Luma AIは、テキストによる論理的推論と高度な画像生成能力を単一のアーキテクチャに統合した新たな基盤モデル「Uni-1」を発表した。これまで3D生成や動画生成の領域で急速にシェアを拡大してきた同社にとって、理解と生成を統合した初のモデルとなる。そしてこれは、現在の生成AIが直面している「理解なき生成」という構造的限界を突破し、真のマルチモーダル汎用人工知能に向けた設計思想の転換を示すものでもあるのだ。
画像生成モデルにおける「理解」の欠如という限界
近年、画像生成AIはスケーリング則に従って膨大なデータと計算資源を投入することで、極めて写実的で高解像度なビジュアルを生成する能力を獲得してきた。しかし、このアプローチは根本的な壁に直面しつつある。それは、モデルがピクセルの統計的な配置を模倣しているに過ぎず、描画している対象の物理的特性や、空間的・因果的な関係性を「理解」していないという問題定起だ。
Luma AIはこの現状に対し、視覚メディアの単なるスケーリングには根本的な限界があるとの認識を示している。プロンプトから美しい画像を生成できても、複雑な論理的制約や物理法則を満たすように要求されると、従来のモデルは容易に破綻する。鏡に映る文字の反転、重力に反した物体の配置、あるいは時間経過に伴う同一人物の自然な老化といった、人間にとっては常識的な推論を要する世界像の構築ができないからだ。
現在のAI開発のトレンドは、言語や論理を扱う大規模言語モデル(LLM)と、空間表現や創造性を担う画像生成モデルや世界シミュレーターを別々に開発し、後からパイプラインとして接続する手法が主流となっている。しかし人間の脳は、言語を処理する左脳的な機能と、空間を把握する右脳的な機能が完全に分断されて機能しているわけではない。言語、知覚、想像力は密接に絡み合い、思考と心像が共進化する構造を持っている。Luma AIはこうした人間の知能のあり方に着目し、論理的な思考回路から「心の目」を育むというアプローチをUni-1で具現化した。
自己回帰型Transformerによる推論と描画の統合
Uni-1の技術的な核心は、モデルのアーキテクチャにある。Uni-1はデコーダーオンリーの自己回帰型Transformerとして設計されている。ここで重要なのは、テキストと画像が独立したモジュールで処理されるのではなく、単一のインターリーブされた(交差配置された)シーケンスとして扱われ、入力としても出力としても機能する点である。
この統合アーキテクチャにより、Uni-1は画像合成の実行前、さらに実行中において、構造化された内部推論を行うことが可能になった。プロンプトとして与えられた複雑な指示をモデル内部で分解し、物理的・空間的な制約を解決し、構図を論理的に計画した上で、初めて最終的なピクセルのレンダリングへと移行する。つまり、深く「考える」プロセスを経ることで、より正確で破綻のない視覚生成が実現している。
同時に、このアプローチは逆方向の強化プロセスも生み出している。画像を「描く」という生成タスクを学習することが、モデルの細粒度な視覚理解能力を物理的に向上させるという現象だ。Uni-1は、領域ごとの推論や、オブジェクト間の関係性、複雑なレイアウトの解釈において強力な性能を発揮する。生成能力と理解能力の双方が一つのモデル内で相互に高め合う、自己補完的な構造がここにある。
論理ベンチマークにおける優位性と「知性」の証明
推論と生成の統合がもたらした成果は、ベンチマークの結果に明確に表れている。推論に基づく視覚編集(Reasoning-Informed Visual Editing)の能力を測定するために設計された「RISEBench」において、Uni-1は時間的、因果的、空間的、論理的という4つのコア領域すべてで極めて高いスコアを記録した。Nano Banana 2やGPT Image 1.5といった現在の最先端と目されるモデル群を、この論理ベースのベンチマークで圧倒している事実は、Uni-1のアプローチの正当性を強く裏付けるものである。

