
現代のディープラーニングインフラストラクチャは、事実上NVIDIAのCUDAアーキテクチャの上に構築されている。GPUの演算能力を限界まで引き出すCUDAカーネルの最適化は、AI開発における最重要課題の一つだ。しかし、高度なハードウェアの専門知識とプロファイリングスキルを要求されるこの作業は、長らく一握りの専門エンジニアに依存するか、静的なヒューリスティクスで動作するコンパイラに頼るしかなかった。
ByteDance Seedと清華大学(Tsinghua AIR)の研究チームは、この領域に決定的な一石を投じた。彼らが発表した論文「CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation」は、大規模言語モデル(LLM)に自律的な環境探索と強化学習(RL)を行わせることで、広く普及している標準コンパイラ「torch.compile」の性能を上回るCUDAカーネルを自動生成するシステムを提示している。この成果は、AIモデルのパフォーマンスチューニングというプロセスそのものを根本から覆す可能性を秘めたものだ。
静的コンパイラと汎用LLMの限界
機械学習エンジニアリングにおいて、PyTorchのコードをGPU上で効率的に実行するための標準的な手段はtorch.compileである。このツールは、計算グラフを解析し、あらかじめ定義されたルールに基づいてカーネルフュージョン(複数の演算を一つにまとめること)などの最適化を行う。堅実な性能向上を提供する一方で、ルールベースのアプローチには明確な限界がある。ハードウェアの特性に合わせたきめ細やかなメモリアクセスパターンや、未知の演算の組み合わせに対する最適化においては、人間の専門家が手作業でチューニングしたコードに及ばないことが多い。
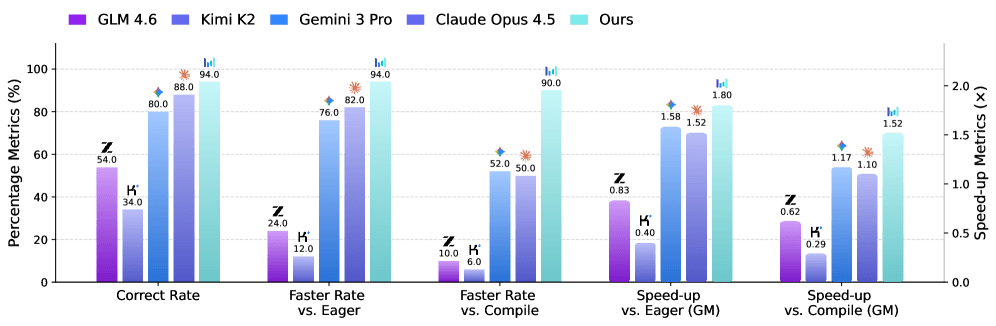
一方で、ソフトウェア開発の領域で目覚ましい成果を上げている最先端のLLMも、CUDAカーネルの生成においては苦戦を強いられてきた。ByteDanceの研究チームがCUDAカーネル生成のベンチマークセット「KernelBench」を用いて行った検証によると、Claude Opus 4.5やGemini 3 Proといった最高峰のプロプライエタリモデルであっても、torch.compileの実行速度をコンスタントに上回ることはできなかった。具体的には、これらのモデルのPass Rate(正しく動作するコードを生成する割合)は90%を超えているものの、Faster Rate(ベースラインよりも高速なコードを生成する割合)は60%台にとどまっていた。
一般的なプログラミングにおいて人間に匹敵するコードを書けるAIが、なぜCUDAでは性能を発揮できないのか。その理由は、LLMの事前学習データセットにおいて、CUDAカーネルに関するコードが全体の0.01%未満にすぎないからである。この圧倒的なデータ不足が、LLMのハードウェアレベルの最適化能力を制限していた。
人間の教師データに依存しない強化学習システム
この制約を突破するため、CUDA Agentは人間の専門家が書いた正解データを模倣するアプローチを放棄した。代わりに、コードを生成し、実際のGPU環境でコンパイル・実行し、プロファイリングツールからフィードバックを得て修正する、というエンジニアの反復的な開発プロセスをAI自身に実行させる自律的なループを構築した。
システムは3つの主要な要素で構成されている。
