロセス全体の安定性を高める。
- Multi-Token Prediction (MTP): 一度に一つの単語ではなく、複数の単語をまとめて予測する仕組み。これにより、推論速度をさらに向上させる「投機的デコーディング(Speculative Decoding)」の効率が劇的に改善される。
これらの技術は一見地味かもしれないが、巨大で複雑なシステムを安定稼働させ、その性能を最大限に引き出すために不可欠な、まさに縁の下の力持ちだ。
目的別に最適化された2つの顔
Alibabaは、この革新的なQwen3-Nextアーキテクチャをベースに、用途の異なる2つのモデルをオープンソースとして公開した。
Qwen3-Next-80B-A3B-Instruct は、一般的な対話や指示応答タスク向けに調整されたモデルだ。特筆すべきはその長文脈処理能力で、標準で256,000トークン(日本語で十数万文字に相当)のコンテキストを扱うことができる。 これは、長大な論文や判例、技術文書を読み込ませて要約させたり、RAG(検索拡張生成)システムで大量の検索結果を一度に処理させたりといった高度な応用を可能にする。その性能は、Alibabaの2,350億パラメータを持つフラッグシップモデルに匹敵するレベルに達しており、極めて高いコストパフォーマンスを誇る。
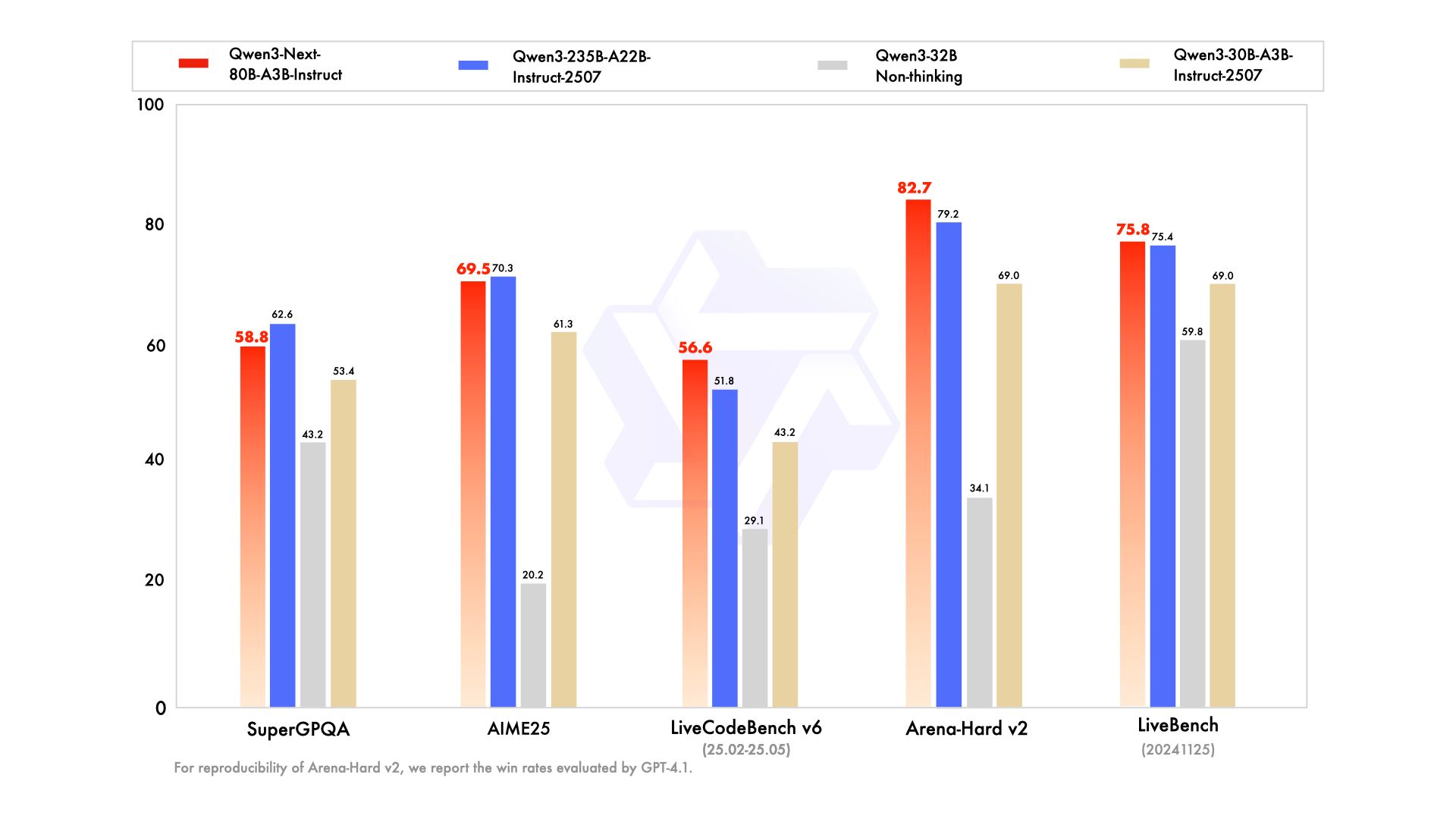
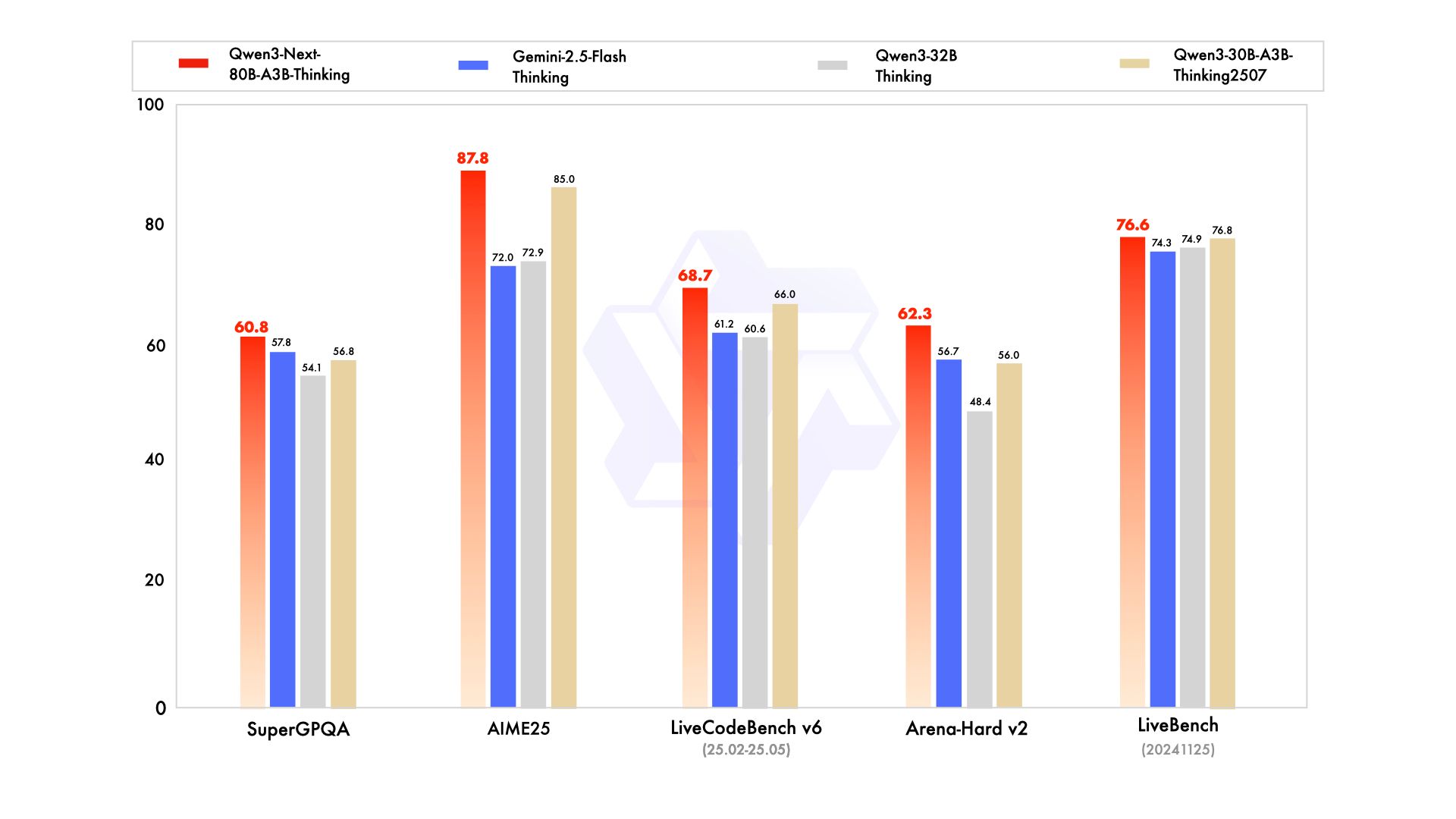
一方、Qwen3-Next-80B-A3B-Thinking は、数学やコーディング、論理パズルといった複雑な推論タスクに特化したモデルである。ベンチマークテストでは、GoogleのクローズドなモデルであるGemini-2.5-Flash-Thinkingを複数の項目で上回り、Alibaba自身の最上位推論モデルにも迫る性能を示した。 これは、効率性を追求したアーキテクチャが、決して性能を犠牲にするものではないことを明確に証明している。
Alibabaの戦略とAI業界への波紋