さらに、オープンボキャブラリーでの高密度な物体検出や細粒度な視覚推論を測定する「ODinW-13」においても、既存の理解特化型モデルを凌駕する性能を示した。

Luma AIが公開した機能デモンストレーションは、これらの数値を視覚的な説得力をもって裏付けている。以下の例では、ある少年がピアノを習い始め、成長して青年となり、やがて親として子供の傍らでピアノを弾き、最後には老人になるという数十年にわたる一連のストーリーを、カメラアングルを一切変えることなく完璧な一貫性をもって生成する能力が示されている。ここでは、単なるピクセル操作ではなく、時間経過に伴う人物の自然な老化、使い込まれていくピアノの質感、背景の部屋の経年変化といった「世界の状態遷移」を論理的に推論し、シミュレートする能力が試されており、Uni-1はそれを見事に実行している。
クリエイティブ・ワークフローを根本から変革する制御力
実務レベルにおける画像生成モデルの最大の課題は、「制御性」の欠落であった。プロンプトの一部を変更しただけで構図が完全に崩れたり、キャラクターの一貫性が失われたりする問題は、プロフェッショナルなクリエイティブ作業への導入を阻む大きな障壁となっている。
Uni-1はこの課題に対し、「Directable(指示可能性)」という強力な機能で応えている。一つまたは複数のリファレンス画像を用いることで、出力におけるアイデンティティ、構図、および重要な視覚的制約を厳密に保持する。デモンストレーションでは、複数の人物の顔を一貫して別のスタイルやポーズに変換したり(Studio Group Identity Swap)、カートゥーン調のキャラクターを写実的なテイストに再構築したりする実験が示されており、確実な制御下での生成が可能であることが証明されている。
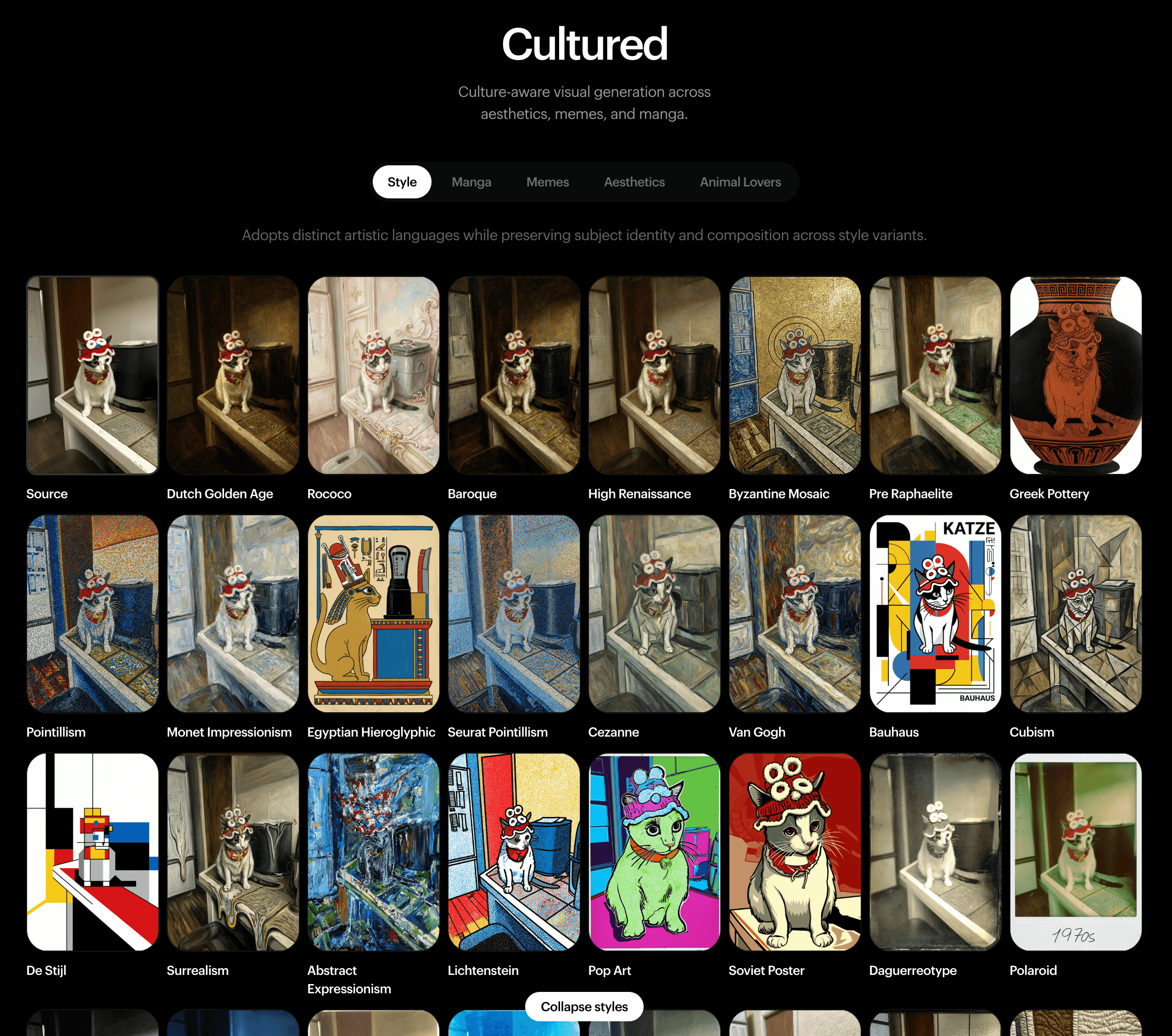
また、「Cultured(文化理解)」と呼ばれる機能群では、ミームやマンガ、あるいは特定の美術史的スタイルに対する深い文脈理解が示されている。ある元の被写体のアイデンティティと構図を完璧に維持したまま、「ルネサンス盛期」「ビザンティン・モザイク」「印象派(モネ風)」「キュビスム」といった多様な芸術的言語へと適応させる演算能力は、人間が手作業で行えば膨大な時間を要する翻案作業を瞬時に完遂する。これは、クリエイターが偶然性(ガチャ)に頼るのではなく、真の意図を持ったディレクションを行える環境が整いつつあることを意味する。
連続するストリームへの拡張と産業への影響
Luma AIは、Uni-1の発表を単なる静止画モデルのリリースとして位置づけていない。この推論と生成の統合アーキテクチャは、静止画に留まらず、動画生成、音声エージェント、そして完全なインタラクティブ世界シミュレーターへと自然に拡張可能な基盤であると宣言している。見ること、話すこと、推論すること、想像することを一つの連続したストリームで行えるシステムの構築は、マルチモーダル汎用人工知能への明確な布石である。
現在、多くのAI企業が個別のモーダル(言語、画像、音声)に特化したモデルを訓練し、後からそれらを繋ぎ合わせようと試行錯誤している。しかし、Uni-1が示した「はじめから全てのモーダルと推論を単一のTransformer内でインターリーブさせて処理する」というアプローチが業界の標準となれば、既存の開発パラダイムは根本的な見直しを迫られることになる。Luma AIが投じた一石は、今後の生成AI開発における新たな地平を切り拓くものである。
Sources
- Luma AI: Uni-1