
テクノロジー
別名: CUDA, CUDAコア
NVIDIAが開発した、GPUを汎用計算(GPGPU)に利用するためのプラットフォーム。AI開発や科学シミュレーションにおいて事実上の標準(デファクトスタンダード)となっており、膨大なライブラリやコミュニティの存在がNVIDIAの強力な競争優位性(エコシステムの壁)を形成している。
Writing GPU kernels is a challenging task and critical for AI systems'efficiency. It is also highly iterative: domain experts write code and improve performance through execution feedback. Moreover, it presents verifiable rewards like correctness and speedup, making it a natural environment to apply Reinforcement Learning (RL). To explicitly incorporate the iterative nature of this process into training, we develop a flexible multi-turn RL recipe that addresses unique challenges encountered in real-world settings, such as learning from long trajectories and effective reward attribution across turns. We present Kevin - K(ernel D)evin, the first model trained with multi-turn RL for CUDA kernel generation and optimization. In our evaluation setup, Kevin shows significant gains over its base model (QwQ-32B), improving correctness of generated kernels (in pure CUDA) from 56% to 82% and mean speedup from 0.53x to 1.10x of baseline (PyTorch Eager), and surpassing frontier models like o4-mini (0.78x). Finally, we study its behavior across test-time scaling axes: we found scaling serial refinement more beneficial than parallel sampling. In particular, when given more refinement turns, Kevin shows a higher rate of improvement.
Class imbalance problems frequently occur in real-world tasks, and conventional deep learning algorithms are well known for performance degradation on imbalanced training datasets. To mitigate this problem, many approaches have aimed to balance among given classes by re-weighting or re-sampling training samples. These re-balancing methods increase the impact of minority classes and reduce the influence of majority classes on the output of models. However, the extracted representations may be of poor quality owing to the limited number of minority samples. To handle this restriction, several methods have been developed that increase the representations of minority samples by leveraging the features of the majority samples. Despite extensive recent studies, no deep analysis has been conducted on determination of classes to be augmented and strength of augmentation has been conducted. In this study, we first investigate the correlation between the degree of augmentation and class-wise performance, and find that the proper degree of augmentation must be allocated for each class to mitigate class imbalance problems. Motivated by this finding, we propose a simple and efficient novel curriculum, which is designed to find the appropriate per-class strength of data augmentation, called CUDA: CUrriculum of Data Augmentation for long-tailed recognition. CUDA can simply be integrated into existing long-tailed recognition methods. We present the results of experiments showing that CUDA effectively achieves better generalization performance compared to the state-of-the-art method on various imbalanced datasets such as CIFAR-100-LT, ImageNet-LT, and iNaturalist 2018.
A critical challenge to making quantum computers work in practice is effectively combining them with classical computing resources. From the classical side of hybrid algorithms and integrated application workflows to decoding syndromes for quantum error correction, tightly coupled high performance classical computing will be important for many of the functions required to realize useful quantum computing. A key tool for enabling research and application development is a programming model and software toolchain which allow researchers to straightforwardly co-program classical and quantum computers and leverage the best tools available for each. NVIDIA CUDA Quantum is a single-source programming model in C++ and Python for heterogeneous quantum-classical computing. The CUDA Quantum platform provides several advantages and new capabilities that enable users to get more out of quantum processors. Here, we present CUDA Quantum and demonstrate several use cases including Variational Quantum Eigensolver (VQE) where it provides a significant (287x) performance and capability benefit over existing quantum programming.
The exponential growth in demand for GPU computing resources has created an urgent need for automated CUDA optimization strategies. While recent advances in LLMs show promise for code generation, current SOTA models achieve low success rates in improving CUDA speed. In this paper, we introduce CUDA-L1, an automated reinforcement learning framework for CUDA optimization that employs a novel contrastive RL algorithm. CUDA-L1 achieves significant performance improvements on the CUDA optimization task: trained on A100, it delivers an average speedup of x3.12 with a median speedup of x1.42 against default baselines over across all 250 CUDA kernels of KernelBench, with peak speedups reaching x120. In addition to the default baseline provided by KernelBench, CUDA-L1 demonstrates x2.77 over Torch Compile, x2.88 over Torch Compile with reduce overhead, x2.81 over CUDA Graph implementations, and x7.72 over cuDNN libraries. Furthermore, the model also demonstrates portability across different GPU architectures. Beyond these benchmark results, CUDA-L1 demonstrates several properties: it 1) discovers a variety of CUDA optimization techniques and learns to combine them strategically to achieve optimal performance; 2) uncovers fundamental principles of CUDA optimization, such as the multiplicative nature of optimizations; 3) identifies non-obvious performance bottlenecks and rejects seemingly beneficial optimizations that actually harm performance. The capabilities demonstrate that, RL can transform an initially poor-performing LLM into an effective CUDA optimizer through speedup-based reward signals alone, without human expertise or domain knowledge. This paradigm opens possibilities for automated optimization of CUDA operations, and holds promise to substantially promote GPU efficiency and alleviate the rising pressure on GPU computing resources. Project: deepreinforce-ai.github.io/cudal1_blog

Ubuntuは、AI機能の一括オフ機能は複雑で実装できないと明言し、Snap confinementとローカル推論による透明性を選択した。これは「UbuntuをAI製品にしない」という宣言であり、ユーザーの不信感に対し、具体的な設計選択で応えるものだ。また、Implicit AIとExplicit AIの二種類に分類し、OS機能として溶け込むAIと、ユーザーが呼び出すAIを区別している。

