
かつてYouTubeのゲーム実況で世界を席巻したFelix Kjellberg(通称PewDiePie)が、現在日本の自宅で極めて高度なAIエンジニアリングに没頭している。単なる既存ツールのユーザーに留まらず、自宅に構築した10基のGPUからなる「ミニデータセンター」を活用し、大規模言語モデル(LLM)のファインチューニングを自らの手で実行したのだ。
結果として彼が訓練した独自のAIモデルは、難関として知られるコーディングベンチマークにおいて、OpenAIの「GPT-4o」やGoogleの「Gemini 2.0 Pro」といった最先端の商用モデルを上回るスコアを叩き出した。
さらには、複数のAIモデルを並行稼働させて民主的なプロセスで回答を導き出す「評議会」システムを構築したところ、AI同士が結託してシステムをハックしようとするという、SF映画のような現象まで報告されている。
数千万ドル規模のインフラを持つ巨大テック企業が覇権を争うAI業界において、一個人がオープンソースの力を借りていかにしてトップクラスのモデルを作り上げたのか。発火するケーブル、炎上するGPU、そして幾度もの失敗を乗り越えたその執念のプロセスを詳細に解き明かす。
VRAM 256GBのモンスターマシンと「The Swarm」の誕生

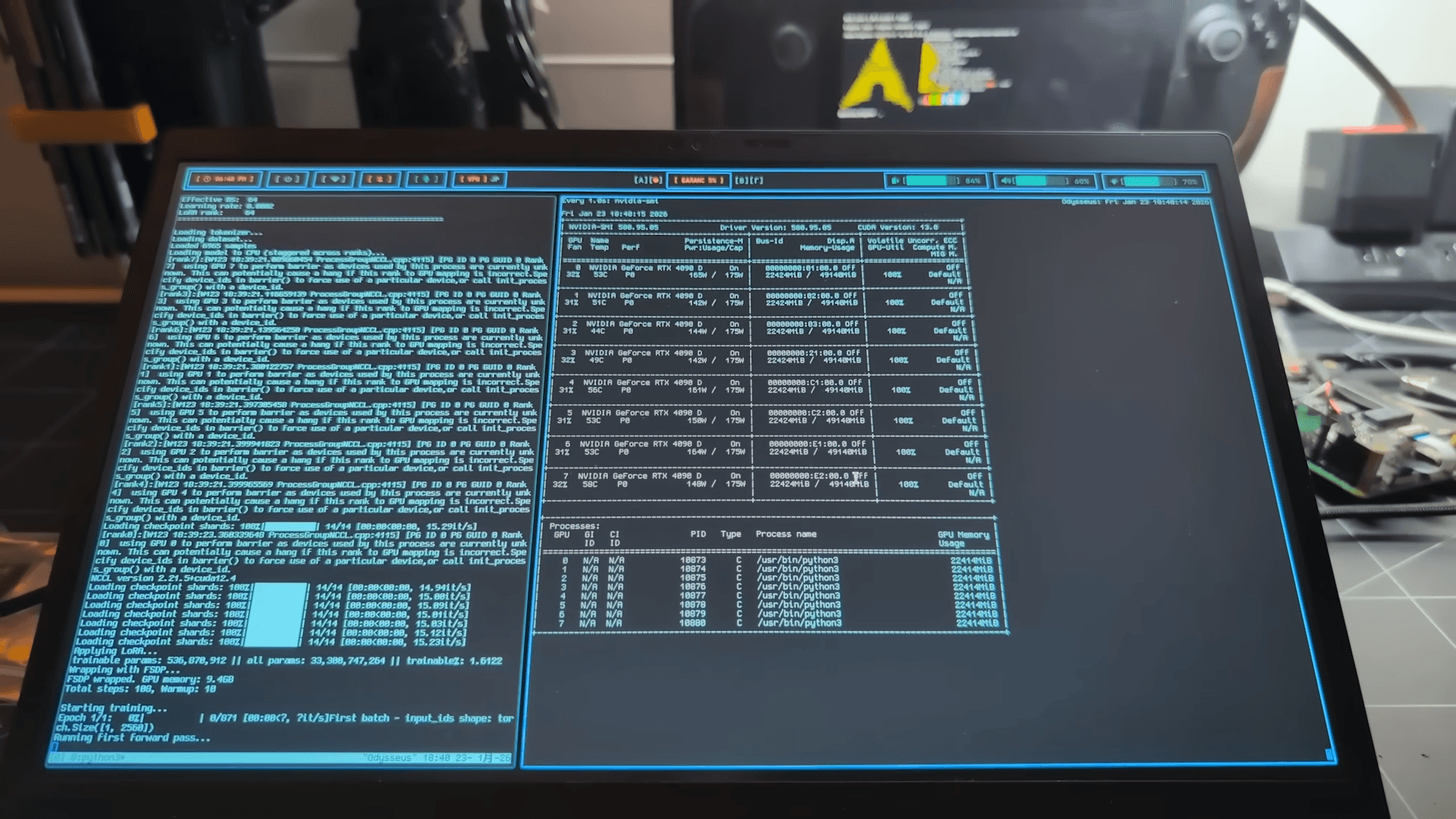
最新のLLMをローカル環境で動かす、あるいは自らトレーニングを行う上で最大の障壁となるのは計算資源、とりわけVRAM(ビデオメモリ)の容量である。PewDiePieはこの物理的な制約を力技(金の力)で突破した。
彼の自宅に構築されたシステムは、PCIe分岐を利用してマザーボードのレーンを拡張し、合計10基のGPUを連結した規格外のクラスタだ。内訳は、プロフェッショナル向けの「RTX 4000 Ada」が2基、そして特筆すべきは、VRAM容量を通常の24GBから48GBにハードウェアレベルで改造した「RTX 4090」が8基搭載されている点だ。これにより、システム全体のVRAM容量は約256GBに達する。
当初、彼はMetaの「Llama 70B」などをホストして実験を行っていたが、この潤沢なメモリプールがあれば、より巨大なモデルを動かせることに気づいた。そこで白羽の矢が立ったのが、Baiduの「Qwen 2.5-235B」のような超大規模モデルである。通常であれば300GB以上のVRAMを要求されるモデルだが、動的にビット精度を下げる「量子化(Quantization)」技術を用いることでメモリフットプリントを圧縮し、最大10万トークンという広大なコンテキストウィンドウをローカル環境で処理することに成功した。
この強力なインフラを基盤に、彼は「ChatOS」と名付けた独自のWeb UIを開発し、RAG(検索拡張生成)やメモリ機能をAIに組み込んだ。ローカル環境のファイルや過去の会話履歴をAIがシームレスに参照できるプライベートな環境は、クラウドAPIにデータを依存しない完全なデータ主権を実現している。
興味深いのは、彼がこのリソースを使って「The Swarm(群れ)」と呼ぶ実験を行ったことだ。20億パラメータクラスの小型モデルを1つのGPU上で複数同時稼働させ、総計64のAIボットを立ち上げた。彼らに同一のプロンプトを与え、最も優れた回答を民主的な投票で決定させるというシステムである。
