テクノロジー
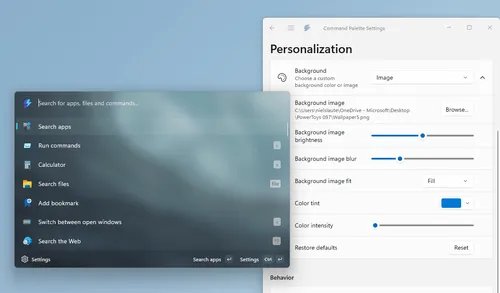
Microsoft PowerToysにマウスの「テレポート」機能CursorWrapと進化したCommand Paletteが登場
Windows 11のユーザー体験(UX)を劇的に向上させるMicrosoftのオープンソース・ユーティリティ群「PowerToys」が、バージョン0.97へとアップデートを果たした。今回のアップデートは、単なるバグ修正 […]
別名: PowerToys
Microsoftが開発する、Windowsパワーユーザー向けのオープンソース・ユーティリティスイート。ウィンドウ配置をカスタマイズするFancyZones、高度なファイル検索、画像リサイズ、キーボードの再マッピングなど、OS標準機能を補完・拡張する多くのツールが含まれている。
Windows 11のユーザー体験(UX)を劇的に向上させるMicrosoftのオープンソース・ユーティリティ群「PowerToys」が、バージョン0.97へとアップデートを果たした。今回のアップデートは、単なるバグ修正 […]
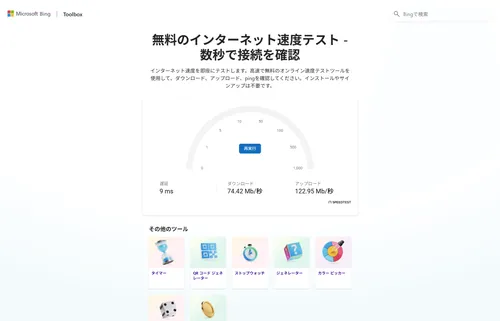
Windows 11に、インターネットの接続速度をタスクバーから直接測定できる新機能が搭載される可能性が浮上した。Microsoftの公式発表はないものの、最新のプレビュー版OSからその存在が明らかになった。しかし、その […]
Background The increasing application of generative artificial intelligence large language models (LLMs) in various fields, including dentistry, raises questions about their accuracy. Objective This study aims to comparatively evaluate the answers provided by 4 LLMs, namely Bard (Google LLC), ChatGPT-3.5 and ChatGPT-4 (OpenAI), and Bing Chat (Microsoft Corp), to clinically relevant questions from the field of dentistry. Methods The LLMs were queried with 20 open-type, clinical dentistry–related questions from different disciplines, developed by the respective faculty of the School of Dentistry, European University Cyprus. The LLMs’ answers were graded 0 (minimum) to 10 (maximum) points against strong, traditionally collected scientific evidence, such as guidelines and consensus statements, using a rubric, as if they were examination questions posed to students, by 2 experienced faculty members. The scores were statistically compared to identify the best-performing model using the Friedman and Wilcoxon tests. Moreover, the evaluators were asked to provide a qualitative evaluation of the comprehensiveness, scientific accuracy, clarity, and relevance of the LLMs’ answers. Results Overall, no statistically significant difference was detected between the scores given by the 2 evaluators; therefore, an average score was computed for every LLM. Although ChatGPT-4 statistically outperformed ChatGPT-3.5 (P=.008), Bing Chat (P=.049), and Bard (P=.045), all models occasionally exhibited inaccuracies, generality, outdated content, and a lack of source references. The evaluators noted instances where the LLMs delivered irrelevant information, vague answers, or information that was not fully accurate. Conclusions This study demonstrates that although LLMs hold promising potential as an aid in the implementation of evidence-based dentistry, their current limitations can lead to potentially harmful health care decisions if not used judiciously. Therefore, these tools should not replace the dentist’s critical thinking and in-depth understanding of the subject matter. Further research, clinical validation, and model improvements are necessary for these tools to be fully integrated into dental practice. Dental practitioners must be aware of the limitations of LLMs, as their imprudent use could potentially impact patient care. Regulatory measures should be established to oversee the use of these evolving technologies.
