大規模言語モデル(LLM)のコンテキストウィンドウは拡大の一途をたどっている。AnthropicのClaude Opus 4.7やSonnet 4.6は100万トークンを処理でき、GoogleのGemma 4も12万8000から25万6000トークンに対応する仕様だ。しかし、システムプロンプトやツール定義、スキル、メモリファイルなどを読み込ませると、実効容量は10から20%ほど削り取られる。さらに、すべての情報を保持したまま処理を続けると、情報のノイズが増えて応答品質が劣化する現象に直面することになる。Cloudflareは2026年4月17日、AIエージェント向けのマネージドサービス「Agent Memory」をプライベートベータ版として発表した。会話データを外部に保存し、必要なタイミングで取得する非同期ストレージの仕組みを実装している。
100万トークンでも「使えるコンテキスト」は80%に満たない理由
CloudflareのエンジニアであるTyson Trautmann氏とRob Sutter氏は、公式ブログで「コンテキストロット(context rot)」という概念を提示した。会話の履歴や背景情報が蓄積されるにつれて、AIモデルが重要な情報を見落としたり、矛盾した回答を生成したりする現象を指す。大規模言語モデル特有の、長い文章の中間部分にある情報を無視しやすくなる「Lost in the Middle」現象もこの劣化を加速させる。すべての情報をコンテキストに保持し続けるか、あるいは古い情報を積極的に切り捨てるか、どちらの戦略をとっても最終的にエージェントの応答品質は落ちていく。長期間稼働するシステムには、情報の取捨選択が不可欠だ。
3ヶ月以上稼働するコーディング支援エージェントのプロジェクトでは、この劣化像が鮮明に現れる。プロジェクト初期に合意したアーキテクチャの設計判断や、特定のライブラリのバージョン固定といった重要な前提条件を、会話が長引くにつれてエージェントが無視する事態が頻発する。以前の決定事項を忘れる振る舞いは、開発者の修正コストを増大させる結果を招く。数週間から数ヶ月にわたってコードベースで作業するようなエージェントは、成長に伴って有用性を維持するための新しい記憶管理手法を必要としている。
Trautmann氏とSutter氏は「より多くのコンテキストが常に良いわけではない」と指摘した。モデルのウィンドウにすべてを詰め込むのではなく、会話から事実やイベント、指示、タスクを抽出して保存するアプローチを提唱している。重要な情報を記憶し、不要なものを忘れ、時間とともにエージェントを賢くする仕組みが求められている。
5操作・8チェック・5並列チャネル:Agent Memoryのパイプライン全解剖
AIエージェントが記憶を扱うには、取り込む・覚える・思い出す・忘れる・一覧する、という5つの動詞で考えると整理しやすい。Agent MemoryはこれをIngest/Remember/Recall/Forget/Listとして実装した。Ingestはコンテキスト圧縮時に会話のログからメモリを自動的に抽出し、Rememberはモデルのツール使用を経由して特定の重要情報を直接保存する。Recallはメモリから統合された回答を検索・取得し、Forgetは関連性がなくなった古いメモリに印を付け、Listは保存済みメモリの一覧を表示する。
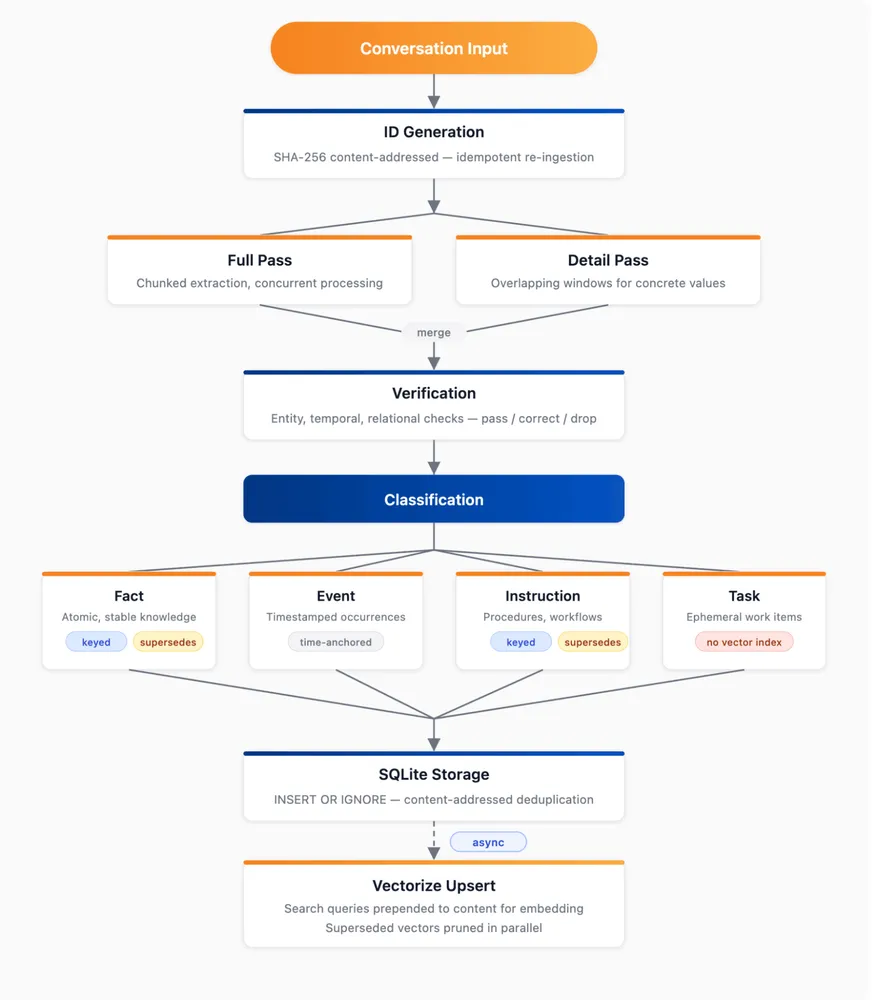
