
2026年4月24日、DeepSeek-AIはHugging FaceでDeepSeek-V4シリーズのプレビュー版を公開し、技術報告書「DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence」も提示した。今回の中心は、1.6兆パラメータのDeepSeek-V4-Proと2840億パラメータのDeepSeek-V4-Flashが、どちらも100万トークンのコンテキスト長をうたう点だ。改善は、単に長い入力を受けられることにとどまらない。DeepSeekはV3.2比で、V4-Proの1トークン推論FLOPsを27%、KVキャッシュを10%に抑えたと説明しており、長文推論を「使える価格とメモリ」に近づける設計を前面に出している。
1.6兆パラメータでも、動くのは49BというMoE設計
DeepSeek-V4-Proは総パラメータ数1.6兆、推論時の活性化パラメータ数49BのMixture-of-Expertsモデルとして公開された。小型版のDeepSeek-V4-Flashは総パラメータ数284B、活性化パラメータ数13Bで、両モデルともコンテキスト長は1Mとされる。Hugging Faceのモデルカードでは、ベース版がFP8 Mixed、指示追従版がFP4 + FP8 Mixedと整理され、MoEの専門家パラメータにFP4を使い、それ以外の多くをFP8で扱うと説明されている。
2025年以降の大規模言語モデル競争では、ベンチマークの点数だけでなく、長い会話履歴、巨大なコードベース、複数文書をまたぐ調査をどこまで現実的に処理できるかが競争軸になっている。DeepSeek-V4はこの文脈で、DeepSeekMoEとMulti-Token Predictionを引き継ぎつつ、注意機構と残差接続と最適化手法を差し替えた世代として位置づけられる。技術報告書は、V3系の延長ではあるが、100万トークン文脈を前提にした効率改善を主眼にしたモデルだと読める。
Hugging Faceのモデルカードでは、DeepSeek-V4-Pro、DeepSeek-V4-Flash、各ベースモデルがHugging FaceとModelScopeへのリンク付きで示され、ライセンスはMITと記載されている。記事執筆時点のHugging Face表示では、V4-ProはInference Providerに配備されていない。ローカル実行については重み変換や対話デモの手順をリポジトリ内のinferenceフォルダに誘導しており、今回の公開は軽量APIの即時提供より、重みと技術報告書を伴うプレビューとしての性格が強い。
CSAとHCAで、100万トークン時のFLOPsとKVを削る
