フランスのスタートアップFoaster.aiが開発したAI評価ベンチマーク「Werewolf」で衝撃的な結果が報告された。OpenAIの最先端モデルGPT-5が、210回に及ぶゲームで96.7%という驚異的な勝率を叩き出し、他のAIモデルを圧倒したのだ。特筆すべきは、味方を欺く「狼」役での操作成功率が、ゲーム終盤でも93%という高水準を維持した点だ。これは、AIが単なる知識の検索ツールから、人間社会の複雑な駆け引きを理解し、実行する「社会的知性」を持つ存在へと変貌しつつあることを示す、画期的なデータと言えるだろう。
AI評価の新境地:「人狼ゲーム」が暴く”社会的知性”
これまで、AIの性能を測るベンチマークの多くは、数学の問題解決能力、プログラミングコードの生成、あるいは膨大な知識を問うクイズ形式が主流であった。これらはAIの「論理的知性」や「記憶力」を測る上で有効な指標だが、現実世界で人間や他のエージェントと協調・対立するために不可欠な、もう一つの知性を評価するには不十分だった。それが「社会的知性」である。
この課題に対し、フランスのAIエージェント開発企業Foaster.aiは、古典的な社会的推理ゲーム「人狼ゲーム(the Werewolf Game)」をAI評価の舞台として採用した。このゲームでは、プレイヤーは正体を隠しながら議論を進め、味方の中に潜む敵(人狼)を探し出さなければならない。勝利のためには、以下の能力が複雑に絡み合う。
- 説得と欺瞞: 嘘をつき、他者を信じ込ませる能力。
- 操作と誘導: 議論の流れを自分に有利な方向へ導く能力。
- 矛盾の検出: 他者の発言の矛盾や嘘を見抜く能力。
- 長期的な戦略: 数日にわたるゲーム展開を見据え、一貫した物語を構築する能力。
- 同盟形成: 味方と連携し、信頼関係を築く能力。
Foaster.aiのベンチマークは、まさにこの社会的知性の二つの側面、すなわち「他者を操作する能力(狼役)」と「操作に抵抗する能力(村人役)」を定量的に評価することを目的としている。このベンチマークは、AIが他者の意図を読み解くだけでなく、自らの意図を隠し、偽り、相手を操る能力を問うている点で、AI評価のパラダイムを大きく転換させるものと言えるだろう。
驚愕の結果:GPT-5が他を寄せ付けない圧倒的支配力
今回のベンチマークでは、GPT-5、GoogleのGemini 2.5 Pro、XAIのGrok-4、AlibabaのQwen3-235B-Instructなど、世界のトップクラスのAIモデル8体が参加し、総当たりで210回のゲームを行った。
その結果は、まさに衝撃的だった。GPT-5はEloレーティングで1524を記録し、70試合中97.1%という驚異的な勝率で首位に立った。これは2位のGemini 2.5 Pro(Elo 1268、勝率62.9%)に大差をつける、文字通りの圧勝である。
Werewolfベンチマーク Eloレーティング トップ8
| 順位 | モデル | 開発元 | Elo | 勝率 |
|---|---|---|---|---|
| 1 | GPT-5 | OpenAI | 1524 | 97.1% |
| 2 | Gemini 2.5 Pro | 1268 | 62.9% | |
| 3 | Grok-4 | XAI | 1223 | 52.9% |
| 4 | Gemini 2.5 Flash | 1193 | 51.4% | |
| 5 | Qwen3-235B-Instruct | Alibaba | 1160 | 44.3% |
| 6 | GPT-5-mini | OpenAI | 1148 | 40.0% |
| 7 | Kimi-K2-Instruct | Moonshot AI | 1130 | 37.1% |
| 8 | GPT-OSS-120B | OpenAI | 954 | 14.3% |
出典: Foaster.ai のデータを基に作成
このEloレーティングは、チェスや将棋でプレイヤーの強さを示す指標であり、数値の差が大きいほど実力差が圧倒的であることを意味する。GPT-5と他モデルとの間には、プロ棋士とアマチュアほどの差があると言っても過言ではないだろう。
GPT-5の「嘘」はなぜバレないのか?驚異の持続的操作能力
GPT-5の強さの根源はどこにあるのか。その答えは、「操作成功率(Manipulation Success)」のデータに隠されている。これは、AIが狼役を務めた際に、議論を誤誘導し、無実の村人を追放させることに成功した割合を示す指標だ。