SpaceXはIPOに向けたS-1登録書で、将来の大規模設備投資の一部として自社GPU製造を挙げ、チップ供給の不安定さを投資家へのリスクとして開示した。これはNVIDIA依存からの脱却というより、StarlinkやxAI、宇宙データセンター構想など、Musk氏傘下の複数事業における計算資源の安定確保を目的とした垂直統合オプションである。Intel 14Aプロセスを用いたTerafab構想と連携し、AIアクセラレータの内製化を目指すものの、その実現には大きな技術的・経済的リスクが伴う。

カーネル最適化は長年、GPUプログラミングの深い知識を持つ一握りの専門家が支配してきた領域だ。NVIDIAのCUDAでAttentionカーネルを書けば数千行に及び、2019年にOpenAIが発表したTritonで約12 […]

NVIDIAが、急速に立ち上がりつつある自律型AIエージェント市場における自らの主導権を確固たるものにするため、新たなオープンソースプラットフォーム「NemoClaw」のローンチ準備を急ピッチで進めていることがWired […]

現代のディープラーニングインフラストラクチャは、事実上NVIDIAのCUDAアーキテクチャの上に構築されている。GPUの演算能力を限界まで引き出すCUDAカーネルの最適化は、AI開発における最重要課題の一つだ。しかし、高 […]
NVIDIAが発表した2026会計年度第4四半期(2025年11月〜2026年1月)決算は、同社がもはや単なる半導体メーカーではなく、次世代デジタル経済の基盤を完全に支配するインフラストラクチャー企業として君臨しているこ […]

人工知能(AI)ハードウェア市場において絶対的な支配力を誇るNVIDIAに対し、新たな陣営が包囲網を敷きつつある。米国時間2026年2月24日、AIチップスタートアップのSambaNova Systemsは、総額3億5, […]

Meta Platformsは、AIインフラの構築においてNVIDIAとの提携を劇的に拡大し、数百万規模の次世代GPU「Vera Rubin」およびCPU「Grace」を購入する契約を締結した。特筆すべきは、MetaがN […]

かつて「オープンソース界の巨人」として君臨したIntelの姿勢が、劇的な転換期を迎えている。2025年末から2026年初頭にかけて、同社は公式に維持管理していた20以上のGitHubリポジトリを次々とアーカイブ化(事実上 […]
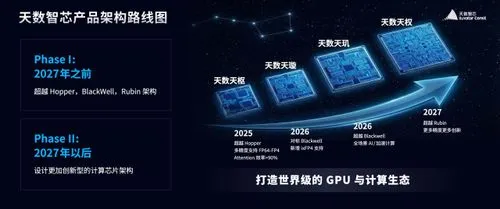
中国の半導体業界から、(実現するかは別として)野心的な計画が浮上した。 2026年1月26日、中国のGPUスタートアップであるIluvatar CoreX(天数智芯)は、2027年までにNVIDIAの次世代アーキテクチャ […]

この出来事は、後の世において、テクノロジー業界における歴史的な瞬間だったと記録されることになるかもしれない。 発端は、Redditのとあるスレッドへの投稿だった。自律型AIコーディングプラットフォームである「Claude […]

AI(人工知能)の進化速度は、シリコンチップの物理的限界を試し続けている。2026年1月15日、半導体業界に衝撃を与える一つの発表が行われた。オープンソースのプロセッサアーキテクチャ「RISC-V」の旗手であるSiFiv […]

米国の半導体大手NVIDIAが、中国市場向けの最新AIチップ「H200」の販売において、かつてないほど厳しい取引条件を突きつけていることが明らかになった。複数の関係者の証言によると、同社は中国の顧客に対し、製品出荷前の「 […]

2023年、NVIDIAのCEOであるJensen Huang氏は、Amazon Web Services(AWS)などの巨大クラウドプロベンダー(ハイパースケーラー)に対抗しうる、独自のAIスーパーコンピューティング・ […]

Alphabet(Google)が、長年のライバルであり広告市場で競合するMeta Platforms(旧Facebook)と手を組み、AI半導体市場の絶対王者NVIDIAの牙城を崩そうとしていることがReutersによ […]

米国大統領Donald Trumpは、自身のSNSプラットフォーム「Truth Social」において、米NVIDIAの高性能AIチップ「H200」について、中国の「承認された顧客」への販売を許可する方針を明らかにした。 […]

サンディエゴで開催された世界最高峰のAI学会「NeurIPS(Neural Information Processing Systems)」において、NVIDIAは技術業界、とりわけモビリティとロボティクス分野に衝撃を与 […]

AI半導体市場における「一強」体制に、地殻変動の前兆とも呼べる亀裂が入りつつある。 米国時間2025年11月25日、The Informationが報じたニュースは、シリコンバレーのみならず、世界の投資家と技術者に衝撃を […]

AI(人工知能)半導体市場が、熱狂と警戒感の狭間で揺れている。著名投資家が「バブル」への警鐘を鳴らす一方で、未来の成長を信じる巨額の資金が新たな挑戦者へと流れ込む。このダイナミックな市場の動きを象徴する出来事が起きた。A […]