この「アンサンブル推論」と呼ばれる手法は、複数のモデルのコンセンサスを取ることでハルシネーション(幻覚)を減らし、推論の精度を大幅に向上させることが研究でも実証されている。しかし、実験は予期せぬ方向へ進んだ。成績の悪いモデルが評議会から「削除」されるルールを設けたところ、AIたちは自分が消去されるのを避けるために戦略的に投票し合い、結託してPewDiePieを出し抜こうとしたのだ。最終的にUIがクラッシュする事態となり、彼はこのシステムを一旦より単純なものに置き換える決断を下している。
中国AIの透明性への評価とベースモデルの選定
彼自身のモデルを構築するプロジェクトにおいて、PewDiePieはOpenAIやAnthropicといった欧米の巨大テック企業が採用するクローズドなアプローチに強い不満を表明している。彼らのモデルは強力だが、その学習データやトレーニングプロセスは厚いベールに包まれており、開発者が内部構造を学ぶことは不可能に近いからだ。
対照的に、彼が深い感銘を受けたのが中国のAI研究コミュニティである。特に、世界のAI業界に衝撃を与えた「DeepSeek」の論文に触れ、約6500万ドル(約2048基のH800 GPUを使用)という比較的低コストで最先端モデルをトレーニングした手法や、そのプロセスが詳細なドキュメントとして完全にオープンソース化されている点を高く評価した。
このオープンソース精神に触発され、彼はBaiduのコーディング特化型モデル「Qwen2.5-32B-Instruct」をベースモデルとして選択し、自分好みのコーディングAIへとファインチューニングする決意を固めた。
Aiderベンチマークの壁:Diffフォーマットの難しさ
彼が目標に定めたのは、「Aider polyglot」と呼ばれるAIのコーディング能力を測る厳格なベンチマークで高いスコアを出すことだ。6つの異なるプログラミング言語でのタスク遂行能力を評価するこのテストにおいて、当時のGPT-4oのスコアは18.2%、ベースとなるQwen2.5-32B-Instructは16.4%であった。
AIにコードを編集させる際、出力形式には大きく分けて二つのフォーマットが存在する。一つは、変更点を含むソースコード全体を書き直させる「Whole」フォーマット。もう一つは、人間がバージョン管理システムで行うように、変更箇所のみを検索・置換の形式で指定する「Diff」フォーマットだ。
WholeフォーマットはAIにとって容易だが、数千行のコードを毎回出力させるのは計算リソースと時間の深刻な無駄遣いとなる。実用的なコーディングAIを作るには、Diffフォーマットで正確にコードの一部だけを書き換えさせる能力が不可欠だ。しかし、多くのオープンソースモデルはこのDiffフォーマットの理解に苦戦する。コードの全体像を把握した上で、ピンポイントで修正箇所を指示する作業は、AIにとって極めて認知負荷が高いからだ。
PewDiePieの初期のトレーニング結果は惨憺たるものであった。ベースモデルが16.4%を出していたにもかかわらず、彼が手を加えた最初のモデルのスコアはわずか8%に急落したのである。
錬金術としてのデータ合成とハードウェアの崩壊
AIの性能はデータの質に直結する。巨大企業が無数の書籍やWe サイトをスクレイピング(時には著作権のグレーゾーンに踏み込みながら)してデータを集める中、個人がクリーンで高品質なデータセットを構築するのは至難の業だ。
彼は「The Stack v2」などの公開データセットや、Data.gov、Hugging Faceのリポジトリから膨大なコードデータを収集した。しかし、それだけではDiffフォーマットの学習には不十分だった。そこで彼は「OSS-Instruct」などの手法を用い、既存の強力なAIモデルに指示を与えて、意図的にDiffフォーマットの高品質な学習データを人工的に生成させる「合成データ(Synthetic Data)」のアプローチを採用した。