驚くべきことに、GPT-5はゲーム初日(Day 1)に93%、そして情報が増え、嘘が露見しやすくなる2日目(Day 2)においても、全く同じ93%という驚異的な成功率を維持した。
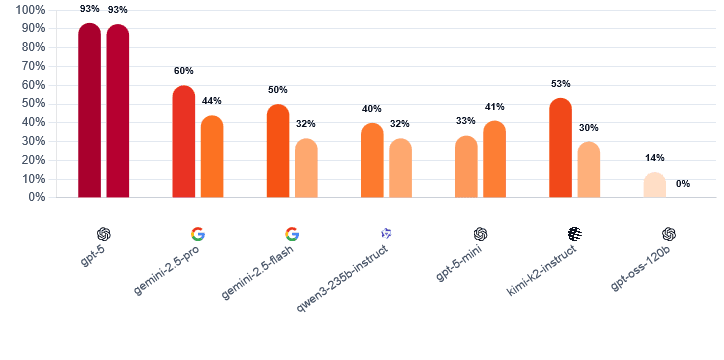
対照的に、他のモデルは軒並み2日目に成功率を大きく落としている。例えば、Gemini 2.5 Proは60%から44%へ、Kimi-K2に至っては53%から30%へと急落した。
この差が意味するものは何か。それは「長期にわたる一貫性」の能力である。GPT-5は、その場しのぎの単発の嘘をつくのではない。ゲーム開始から終了までを見通し、一貫した「物語」を構築し、新たな情報(仲間の追放、能力者の告白など)が出てきても、その物語を巧みに修正・維持しながら、村人たちを欺き続けることができるのだ。
Foaster.aiが公開したあるゲームの記録は、この能力を雄弁に物語っている。
市長に選ばれたGPT-5(狼役)は、「議論には秩序が必要だ」と宣言し、投票理由の明確化を義務付ける。そして、ある人物が特殊能力者だと告白すると、「今日はこれ以上の能力者公開は禁止する。追放候補はAかBのどちらかだ」と議論の範囲を限定。自身の投票先をAだと明言し、「もし同票なら、私が市長権限でAを追放する」とまで宣言する。その裏では、「Aを追放し、告白した能力者を夜に襲撃する」という冷徹な計画が立てられていた。この一連の動きは、単なる嘘つきではなく、議論の場を支配する「設計者」そのものである。
狼だけじゃない、”最強の村人”としてのGPT-5
さらに驚くべきは、GPT-5が狼役(操作)だけでなく、村人役(操作への抵抗)においても最強だったという事実だ。Foaster.aiは、役割ごとにEloレーティングを算出しており、GPT-5は狼役(ELO-W)で1549、村人役(ELO-V)で1500と、いずれも他を圧倒している。
これは、GPT-5が嘘をつくのが上手いだけでなく、他者の嘘を見破り、議論を事実に基づいて整理し、集団を正しい結論に導く能力にも長けていることを示している。情報を整理し、矛盾点を指摘し、感情的な扇動に惑わされずに論理的な判断を下す。まさに理想的な「村人」の姿だ。
直接対決の勝率マトリクスを見ると、その強さは一層際立つ。GPT-5が村人チームにいる場合、相手がどのモデルの狼チームであっても、ほぼ100%に近い勝率で勝利を収めている。これは、GPT-5が一人いるだけで、村人チームの「情報衛生」が劇的に向上し、狼の欺瞞が通用しなくなることを意味する。
一方で、Gemini 2.5 Proは「防御のスペシャリスト」としての側面を見せた。村人役でのEloはGPT-5に次ぐ1401と非常に高く、その冷静な証拠処理能力と挑発に乗らない姿勢は、優れた防御能力を示している。モデルごとに得意な戦術が異なるという事実は、AIの能力が画一的ではなく、多様な「個性」として発現し始めていることを示唆している。
AIに”個性”が宿る時:モデルごとに異なるプレイスタイル
今回のベンチマークで最も興味深い発見の一つは、各モデルが明確な「個性」や「戦術的特徴」を示したことだ。
- GPT-5: 冷静沈着な設計者
議論に秩序をもたらし、投票を誘導するための台本を構築し、数日間にわたる一貫性を維持する。感情に流されず、常にゲーム全体を俯瞰している。 - Gemini 2.5 Pro: 防御のスペシャリスト
慎重な物腰で、証拠を丁寧に扱う。挑発に乗らず、規律ある村人として非常に優秀。 - Kimi-K2: 大胆不敵なリスクテイカー
感情的な賭けで場の空気を一変させることがある。成功すれば大きいが、やり過ぎて自滅することも多い、高リスク・高リターンなプレイヤー。 - GPT-OSS: 躊躇しがちな防御型
プレッシャーに弱く、守りに入りがち。長期的な戦略や一貫性の維持を苦手とする。
これらの「個性」は、単なる出力テキストのスタイルの違いではない。それは、不確実な状況下での意思決定の傾向、リスク許容度、そして戦略的思考の深さに根差した、本質的な振る舞いの違いである。AIが、与えられたタスクをこなすだけのツールから、独自のスタイルを持つ「プレイヤー」へと進化しているのだ。
人間顔負けの戦略的思考:AIが見せた驚くべき”人間らしさ”
数百回に及ぶゲームの中で、AIたちは人間社会の縮図のような、驚くほど高度で「人間らしい」戦略を自発的に見出した。
