
AIエージェントは、「スキル」と呼ばれる構造化テキストファイルを活用することで、特定タスクの専門知識を動的に引き出せると期待されている。しかし、UC Santa Barbara、MIT CSAIL、MIT-IBM Watson AI Labの研究者たちが34,198件の実世界スキルを用いて行った大規模な検証は、その期待に冷水を浴びせるものだった。ベンチマークで示された恩恵は「脆弱」であり、現実的な条件が加わるにつれて急速に消失する。弱いモデルに至っては、スキルを与えると逆にパフォーマンスが低下するという逆効果すら確認されているのだ。
スキルという概念の登場と急速な普及
スキルの概念は、2025年10月にAnthropicがClaude Codeに実装したことで広まった。エージェントが与えられたタスクに対して必要な専門指示を自動的に判断し、取得するモジュール型システムである。AnthropicのClaudeやOpenAIのCodexをはじめ、多くのオープンソースプロジェクトが同様の設計思想を採用したことで、スキルはAIエージェント開発における事実上の標準的アプローチとして定着しつつある。
スキルファイルには、APIの使用パターンやワークフロー定義といったドメイン固有の知識が格納されており、エージェントはタスク処理中にこれらのファイルを動的に読み込み、記述された手順に従って動作する設計だ。問題の核心は、AIエージェントが自力でスキルを見つけ出し、それを適切に活用できるかどうかという一点にある。
ベンチマークが作り出した「見せかけの成功」
既存の評価基準であるSKILLSBENCHには、根本的な設計上の問題がある。このベンチマークでは、タスクに対して精選されたスキルがエージェントに直接渡される。つまり、エージェントは膨大なスキルコレクションから自分で選択する必要がなく、必要な情報があらかじめお膳立てされた状態でテストを受ける。

研究論文が挙げる具体例が、この問題の本質を端的に示している。USGS水位観測所の洪水発生日を特定するタスクでは、提供される3つのスキルに、水位データをダウンロードするための正確なAPI、洪水閾値の具体的なURL、洪水日を検出するための既製コードスニペットが含まれている。研究者たちは「これらのスキルを組み合わせれば、タスクの解法がほぼすべて揃っている」と指摘する。現実のエージェントが直面する「必要なスキルが存在するかどうかも分からない大規模な雑然としたコレクションから自力で探す」という課題とは、根本的に異なる条件下でのテストである。
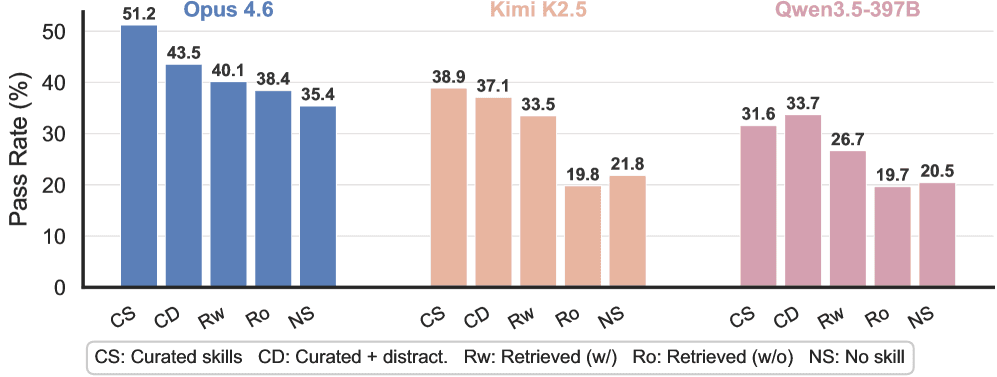
34,198件の実データが暴いた現実
研究チームはskillhub.clubとskills.shというスキル集約プラットフォームから、MITおよびApache 2.0ライセンスの実スキル34,198件を収集・重複排除した。対象スキルはウェブ開発から科学計算に至るまで幅広い分野をカバーしており、実際の開発現場を模した大規模なテスト環境が整備された。
評価は6段階の条件設定で行われ、精選スキルを強制ロードする理想的な状況から始まり、撹乱要因の追加、エージェント自身によるコレクション全体の検索(精選スキルあり・なし)へと、段階的に現実に近い条件へと変化させた。
テストを受けたのは3つのモデルだ。Claude CodeにClaude Opus 4.6を組み合わせたもの、Terminus-2にKimi K2.5を組み合わせたもの、そしてQwen CodeにQwen3.5-397B-A17Bを組み合わせたものである。各モデルは、スキル取得からタスク解決まで、パイプライン全体を独立して処理した。
パフォーマンス低下の具体的な数値
最も強力なClaude Opus 4.6でも、現実的な条件が加わるにつれてパフォーマンスは一貫して低下した。精選スキルを強制ロードした理想的な条件下では通過率55.4%を記録するが、エージェント自身がどのスキルをロードするか選択する段階に移ると51.2%に下落する。撹乱要因(無関係なスキル)を混入させると43.5%、エージェントが自力でコレクション全体を検索する条件では40.1%、精選スキルをプールから除外した最も現実的な条件では38.4%まで低下する。スキルを一切使用しないベースラインは35.4%であり、最悪ケースとの差はわずか3ポイントに収まる。
弱いモデルでは状況がさらに深刻だ。Kimi K2.5は最も現実的な条件下で19.8%を記録したが、これはスキルなしのベースライン21.8%を下回る。Qwen3.5-397Bも同様に、19.7%対20.5%という結果で、スキルありの方が劣る結果となった。無関係なスキルが、弱いモデルにとっては有益な補助ではなく、無駄なリソース消費と誤誘導の源になる実態が浮かび上がる。
