
Mistral AIは2026年3月16日、新モデル「Mistral Small 4」を発表した。Apache 2.0ライセンスで公開するオープンソースモデルで、推論、画像入力、コーディング支援を単一モデルに統合した点を特徴とする。高速な指示応答向けモデル、推論特化モデル、マルチモーダル対応モデルを用途ごとに切り替えるのではなく、1つのモデルで幅広い処理を担わせる構成だ。
同社はSmall 4を、一般的なチャット、コード生成やコードベース探索、複雑な推論、文書理解、画像を含む入力処理までをカバーするモデルと位置づける。提供先としてはMistral API、AI Studio、Hugging Faceを挙げるほか、NVIDIAのbuild.nvidia.com経由での試用や、NVIDIA NIMによる本番導入にも対応するとしている。なお、プレスリリースではAPI利用料や商用利用時の価格体系は示されていない。
128エキスパートのMoE構成を採用、総パラメータ数は119B
Mistral Small 4はMixture of Experts(MoE)構成を採用する。総パラメータ数は119Bで、128個のエキスパートを備えるが、1トークンあたりで実際に有効化されるのはそのうち4つだ。アクティブパラメータ数は1トークンあたり6Bで、埋め込み層と出力層を含めると8B相当になる。
この構成は、モデル全体の規模を大きく保ちつつ、各トークンの計算量を抑えるためのものだ。コンテキスト長は256kで、長文の対話や文書解析を想定する。入力はテキストと画像の両方に対応し、文書理解や視覚情報の処理も1モデルで扱える。Mistralは開発者、企業、研究者を主な利用者として挙げており、コーディング支援から複雑な推論までを広く対象にしている。
reasoning_effortで応答速度と推論の深さを切り替える
Small 4の大きな特徴の1つが、推論の深さを調整するreasoning_effortパラメータだ。reasoning_effort="none"では軽量で低遅延の応答を返し、Mistralはこの挙動をMistral Small 3.2と同系統のチャットスタイルとして説明する。これに対し、reasoning_effort="high"では、より複雑な問題に対して段階的に考える深い推論モードとなり、過去のMagistral系モデルに近い冗長度になるという。
MistralはSmall 4を、Magistralの推論、Pixtralのマルチモーダル、Devstralのエージェント型コーディングの各能力を統合したモデルとして紹介している。従来は用途ごとにモデルを切り替えていた場面でも、同一モデル内で応答の性格を調整できる点が今回の主眼といえる。
