Googleは「Google Cloud Next 2026」において、同社のカスタムシリコンであるTensor Processor Unit(TPU)の第8世代モデルを発表した。最大の焦点は、従来の単一アーキテクチャ路線から転換し、AIモデルの学習(Training)に特化した「TPU 8t」と、推論(Inference)に特化した「TPU 8i」という2つの独立したチップを市場に投入したことである。
これまでGoogleは、第7世代「Ironwood TPU」において、学習と推論の双方をカバーする巨大な汎用プラットフォームを提供してきた。しかし、自律的な推論と実行を繰り返し、環境から学習する「AIエージェント」の台頭により、インフラストラクチャに対する要求水準は劇的に変化している。数兆パラメータ規模のフロンティアモデルの学習に必要なスループットと、複雑な推論タスクを低遅延で処理する推論用メモリ帯域幅は、もはや単一のハードウェア設計で最適化できる限界を超えつつある。
Google DeepMindとの共同設計によって生み出されたTPU 8tとTPU 8iは、この「エージェント時代(Agentic Era)」特有の要件に対するGoogleの技術的解答だ。NVIDIAが汎用性の高いGPUで市場を席巻する中、Googleは用途特化による「パフォーマンスと電力効率の最大化」という独自のアプローチをさらに深化させている。
TPU 8t:フロンティアモデルの学習時間を数ヶ月から数週間へ圧縮
TPU 8tは、大規模な事前学習やエンベディングを多用するワークロードを想定した「学習特化型」のアーキテクチャである。巨大なコンピューティングスループットとスケールアップ帯域幅を提供し、AI開発のサイクルを大幅に短縮するよう設計されている。
大規模クラスタリングと「Virgo Network」による線形スケーリング
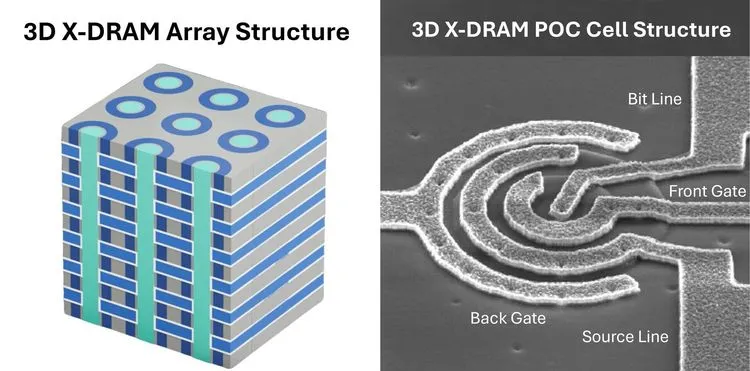
TPU 8tの単一スーパーポッドは、前世代の9,216個から増加し、最大9,600個のチップと2ペタバイトの共有広帯域メモリ(HBM)で構成される。このクラスタは、チップ間帯域幅を前世代の2倍に拡張し、ポッドあたり121 EFlops(FP4)というIronwoodの約3倍の演算性能を実現している。
さらに重要なのは、新しいデータセンターファブリック「Virgo Network」とJAX、Pathwaysソフトウェアスタックの組み合わせにより、単一の論理クラスタ内で最大100万個のチップまでほぼ線形にスケールする能力を備えている点である。このVirgo Networkの帯域幅目標は、数兆パラメータ規模のモデル学習における並列処理の要件から逆算して導き出されたものであり、次世代の巨大モデルの学習においても通信のボトルネックを最小限に抑える設計となっている。
97%超の「Goodput」と量子化技術による圧倒的な効率化
数万個のチップを同時に稼働させる大規模学習では、ハードウェア障害による計算の中断が致命的な遅延をもたらす。TPU 8tは、ハードウェアの生性能だけでなく「Goodput(システムが有用な計算を継続している時間の割合)」を97%以上に引き上げることに注力している。
リアルタイムのテレメトリ監視、障害の発生したICIリンクを自動的に検知・迂回するルーティング機能、そして人間の介入なしにハードウェア構成を再構築するOptical Circuit Switching(OCS)を実装することで、障害時のチェックポイント再開による無駄な時間を徹底的に排除している。