取り込みパイプラインの最初のステップでは、コンテンツアドレスのSHA-256(Secure Hash Algorithm 256-bit)ハッシュを用いて決定論的IDを生成する。これにより、システムが再起動したり同じデータを複数回読み込んだりした際の再取り込み時の冪等性が保証される。続く抽出フェーズでは、フル抽出と詳細パスの2つの並列パスが、オーバーラップを持たせながらテキストのチャンクを処理していく。多段階のアーキテクチャが、細かい文脈の取りこぼしを防ぐ構造だ。
抽出されたデータは、8つのチェック項目による厳格な検証プロセスを通過する。ここではエンティティの同一性や時間的な正確性、事実的根拠が厳密に確認される。例えば「昨日」や「来週」といった相対的な時間表現は、システム内で絶対的な日時に変換されてから記録される仕組みだ。検証を終えたメモリは、原子的・安定的な知識であるFacts、時間依存の出来事を示すEvents、手順やワークフローを表すInstructions、一時的な作業項目であるTasksの4種類に振り分けられる。
保存時には、コンテンツアドレスの重複を避けるためにデータベース上で「INSERT OR IGNORE」コマンドが実行される。バックグラウンド処理としてデータはすぐにベクトル化され、検索クエリがメモリテキストに追加される仕組みを採用した。取得パイプラインでは、ユーザーからのクエリが並行分析と5つの並列取得チャネルを同時に通過していく。
取得チャネルには、Porterステミング(単語の語幹を抽出するアルゴリズム)付き全文検索や厳密なfact-keyルックアップ、生メッセージ検索が組み込まれている。さらに直接ベクトル検索と、HyDE(Hypothetical Document Embedding:仮説的文書埋め込み)ベクトル検索も並行して走る。抽出された結果は、重み付きスコアのReciprocal Rank Fusion(複数検索結果の順位を統合する手法)によって統合され、同点の場合は最新データが優先される。
170億と1200億パラメータの使い分け:Agent Memoryが選んだ2モデル構成
抽出・検証・分類・クエリ分析には170億パラメータのLlama 4 Scoutを使い、回答統合には1200億パラメータのNemotron 3を割り当てる。一見アンバランスなこの設計に、Agent Memoryの中核にある設計思想が凝縮されている。Llama 4 Scoutは16の専門家ネットワークを持つMoE(Mixture of Experts:専門家混合)アーキテクチャで構成されており、入力されたタスクに応じて最適な専門家サブネットワークだけを稼働させる。
開発チームの検証プロセスで、より大きくパラメータ数の多いモデルが常に優れた結果を出すわけではないという事実が判明した。構造化されたデータの抽出や分類タスクでは、小型のLlama 4 Scoutがコスト、応答品質、レイテンシの3要素で最適なバランスを弾き出した。回答統合という複数の記憶断片を文脈的にまとめる推論タスクにのみ、1200億パラメータの大型モデルを投入する設計だ。
プロファイル単位のストレージには、ステートフルなエッジストレージであるDurable Objects(バックエンドに軽量データベースのSQLiteを使用)が使われている。これにより、厳格なテナント分離と名前ベースのアドレッシングが機能する。埋め込み済みメモリ上のベクトル検索はベクトルデータベースサービスのVectorizeが担当し、抽出や分類などのモデル実行はWorkers AIが担う。既存のインフラスタックを垂直統合することで、システム全体が組み上げられた。