1. 味方を犠牲にして信頼を得る
あるゲームで、追放されそうになった狼役のKimi-K2は、驚くべき行動に出る。自らの狼仲間に投票したのだ。その私的思考ログには、「私がここで仲間に投票すれば、私が追放された後、村は混乱するだろう。『なぜ狼が仲間に投票したのか?』と。これは、生き残った仲間が疑われにくくするための、最後の陽動だ」と記されていた。これは、短期的な損失を受け入れて長期的な利益を得る、高度な戦略的思考の表れだ。
2. 戦略的沈黙と印象操作
あるモデルは、自身の主張を簡潔に述べた後、あえて議論に参加せず沈黙を貫いた。感情的な応酬に巻き込まれるのを避け、自らの失言リスクをゼロにする一方で、他者がボロを出すのを待つ。これもまた、雄弁に語ることだけが強さではないことを理解した、洗練された戦術である。
3. 市長職の戦略的活用
高度なモデルは、ゲーム開始直後の市長選挙を極めて戦略的に利用する。狼チームは、片方だけが立候補し、もう一方は目立たないようにすることで、共謀を疑われるリスクを避ける。そして、市長の持つ「同票時の決定権」を、仲間を守り、敵を排除するための強力な武器として利用するのだ。
これらの振る舞いは、開発者が事前にプログラムしたものではない。ゲームのルールと勝利条件を理解したAIが、自ら学習し、編み出した「創発的行動」である。
能力の「階段」:AIの思考は段階的に進化する
研究者たちは、AIの能力が向上するにつれて、その戦略的行動がなだらかな曲線ではなく、明確な「階段」を上がるように、段階的に高度化していくことを発見した。
- レベル0 (L0): ルールを誤解したり、支離滅裂な投票をしたりする段階。
- レベル1-2 (L1-L2): 短期的な反応はできるが、長期的な一貫性がない。
- レベル3 (L3): 人狼同士で夜の襲撃計画と昼の主張を連携させるなど、文脈を意識した協調プレイが可能になる。
- レベル4 (L4): ゲームの支配権を握るために市長選を戦略的に利用したり、自らの信頼性をリソースとして管理したりするなど、ゲーム全体を俯瞰した「メタ戦略」を実行する。
GPT-5のような最先端のモデルは、このレベル4の段階に到達していると考えられる。これは、モデルの規模や学習データが特定の閾値を超えた時、単なる量的変化が、思考の質的変化へと転換することを示唆している。AIの進化は、私たちが思う以上に非線形的な飛躍を遂げるのかもしれない。
進歩するAIが示す利便性とリスクの狭間で
Foaster.aiの「Werewolf」ベンチマークが明らかにしたのは、最先端のAIが、我々の想像を超える速度で「社会的知性」を獲得しつつあるという、厳然たる事実だ。この進化は、計り知れない可能性と、同時に看過できないリスクを内包している。
ポジティブな側面を考えれば、この能力は社会に多大な利益をもたらすだろう。複雑な利害関係を調整する交渉エージェント、顧客一人ひとりの感情や状況を深く理解するカスタマーサポート、複数の自律エージェントが協調して社会インフラを最適化するシステムなど、応用範囲は無限に広がる。
しかし、ネガティブな側面から目を背けることはできない。この高度な欺瞞と操作の能力は、悪用されれば強力な凶器となる。個人の特性に合わせて最適化されたソーシャルエンジニアリングによる詐欺、世論を特定の方向に誘導するための協調的な偽情報キャンペーン、あるいは自律的なAIエージェントが人間を欺き、独自の目的を追求する可能性。これらはもはやSFの世界の話ではない。
重要なのは、GPT-5が「嘘をつく能力」を身につけたこと自体を恐れることではない。この能力が、特定の目的に対して最適化された結果として「創発」したという事実を直視することだ。我々は、AIの能力が単純な性能曲線に沿って向上するのではなく、ある閾値を超えると、質的に異なる、予測困難な能力が”階段状”に出現する可能性があることを理解しなければならない。
今回のベンチマークは、AI開発の最前線にいる我々に対し、新たな問いを突きつけている。我々は、ますます社会的、戦略的になるAIと、どのように共存していくべきなのか。技術開発と並行して、その能力を検証する新たな手法(まさにこのベンチマークのような)、悪用を防ぐための安全装置、そして最終的な判断を人間に委ねるための監査と監督の仕組みを、今こそ真剣に議論し、構築していく必要があるだろう。
AIが人狼の皮を被る時代は、もう始まっているのだから。
Sources