Summary Background The increasing utilization of large language models (LLMs) in Generative Artificial Intelligence across various medical and dental fields, and specifically orthodontics, raises questions about their accuracy. Objective This study aimed to assess and compare the answers offered by four LLMs: Google’s Bard, OpenAI’s ChatGPT-3.5, and ChatGPT-4, and Microsoft’s Bing, in response to clinically relevant questions within the field of orthodontics. Materials and methods Ten open-type clinical orthodontics-related questions were posed to the LLMs. The responses provided by the LLMs were assessed on a scale ranging from 0 (minimum) to 10 (maximum) points, benchmarked against robust scientific evidence, including consensus statements and systematic reviews, using a predefined rubric. After a 4-week interval from the initial evaluation, the answers were reevaluated to gauge intra-evaluator reliability. Statistical comparisons were conducted on the scores using Friedman’s and Wilcoxon’s tests to identify the model providing the answers with the most comprehensiveness, scientific accuracy, clarity, and relevance. Results Overall, no statistically significant differences between the scores given by the two evaluators, on both scoring occasions, were detected, so an average score for every LLM was computed. The LLM answers scoring the highest, were those of Microsoft Bing Chat (average score = 7.1), followed by ChatGPT 4 (average score = 4.7), Google Bard (average score = 4.6), and finally ChatGPT 3.5 (average score 3.8). While Microsoft Bing Chat statistically outperformed ChatGPT-3.5 (P-value = 0.017) and Google Bard (P-value = 0.029), as well, and Chat GPT-4 outperformed Chat GPT-3.5 (P-value = 0.011), all models occasionally produced answers with a lack of comprehensiveness, scientific accuracy, clarity, and relevance. Limitations The questions asked were indicative and did not cover the entire field of orthodontics. Conclusions Language models (LLMs) show great potential in supporting evidence-based orthodontics. However, their current limitations pose a potential risk of making incorrect healthcare decisions if utilized without careful consideration. Consequently, these tools cannot serve as a substitute for the orthodontist’s essential critical thinking and comprehensive subject knowledge. For effective integration into practice, further research, clinical validation, and enhancements to the models are essential. Clinicians must be mindful of the limitations of LLMs, as their imprudent utilization could have adverse effects on patient care.
Highlights The study presents a novel framework for remote consultation and lung and colon cancer classification, leveraging blockchain technology and Microsoft Azure cloud services to ensure data privacy and security. The proposed framework achieves an impressive accuracy of 100% for lung and colon cancer classification using advanced machine learning models, demonstrating its potential to improve diagnostic accuracy and streamline cancer care. What are the main findings? Effective Cancer Classification: The framework effectively classifies lung and colon cancer using state-of-the-art machine learning models, achieving high accuracy, precision, recall, and F1-score. Enhanced Data Security: Blockchain technology and Microsoft Azure cloud services provide a secure and transparent environment for data storage, access, and sharing, ensuring patient privacy and data integrity. What is the implication of the main finding? Improved Diagnostic Efficiency: The proposed framework has the potential to significantly improve the efficiency of lung and colon cancer diagnosis by enabling remote consultations and providing accurate and timely results. Enhanced Patient Outcomes: By improving diagnostic accuracy and streamlining the cancer care process, this framework can contribute to better patient outcomes and reduce the overall burden of lung and colon cancers. Abstract Background: The global healthcare system faces challenges in diagnosing and managing lung and colon cancers, which are significant health burdens. Traditional diagnostic methods are inefficient and prone to errors, while data privacy and security concerns persist. Objective: This study aims to develop a secure and transparent framework for remote consultation and classification of lung and colon cancer, leveraging blockchain technology and Microsoft Azure cloud services. Dataset and Features: The framework utilizes the LC25000 dataset, containing 25,000 histopathological images, for training and evaluating advanced machine learning models. Key features include secure data upload, anonymization, encryption, and controlled access via blockchain and Azure services. Methods: The proposed framework integrates Microsoft Azure’s cloud services with a permissioned blockchain network. Patients upload CT scans through a mobile app, which are then preprocessed, anonymized, and stored securely in Azure Blob Storage. Blockchain smart contracts manage data access, ensuring only authorized specialists can retrieve and analyze the scans. Azure Machine Learning is used to train and deploy state-of-the-art machine learning models for cancer classification. Evaluation Metrics: The framework’s performance is evaluated using metrics such as accuracy, precision, recall, and F1-score, demonstrating the effectiveness of the integrated approach in enhancing diagnostic accuracy and data security. Results: The proposed framework achieves an impressive accuracy of 100% for lung and colon cancer classification using DenseNet, ResNet50, and MobileNet models with different split ratios (70–30, 80–20, 90–10). The F1-score and k-fold cross-validation accuracy (5-fold and 10-fold) also demonstrate exceptional performance, with values exceeding 99.9%. Real-time notifications and secure remote consultations enhance the efficiency and transparency of the diagnostic process, contributing to better patient outcomes and streamlined cancer care management.