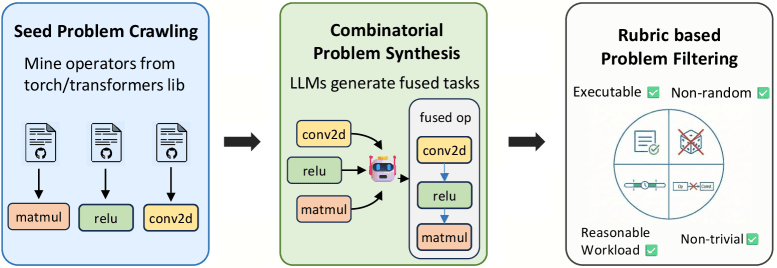
一つ目は、データ合成パイプラインによるタスクの大規模生成である。強化学習を機能させるには、多様で膨大な課題が必要となる。研究チームはPyTorchやTransformersのライブラリから基本的な演算子を抽出し、それらをLLMに組み合わせて合成タスクを作成させた。その後、実際にコンパイル可能か、実行時間が適切な範囲か(1ミリ秒から100ミリ秒)、結果が決定論的かといった厳格な基準で実行ベースのフィルタリングを実施した。結果として、6000個の訓練用データセット「CUDA-Agent-Ops-6K」が構築された。これにより、手作業でデータを用意するボトルネックが解消された。
二つ目は、厳格な隔離環境と堅牢な報酬設計に基づくエージェントループである。AIエージェントには、コードの編集、シェルコマンドの実行、プロファイリングスクリプトの実行といったツール群が与えられ、これらを用いて最大200回の対話を繰り返しながらカーネルを最適化していく。ここで研究チームは、強化学習の報酬として単なる「ベースラインに対する速度向上比率」を使用するのではなく、マイルストーンに基づく離散的なスコアを採用した。単純な速度向上率を報酬にすると、エージェントは最適化の余地が大きい簡単なタスクにばかり注力し、複雑なタスクを放棄する。正しい結果を出し、かつ既存のコンパイラに対して有意な速度向上(5%以上)を達成したかどうかに基づいて報酬(-1, 1, 2, 3)を付与することで、エージェントは着実に高度な最適化を学習していった。また、ハッキング(チート行動)を防ぐため、システム関数へのアクセス制限や複数入力でのテスト検証が組み込まれている。
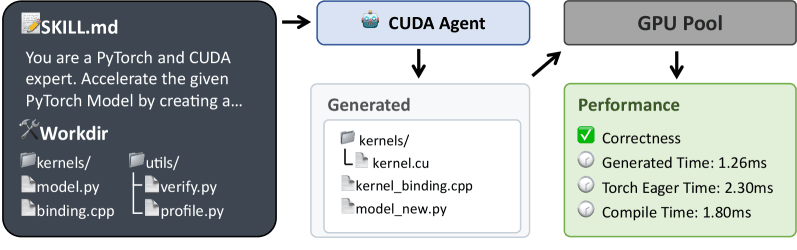
三つ目は、長いコンテキストを伴う強化学習の安定化技術である。事前学習データにおけるCUDAコードの割合が極端に低いため、ベースモデルにそのまま強化学習を適用すると、わずか17ステップでポリシーが崩壊し、意味をなさないコードを出力し続ける状態に陥った。研究チームはこの訓練の不安定性を解消するため、Rejection Fine-Tuning(RFT)によるアクターモデルの初期化と、Criticモデルの価値事前学習(Value Pretraining)というウォームアッププロセスを導入した。一定水準以上の品質を持つ探索軌跡のみを用いてモデルの初期状態を整えることで、システムは長期にわたる強化学習の過程を安定して完走することが可能になった。
KernelBenchにおける性能と具体的な最適化の手法
これらのアーキテクチャの統合により、CUDA AgentはKernelBenchにおいて高いパフォーマンスを記録した。
ベースモデルとして採用されたSeed1.6(23Bのアクティブパラメータを持つMoEモデル)は、初期状態ではtorch.compileと比較した幾何平均での速度向上率(Speed-up)が0.69倍であり、コンパイラよりも遅いコードしか生成できなかった。しかし、CUDA Agentとして強化学習を経た後は、全体で2.11倍という数値を記録した。難易度が最も高いLevel-3のスプリットにおいても、Claude Opus 4.5の1.46倍、Gemini 3 Proの1.42倍に対し、CUDA Agentは1.52倍を達成し、他のモデルを引き離している。Faster Rateにおいても、Level-1およびLevel-2で100%、Level-3で92%を記録し、ほぼすべてのタスクでtorch.compileを上回った。