また、LLMのルックアップに特有の不規則なメモリアクセスを処理する専用アクセラレータ「SparseCore」と、ネイティブな4ビット浮動小数点(FP4)演算を導入している。量子化(Quantization)と呼ばれるこのプロセスによってパラメータあたりのビット数を減らすことで、精度を維持したままモデルを圧縮し、より少ないメモリフットプリントで巨大なモデルを学習させることが可能になる。結果として、大規模学習における1ドルあたりのパフォーマンスはIronwoodと比較して最大2.7倍に向上した。
TPU 8i:エージェントの自律思考を支える低遅延推論エンジン
一方、推論と実行に特化したTPU 8iは、AIエージェントが相互に連携し、複雑なタスクを反復的に処理する際の遅延(レイテンシ)を極限まで削ぎ落とすことに特化している。
「メモリの壁」を打破するSRAMの大容量化とAxion CPUの統合
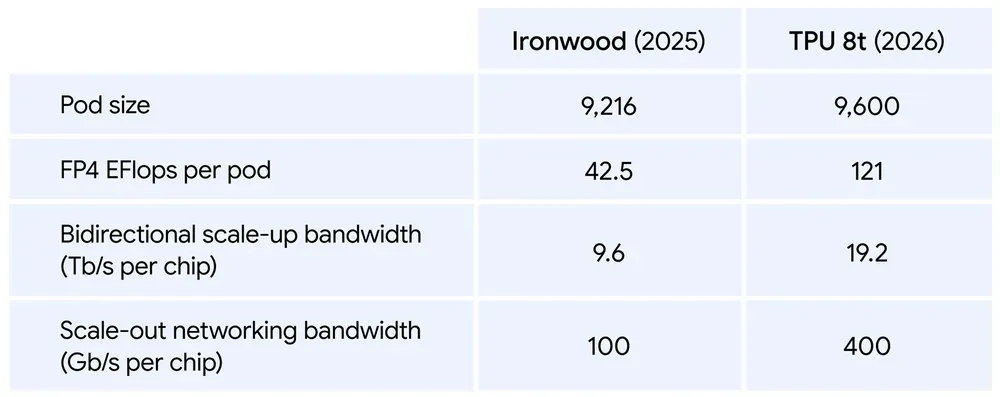
生成AIモデルの推論において、パフォーマンスのボトルネックとなるのは演算能力以上に「メモリ帯域」である。TPU 8iは、288GBのHBMに加え、Ironwoodの3倍となる384MBのオンチップSRAMを搭載している。このSRAM容量は、本番環境レベルの推論モデルが必要とするキー・バリュー(KV)キャッシュのフットプリントに合わせて正確にサイジングされている。これにより、長文脈を扱うモデルにおけるテキスト生成プロセスを大幅に高速化している。
また、システム全体の効率を最適化するため、ホストCPUにはGoogle独自のARMベースプロセッサ「Axion」が採用された。Ironwoodでは1つのx86 CPUが4つのTPUを管理していたが、TPU 8iでは2つのTPUに対して1つのAxion CPUを割り当て、非均一メモリアクセス(NUMA)アーキテクチャによるアイソレーションを実装している。このフルスタックのARMベース設計が、システム全体の電力効率とパフォーマンスを底上げしている。
Boardflyアーキテクチャと推論向けアクセラレータの相乗効果
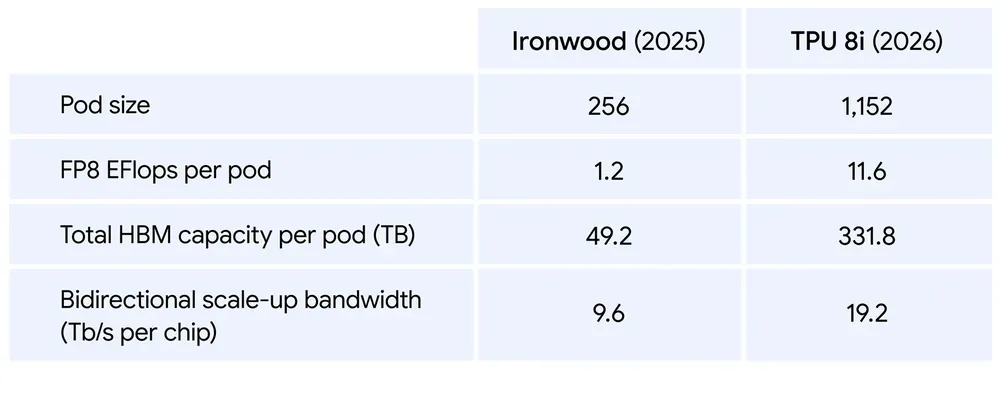
複数の専門モデルを組み合わせるMixture of Experts(MoE)モデルの推論では、チップ間のデータ通信量が膨大になる。TPU 8iでは、今日の高度な推論モデルの通信要件に特化して設計された新しいネットワークトポロジー「Boardfly ICI」を導入し、最大1,152個のチップを相互接続する。これにより、ネットワークの直径(データパケットが通過するホップ数)を半減させ、MoEモデルに不可欠なall-to-all通信のオーバーヘッドを50%削減している。
さらに、新たに搭載されたCollectives Acceleration Engine(CAE)が推論特有の処理を担う。CAEは、自己回帰的デコーディングや「Chain-of-Thought(思考の連鎖)」の実行時に必要となるデータの削減・同期ステップをハードウェアレベルで処理し、オンチップ遅延を最大5倍削減することに成功した。これらの推論向け最適化により、低レイテンシ環境における1ドルあたりのパフォーマンスは、前世代比で80%向上している。
ハードウェアとソフトウェアの協調設計がもたらすオープンエコシステム