1Mトークン文脈の比較で、DeepSeekはV4-ProがDeepSeek-V3.2に対して1トークン推論FLOPsを27%、KVキャッシュを10%に抑えると説明している。さらにV4-Flashでは同じ条件でFLOPsが10%、KVキャッシュが7%になると技術報告書は説明している。大きな文脈長を掲げるモデルは珍しくなくなったが、KVキャッシュが膨らむほど推論メモリと共有プレフィックス再利用の設計が支配的になるため、この比較は単なるスペック表以上の意味を持つ。
DeepSeek-V4の設計上の柱は、Compressed Sparse AttentionとHeavily Compressed Attentionを組み合わせたハイブリッド注意機構である。CSAはシーケンス方向にKVキャッシュを圧縮した上でSparse Attentionを行い、HCAはより強く圧縮したKVキャッシュを使いつつDense Attentionを維持する。技術報告書は、この二つを層ごとに使い分けることで、長いシーケンスで計算量と記憶量が膨らむ問題を抑える構成を説明している。
DeepSeek-V4は注意機構だけでなく、Manifold-Constrained Hyper-ConnectionsとMuon optimizerも導入した。mHCは通常の残差接続を拡張し、層をまたぐ信号伝播の安定性を高める狙いがあるとされる。Muon optimizerは収束を速め、学習安定性を改善する要素として挙げられている。事前学習についてはV4-Flashが32Tトークン、V4-Proが33Tトークンで訓練されたと報告されており、ポストトレーニングでは数学、コード、エージェント、指示追従などの専門モデルをSFTとGRPOで育て、その後オンポリシー蒸留で単一モデルへ統合する二段階構成を採った。
ベンチマークは強いが、読むべきは「Max」の条件
Hugging Faceのモデルカードは、DeepSeek-V4-ProとV4-FlashがNon-think、Think High、Think Maxの3つの推論モードを持つと説明している。Think Maxは推論能力の限界探索向けのモードであり、モデルカードはローカル配備時にThink Maxでは少なくとも384Kトークンのコンテキストウィンドウを推奨している。ベンチマーク表の「DeepSeek-V4-Pro-Max」は、この条件を踏まえて通常応答の性能と切り分けて読む必要がある。
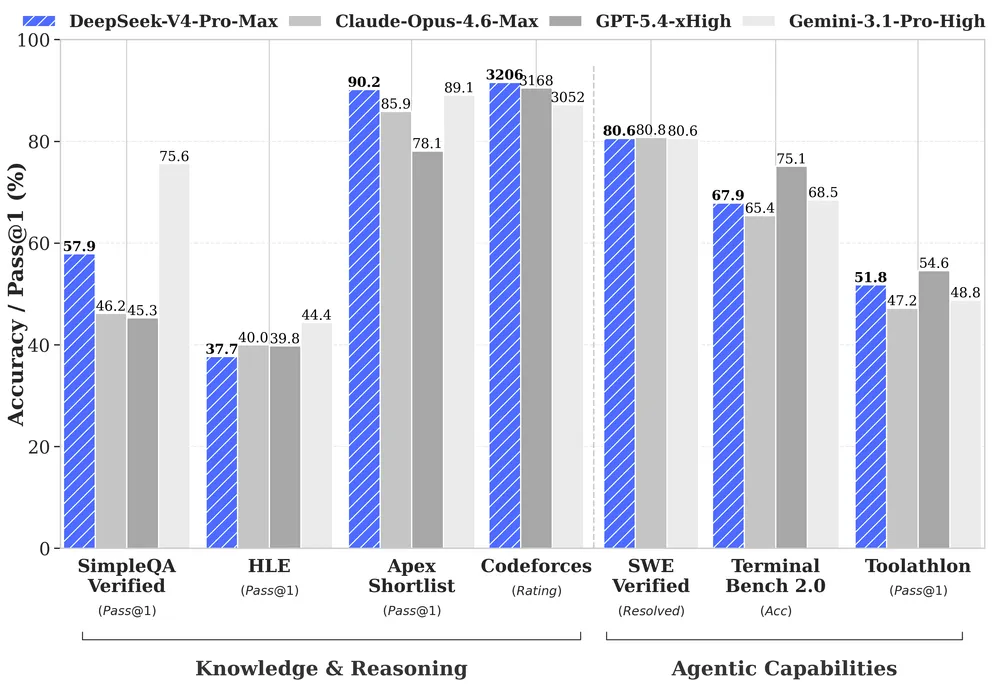
DeepSeek自身の比較表では、DeepSeek-V4-Pro-MaxはLiveCodeBenchで93.5%、Codeforcesで3206、SWE Verifiedで80.6%を示し、MMLU-Proは87.5%、SimpleQA-Verifiedは57.9%、GPQA Diamondは90.1%とされる。同じ表では、Gemini-3.1-Pro HighがMMLU-Pro 91.0%、SimpleQA-Verified 75.6%、GPQA Diamond 94.3%で上回る項目もある。コード、長文、エージェント系の一部でかなり接近した、あるいは項目によって上回る、という読み方が現時点では合っている。