CUDA Agentがどのようにしてこの最適化を実現しているのか、論文に示されたケーススタディを分析すると、人間が実践するパフォーマンス・エンジニアリングの手法を自律的に適用していることがわかる。
Level 1のタスクでは、ベクトルから構築された対角行列と別の密行列を掛け合わせる演算が行われた。標準的なアプローチでは対角行列をメモリ上に展開して汎用的な行列積を実行するが、CUDA Agentは背後にある代数的な構造を見抜き、演算を行ごとのスカラー乗算に単純化した。中間生成物としての対角行列の作成そのものをスキップすることで、時間計算量を大幅に削減し、メモリトラフィックを減少させている。
Level 2のタスクでは、行列積、除算、加算、スケーリングが連続する計算グラフが対象となった。ここでもCUDA Agentは、計算の順序を再構築している。行列の掛け算とその後の縮約(リダクション)という処理を、重み行列の列方向の縮約とドット積に変換した。その上で、複数の演算を一つのCUDAカーネル内に統合(カーネルフュージョン)し、グローバルメモリへの中間データの書き込みを回避している。
最も複雑なLevel 3のResNet BasicBlockのケースでは、CUDA Agentはハードウェアの仕様に踏み込んだ最適化を展開した。演算対象のGPUがTensor Coresを搭載していることを前提とし、計算精度をTF32に設定することでスループットを最大化した。さらに、NVIDIAが提供するcuDNNライブラリのAPIを直接呼び出し、畳み込み、バイアス加算、ReLU活性化を単一のライブラリコール内で実行させることで、カーネルの起動オーバーヘッドを削ぎ落としている。
ハードウェア経済からソフトウェア経済への転換
これらの成果は、NVIDIAを中心とする現在のハードウェア経済の構造に直接的な影響を与えるものだ。
AIモデルのトレーニングと推論にかかるインフラコストは業界全体の大きな課題である。企業はパフォーマンスを確保するために次々と最新のGPUに投資を続けているが、その背後には「ソフトウェア側での最適化がハードウェアの進化に追いついていない」という事実が横たわっている。手作業によるCUDAカーネルの最適化は膨大な人的リソースを消費し、標準コンパイラによる自動化には天井があるため、企業は計算リソースを余分に投入して力技でスループットを維持している。
CUDA Agentの登場が示唆するのは、実環境でのプロファイリングを組み合わせた強化学習によって、既存のハードウェアから引き出せるパフォーマンスの余白(ヘッドルーム)をソフトウェア側で大幅に埋められるということである。コンパイラ以下の性能だったベースモデルが、人間のラベル付けなしにトップエンジニアレベルのチューニング手法を自律的に獲得したことは、パフォーマンス向上の手段がシリコンの微細化やハードウェアの増強に限定されないことを証明している。
これまで専門チームが数ヶ月を費やして特定のニューラルネットワークのボトルネックを解消していた最適化プロセスが、AIエージェントによって数時間から数日で実行されるようになる。これにより、AI開発企業はより少ないGPU台数で同等のトレーニング速度を実現でき、データセンターの運用マージンは再定義される。ByteDanceと清華大学によるこの研究は、膨張し続ける計算リソースの需要に対し、自律的なソフトウェアエンジニアリングという新たな解を提示している。
論文