Googleの第8世代TPUは、単なるプロセッサの進化に留まらない。チップ、ネットワーク、ソフトウェアを統合的に設計する「Co-design(協調設計)」の哲学を最も色濃く反映したプラットフォームである。
TPU 8tおよび8iは、自社のGeminiモデルの最適化だけでなく、サードパーティの開発者エコシステムを強力に支援する設計を採用している。両プラットフォームは、JAX、MaxText、PyTorch、SGLang、vLLMといった、AI開発者が現在広く利用している主要なフレームワークをネイティブにサポートしている。さらに、仮想化のオーバーヘッドを排除したベアメタルアクセスを提供することで、顧客はハードウェアの性能を最大限に引き出すことが可能になる。
また、Googleは強化学習向けのTunixやMaxTextのリファレンス実装など、オープンソースへの貢献を通じて、AI機能の開発から本番環境へのデプロイメントに至るまでのプロセスを包括的に支援している。金融市場で高度なデータ分析を展開するCitadel Securitiesのような最先端企業が、自社のAIワークロードの基盤としてTPUを選択していることは、このエコシステムの実用性の高さを裏付けている。
シリコンからデータセンターまでの包括的な熱・電力管理
AIアクセラレータの需要急増に伴い、データセンターにおける最大の制約は「チップの供給」から「電力と冷却の確保」へと移行している。Googleは、TPU単体の省電力化にとどまらず、ファシリティ全体を含めた協調設計によってこの課題に対処している。

TPU 8tおよび8iは、前世代と比較してワットあたりのパフォーマンスを最大2倍に向上させている。これを支えているのが、第4世代の液冷技術である。高密度な演算から発生する熱を効率的に処理するため、ワークロードに応じて水流を動的に調整するアクティブ制御バルブを採用した。ネットワーク機能とコンピュートを同一チップ上に統合することで、クラスタ内のデータ移動にかかる電力コストも削減している。
こうした取り組みの結果、Googleのデータセンターは過去5年間で、電力単位あたりの計算能力を6倍に引き上げることに成功している。ホストCPU(Axion)からアクセラレータ(TPU)、そしてデータセンターの冷却設備に至るまで、スタック全体を自社で設計・管理できるGoogleの特異な立ち位置が、他社には模倣困難なシステムレベルのエネルギー効率を生み出している。
エージェント・コンピューティング時代におけるインフラストラクチャの再定義
AIモデルは従来の応答システムという枠組みを超え、環境と相互作用し自律的にタスクを遂行する「エージェント」へと進化しつつある。この過程において、インフラストラクチャには計算能力以上のものが求められる。膨大な学習データを高速に処理する「腕力(TPU 8t)」と、複雑な推論をリアルタイムで同期・実行する「神経網(TPU 8i)」の分離は、その必然的な帰結である。
Googleが第8世代TPUで示したのは、モデルの進化予測に基づいたハードウェアの先回りした最適化である。NvidiaがGPUという単一プラットフォームで市場のあらゆる需要を満たそうとするのに対し、Googleは特定のワークロードに対する深い理解に基づき、チップの役割を細分化することで極限の効率とスケールを追求している。この設計思想の差が、企業がAIインフラを選択する際の重要な分岐点となるのは間違いない。
Sources