今回のQwen3-Nextの発表は、AI業界全体の競争力学に影響を与える重要な動きだと筆者は見ている。
注目すべきは、Alibabaが一貫して高性能モデルをオープンソースで公開し続けている点だ。 これは、特定の企業が技術を独占するのではなく、世界中の開発者がアクセス可能なオープンなエコシステムを構築することで、米国の大手テック企業が主導するクローズドなAI開発に対抗しようとする明確な戦略の表れだろう。開発者コミュニティを味方につけることで、自社のプラットフォーム(Alibaba Cloud)への誘導も狙っているはずだ。
そして、より本質的な変化は、「効率性」がAIモデルの競争における新たな、そして極めて重要な評価軸として台頭してきたことだ。これまでは「パラメータ数が多ければ多いほど良い」という単純な物量競争の側面が強かった。しかし、Qwen3-Nextは、アーキテクチャの工夫次第で、はるかに少ない計算コストで同等以上の性能を引き出せることを示した。これは、自動車業界における燃費性能や、半導体業界におけるワットパフォーマンスのような、「賢さ」を問う競争の始まりを告げているのかもしれない。
この流れは、AIの民主化を加速させるだろう。これまで計算資源の制約から大規模AIの開発・運用をためらっていた大学、研究機関、スタートアップにとって、Qwen3-Nextのような高効率モデルはまさに福音だ。より多様なプレイヤーがAI開発に参入することで、イノベーションが加速することは間違いない。
Alibaba自身も、Qwen3-Nextは次世代の「Qwen3.5」に向けた重要なステップであると公言している。 今回のアーキテクチャをさらに洗練させ、前例のないレベルの知能と生産性を目指すという。
AIの進化は、もはやパラメータの数を競うだけの力比べの時代を終えようとしている。いかに賢く、効率的に知能を構築するか。Qwen3-Nextが示した新たな地平線の上で、AI開発の次なるチャプターが今、始まろうとしているのではないだろうか。
Sources