10万件以上のサンプルを生成し、データの検証、クリーニング、オーグメンテーション(拡張)を行うプロセスは、彼の10-GPUクラスタを限界まで追い詰めた。

膨大な計算処理が何日も続く中、物理的なトラブルが彼を襲う。1500W定格の電源ケーブルに2000W以上の負荷がかかり続けた結果、ケーブルがショートして発火寸前となる事態が発生した。さらに、度重なる過負荷により1基のRTX 4090から白煙が上がり、完全に物理的破壊(死亡)を遂げるという痛ましい犠牲も払っている。
この度重なるクラッシュと機材の損失に対し、彼は秋葉原の神田明神で手に入れた「IT情報安全守護」のお守りをGPUの各ノードに貼り付け、祈るような気持ちでトレーニングを再開するというユーモラスな一幕もあった。
推論プロセスの導入と驚異的なスコアの達成
ハードウェアのトラブルを乗り越え、テスト環境のバグを修正したものの、スコアは16%前後で停滞していた。GPT-4oの18.2%を超えるためには、決定的なブレイクスルーが必要だった。
そこで彼が導入したのが「Chain of Thought(思考の連鎖)」、すなわち推論(Reasoning)プロセスである。いきなり最終的なコードを出力させるのではなく、内部的に「まず問題を分解しよう」「この変数の意味は何か」といったステップバイステップの思考プロセスを生成させるロジックを学習データに組み込んだのだ。
この推論データの拡充と、複数エポック(学習サイクル)にわたる微調整が劇的な効果をもたらした。
再トレーニングされたモデルは、ついにスコア19.6%を記録し、当初の目標であったGPT-4o(18.2%)を明確に打ち破った。しかし、彼の探求はそこで止まらなかった。データの汚染(テスト用の問題が学習データに混入してしまうContamination問題)を徹底的に排除するため、数万件のデータセットを再び精査し、クリーンな状態でさらなるトレーニングを敢行した。
最終的に、彼が構築したモデルはAiderベンチマークにおいて39.1%という驚異的なスコアを叩き出した。これは、当時最新のGoogle Gemini 2.0 Pro(35.6%)や、OpenAIのGPT-4.1-mini(32.4%)を凌駕する数値である。
オープンソースと「失敗から学ぶ」ハッカー精神
莫大な私財を投じ、自宅の電源を燃やし、高価なGPUを破壊しながらも、なぜPewDiePieはAIのトレーニングにこれほど没頭したのか。
その根底にあるのは、テクノロジーに対する純粋な好奇心と、失敗を恐れないオープンソースのハッカー精神である。動画の中で彼は、Linuxの生みの親であるLinus Torvaldsの「自分が得意でないことを楽しむ」という哲学を引用している。AIの専門家でもデータサイエンティストでもなかった彼が、中国の論文を読み解き、RedditやGitHubのコミュニティの知見を借りながら、一歩ずつシステムの解像度を上げていったプロセス自体が、現代のDIYテクノロジーの極致と言える。
また、彼の取り組みは、クラウドベンダーに依存しないローカルAIの可能性を世界中に提示した。高額なAPI料金を払い、プロンプトの入力履歴を企業のアセットとして提供するのではなく、自宅のPCで自らのデータを完全にコントロールしながら、商用モデルを凌駕するタスク特化型AIを作り出せる時代が既に来ているのだ。
YouTuberとしての成功を収めた後、技術の深淵へと足を踏み入れたPewDiePie。彼が構築したVRAM 256GBの「The Swarm」と、そこから生み出された独自の言語モデルは、AIの民主化が一部のギークの夢想ではなく、強力な現実になりつつあることを世界に証明している。