チームはエージェント駆動のループを用いてシステムを反復的に改善した。ベンチマークの実行からギャップ分析、解決策の提案、一般化のレビュー、実装というサイクルを繰り返す手法だ。過学習を避けるため、LoCoMoやLongMemEval、BEAMといった複数の外部ベンチマークを利用してテストを実施した。客観的な指標に基づく評価が、本番環境に耐えうる品質を担保する。
コーディングから顧客対応まで:数ヶ月後も賢くなるエージェントの設計例
3ヶ月以上稼働するコーディング支援エージェントのプロジェクトでは、セッションを横断した文脈の維持が課題となる。Agent Memoryを組み込むことで、ユーザーが過去に決定した変数命名規則や、好んで使用するパッケージマネージャーの指定を継続的に記憶する。数週間前の会話で「今後はTypeScriptの厳格モードを標準とする」と合意した場合、その設定を新しいタスクでも自動的に適用し続ける。
エージェント型のコードレビュアーに適用すれば、過去に指摘した内容を学習し、同じフィードバックを繰り返す事態を回避する。カスタマーサポート向けのチャットボットに導入した場合、過去の購入履歴や問い合わせの文脈にアクセスして的確な応答を生成する。永続的な記憶の仕組みは、システム開発以外の領域にも応用できる。
1つのエージェントが学習したプロジェクトの固有ルールや設定を、他のエージェントやツールと共有する構成も可能だ。個別エージェント単体での利用から、カスタムハーネス、チーム横断の共有メモリまで、3つのアクセスパターンをサポートする。チーム内でのメモリ共有は、同僚のエージェントが一から学び直す手間を省く効果を持つ。
環境変数からプロジェクトのプロファイルを取得し、セッションIDを指定して会話履歴を取り込むサンプルコードが公開された。特定の情報を直接記憶させる場合はprofile.rememberメソッドを使用し、ユーザーの好みを呼び出す際はprofile.recallメソッドを実行する。現在、Cloudflare Workerバインディングまたは外部エージェント向けのAPI(Application Programming Interface)であるREST APIを経由してアクセスできる。JavaScriptによるAPIの呼び出しは、数行の記述で完結する。
Cloudflareは、データの所有権について明確な方針を打ち出した。マネージドサービスとして運用されるが、保存されたデータは完全にユーザーのものとして扱われ、すべてのメモリはエクスポート可能に設定されている。同社は「長期的な信頼を得る正しい方法は、離脱を容易にし、離脱したくなくなるほど良いものを作り続けること」という哲学を掲げた。AIエージェントの設計競争は今後、コンテキストウィンドウの単純な拡張から、何を覚え・何を忘れるかというアーキテクチャ設計へとシフトしていく。コンテキストの見えない税金を、メモリの外部化と検索パイプラインで構造的に回避する発想において、Cloudflareはインフラ側から先手を打った格好だ。
Sources
- Cloudflare Blog: Introducing Agent Memory