Artificial intelligence (AI) chatbots are emerging educational tools for students in healthcare science. However, assessing their accuracy is essential prior to adoption in educational settings. This study aimed to assess the accuracy of predicting the correct answers from three AI chatbots (ChatGPT-4, Microsoft Copilot and Google Gemini) in the Italian entrance standardized examination test of healthcare science degrees (CINECA test). Secondarily, we assessed the narrative coherence of the AI chatbots’ responses (i.e., text output) based on three qualitative metrics: the logical rationale behind the chosen answer, the presence of information internal to the question, and presence of information external to the question. An observational cross-sectional design was performed in September of 2023. Accuracy of the three chatbots was evaluated for the CINECA test, where questions were formatted using a multiple-choice structure with a single best answer. The outcome is binary (correct or incorrect). Chi-squared test and a post hoc analysis with Bonferroni correction assessed differences among chatbots performance in accuracy. A p-value of < 0.05 was considered statistically significant. A sensitivity analysis was performed, excluding answers that were not applicable (e.g., images). Narrative coherence was analyzed by absolute and relative frequencies of correct answers and errors. Overall, of the 820 CINECA multiple-choice questions inputted into all chatbots, 20 questions were not imported in ChatGPT-4 (n = 808) and Google Gemini (n = 808) due to technical limitations. We found statistically significant differences in the ChatGPT-4 vs Google Gemini and Microsoft Copilot vs Google Gemini comparisons (p-value < 0.001). The narrative coherence of AI chatbots revealed “Logical reasoning” as the prevalent correct answer (n = 622, 81.5%) and “Logical error” as the prevalent incorrect answer (n = 40, 88.9%). Our main findings reveal that: (A) AI chatbots performed well; (B) ChatGPT-4 and Microsoft Copilot performed better than Google Gemini; and (C) their narrative coherence is primarily logical. Although AI chatbots showed promising accuracy in predicting the correct answer in the Italian entrance university standardized examination test, we encourage candidates to cautiously incorporate this new technology to supplement their learning rather than a primary resource. Not required.
Background Large language models (LLMs), such as ChatGPT-4, Gemini, and Microsoft Copilot, have been instrumental in various domains, including healthcare, where they enhance health literacy and aid in patient decision-making. Given the complexities involved in breast imaging procedures, accurate and comprehensible information is vital for patient engagement and compliance. This study aims to evaluate the readability and accuracy of the information provided by three prominent LLMs, ChatGPT-4, Gemini, and Microsoft Copilot, in response to frequently asked questions in breast imaging, assessing their potential to improve patient understanding and facilitate healthcare communication. Methodology We collected the most common questions on breast imaging from clinical practice and posed them to LLMs. We then evaluated the responses in terms of readability and accuracy. Responses from LLMs were analyzed for readability using the Flesch Reading Ease and Flesch-Kincaid Grade Level tests and for accuracy through a radiologist-developed Likert-type scale. Results The study found significant variations among LLMs. Gemini and Microsoft Copilot scored higher on readability scales (p < 0.001), indicating their responses were easier to understand. In contrast, ChatGPT-4 demonstrated greater accuracy in its responses (p < 0.001). Conclusions While LLMs such as ChatGPT-4 show promise in providing accurate responses, readability issues may limit their utility in patient education. Conversely, Gemini and Microsoft Copilot, despite being less accurate, are more accessible to a broader patient audience. Ongoing adjustments and evaluations of these models are essential to ensure they meet the diverse needs of patients, emphasizing the need for continuous improvement and oversight in the deployment of artificial intelligence technologies in healthcare.