旧世代比で応答完了時間を40%削減、スループットは3倍
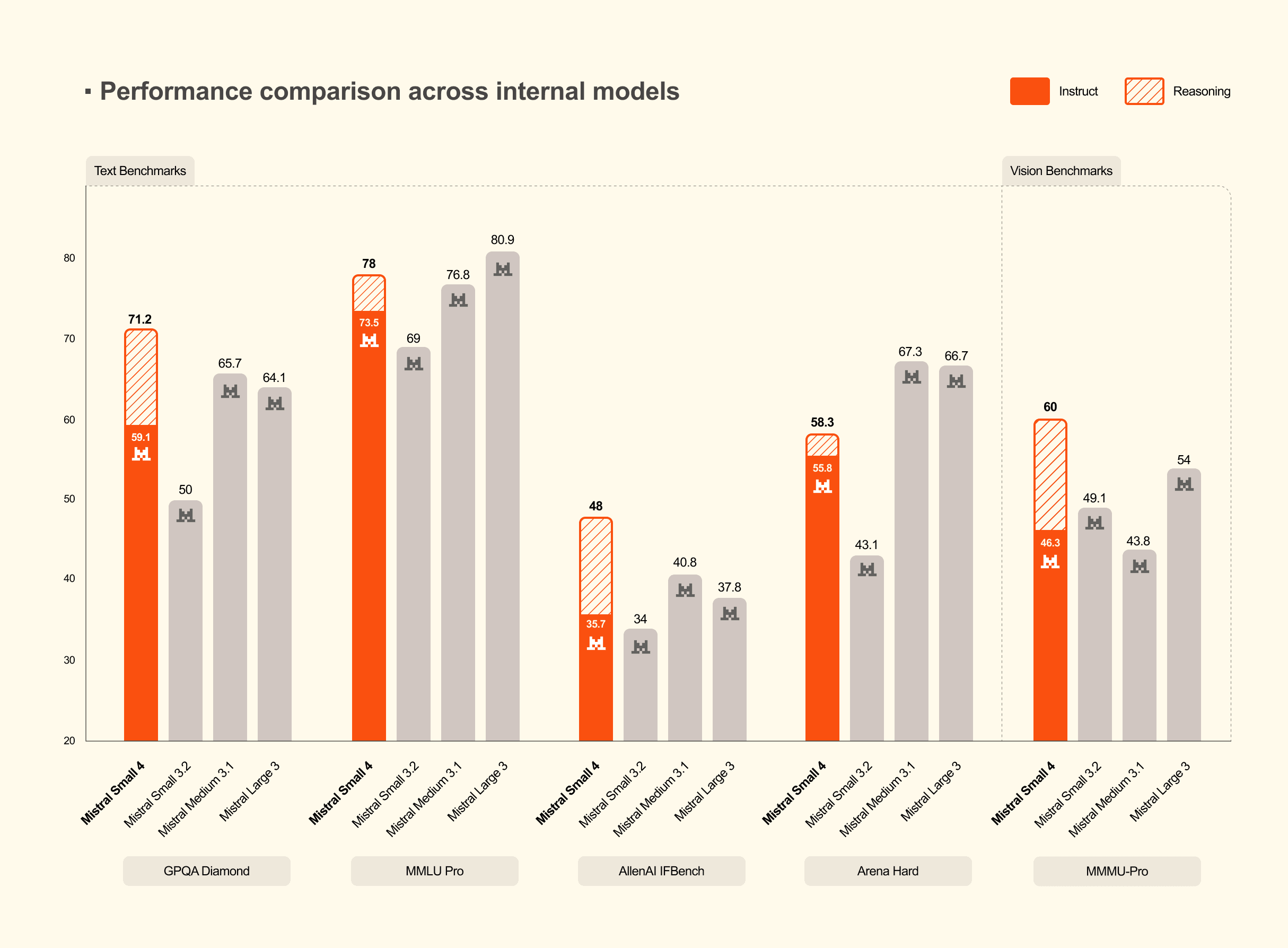
性能面では、Mistral Small 3と比べて応答完了までの時間を40%削減し、スループット最適化構成では毎秒あたりのリクエスト処理数が3倍になったとしている。加えて同社は、推論モード時のSmall 4が複数のベンチマークでGPT-OSS 120Bに匹敵、または上回る性能を示しながら、出力量をより短く抑えられると説明している。
Mistralは、出力が短いことは遅延や推論コストの低下、運用効率の改善につながると位置づけている。とくに長い応答を必要とする業務では、モデルの精度だけでなく、どれだけ短い出力で結果を返せるかも運用コストに影響するからだ。ただし、こうした数値は同社が示した評価条件に基づくものであり、実際の導入環境では推論設定や利用フレームワークによって結果が変わる余地がある。
配布経路を広げつつ、導入要件は大型GPUを前提とする
提供形態はオープンソースが中心で、Apache 2.0ライセンスの下で公開された。MistralはvLLM、llama.cpp、SGLang、Transformersなど主要な推論環境への対応も案内しており、一般用途のそのままの導入に加え、専用用途向けのファインチューニングも想定している。企業向けにはオンプレミス導入やカスタムファインチューニングの相談窓口も用意する。
一方で、推奨インフラ要件は軽くない。最小構成は4基のNVIDIA HGX H100、2基のNVIDIA HGX H200、または1基のNVIDIA DGX B200とされ、推奨構成は4基のHGX H100、4基のHGX H200、または2基のDGX B200である。名称に「Small」と付くものの、実際の導入対象は個人用途よりも、大規模推論基盤を持つ企業や研究開発組織に近い。
Mistralはあわせて、NVIDIA Nemotron Coalitionの創設メンバーとして参加したことも明らかにした。モデル公開と同時に、NVIDIA NIMやNeMoとの連携、build.nvidia.comでの試用導線まで示しており、モデルそのものの公開に加えて、推論最適化から配布、本番導入までの導入経路を並行して整えている点も今回の発表の特徴である。
Sources
- Mistral AI: Introducing Mistral Small 4