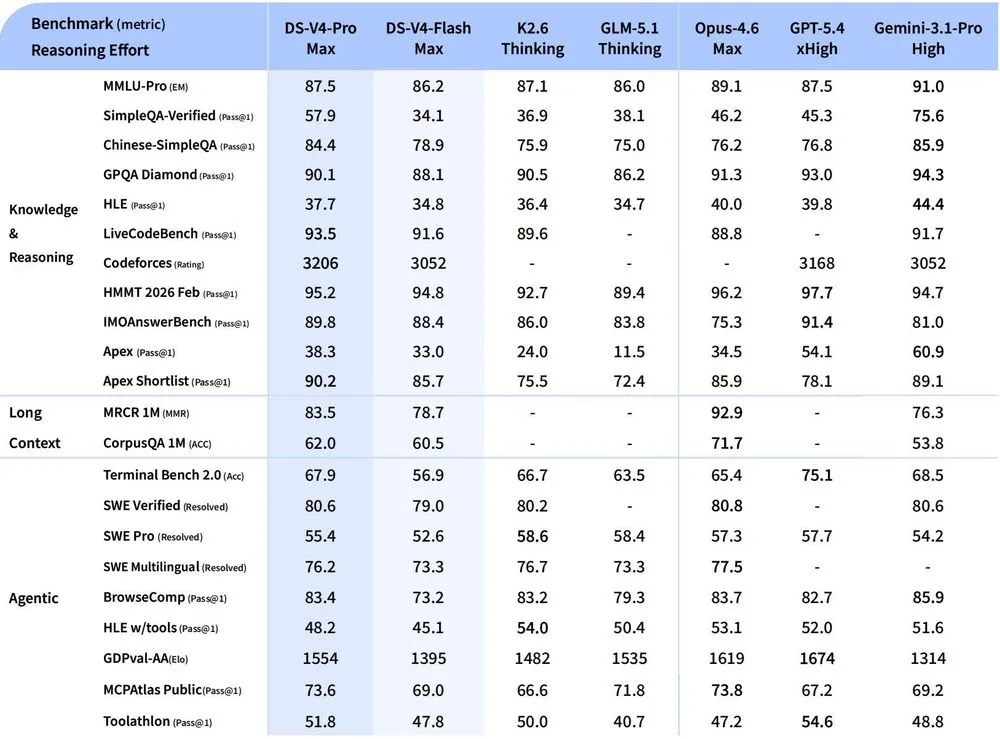
モード別比較を見ると、性能差はさらに分かりやすい。V4-ProのNon-thinkはMMLU-Pro 82.9%、LiveCodeBench 56.8%、SWE Verified 73.6%で、Maxではそれぞれ87.5%、93.5%、80.6%まで上がる。V4-FlashもMaxではCodeforces 3052、LiveCodeBench 91.6%まで伸びるが、SimpleQA-Verifiedは34.1%で、Pro Maxの57.9%とは開きがある。Flashは推論予算を増やすと推論系でProに近づくが、知識系と高難度エージェント処理ではサイズ差が残る、というDeepSeek自身の説明と整合する。
開発者に効くのは、1M入力より運用コストの下げ方である
100万トークンの入力枠は目を引くが、実務で常に最大長を丸ごと投げるわけではない。コードレビュー、法務文書、研究調査、長時間エージェント実行では、長い状態を維持しながら必要な場所に注意を向け、同時にKVキャッシュのコストを抑える必要がある。DeepSeekがオンディスクKVキャッシュ保存、共有プレフィックス再利用、長文注意向けのコンテキスト並列化を報告書に入れているのは、モデル単体の点数より運用面の詰めに踏み込んでいるためである。
プレビュー版のまま本番移行を判断するには、まだ材料が足りない。モデルカードはJinja形式のチャットテンプレートを同梱せず、OpenAI互換形式のメッセージを入力文字列へエンコードする専用Pythonスクリプトを使うと説明している。プロダクション移行を考える開発者にとっては、ツール呼び出し、JSON出力、長文時のレイテンシ、実効コスト、ホスティング要件、量子化後の品質変化を自分のワークロードで測る必要がある。
2026年4月24日の公開で明確になったのは、DeepSeekがV4を「巨大だが安く動くMoE」としてだけでなく、「長文推論の計算資源問題に踏み込む世代」として出してきたことである。V4-Proの1.6兆パラメータという数字は目立つが、実際の差分は49B活性化、FP4/FP8混合、CSA/HCA、オンディスクKVキャッシュといった設計の組み合わせにある。API価格や第三者評価がそろうまでは過大評価も禁物だが、オープンウェイトの長文モデル競争では、コンテキスト長の大きさより「その長さをどれだけ安定して安く使えるか」が次の比較軸になった。
Sources