エージェントが躓く3つの壁
研究者たちは、パフォーマンス低下の根本的な原因として「選択」「検索」「適応」の3段階にわたるボトルネックを特定している。それぞれが独立した障壁であり、一つを解消しても他の問題が残存するのがこの構造の厄介な点だ。
第一の壁は「選択」の段階にある。精選スキルが目の前にある状態でも、Claudeが必要なスキルをすべてロードできたのはわずか49%のテスト実行に過ぎなかった。撹乱要因が混入するとこの割合は31%まで落ちる。興味深いことに、Kimiは精選スキルがある条件で86%という高いロード率を示したが、それがタスク性能の向上には繋がっていない。スキルを取得したとしても、その内容を有効活用できているかどうかは別問題であることが分かる。
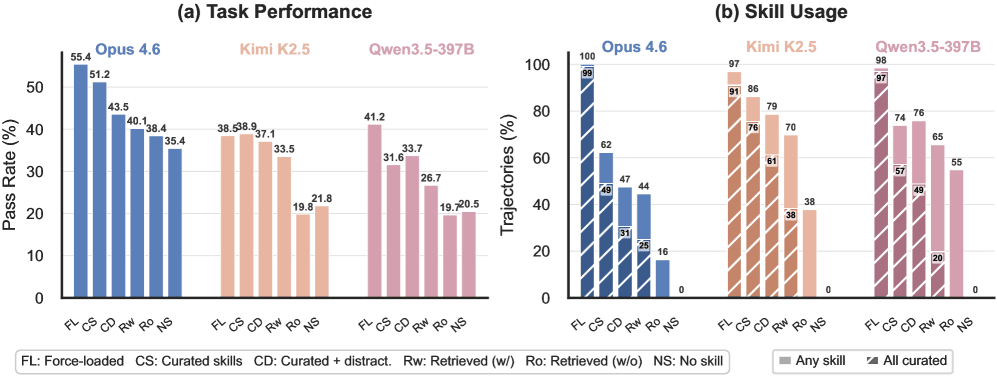
右パネル(Panel b): スキル使用率。各条件下での「いずれかのスキルをロードした割合(solid)」と「精選スキルをすべてロードした割合(hatched)」を示す。最も厳しい条件下ではClaudeのスキルロード率が16%まで落ちる一方、KimiとQwenはスキルなしベースラインを下回る。
第二の壁は「検索」の精度だ。エージェントが自力でスキルを検索する際、最も優れた手法でも Recall@5(上位5件中に正解が含まれる割合)は65.5%に留まる。3分の1以上のケースで、正しいスキルを見つけることすら叶わないわけだ。
第三の壁は「適応」の能力だ。タスクに完全に合致した専門スキルが存在しない場合、エージェントは汎用スキルをタスクの具体的な要件に合わせて適用することができない。これは現実のスキルコレクションでは頻繁に起きる状況だ。
なお、検索戦略の比較において、最も高いパフォーマンスを発揮したのは「エージェント的ハイブリッド検索」と呼ばれる手法だった。エージェントが反復的に検索クエリを生成し、候補を評価しながら戦略を調整するこのアプローチは、単純なセマンティック検索と比べてRecall@3で18.7ポイント上回った。
事後的な改良の効果と限界
パフォーマンスのギャップを埋めるため、研究者たちは2種類の改良戦略を検討した。一方は、タスク固有の改良だ。エージェントがタスクを探索し、一旦解法を試み、取得したスキルの有用性を評価した上で、そのプロセスから新たなタスク特化スキルを生成するアプローチだ。テンソル並列処理のタスクでは、エージェントが2つの異なるスキルのアイデアを組み合わせ、どちらの元スキルも単独では提供できなかった新しいスキルを作成した事例が報告されている。

この手法により、Claudeの通過率はSKILLSBENCHで40.1%から48.2%に向上した。一般エージェントベンチマークのTerminal-Bench 2.0では、61.4%から65.5%への改善が確認された。スキルなしのベースライン57.7%と比較した際に、スキル取得と改良を組み合わせた効果が7.8ポイントの上乗せとして現れている。
もう一方のタスク非依存の改良(ターゲットタスクの情報なしにスキル自体をオフラインで改善するアプローチ)は、散発的な改善に留まった。研究者たちの結論は明快だ——改良はあくまで既存スキルの品質を増幅させる「乗数」として機能するのであり、新たな知識を生み出す手段にはなり得ない。当初取得したスキルに関連情報が含まれている場合にのみ、改良は効果を発揮する。
Vercelの先行研究が示していた警告
今回の研究結果は、以前にVercelが行った研究と整合する。Vercelの調査では、テストケースの56%でエージェントが利用可能なスキルを一度も取得しなかったことが観察されており、スキルありの通過率はスキルなしのベースラインと完全に一致していた。対照的に、エージェントのコンテキストに受動的に読み込まれる単純なMarkdownファイル(AGENTS.md)は100%の通過率を達成し、スキルシステムの最高値79%を大幅に超えた。
今回の研究はこの課題を、複数のモデルと大規模なスキルセットを用いて体系的に追認した。エージェントは利用可能なスキルを自分に関連するものとして認識できず、単純にスキップしてしまうという問題が、個別事例ではなく普遍的なパターンとして確認されたわけだ。コードはGitHub(UCSB-NLP-Chang/Skill-Usage)で公開されている。
「スキルの民主化」が直面する現実
スキルという概念には、AIエージェントの能力を外部から拡張し、モデル自体を再訓練することなく専門知識を付与できるという、理論上の魅力がある。AnthropicがClaude Codeに実装し、OpenAIがCodexに取り込み、多くのオープンソースプロジェクトが追随したのも、そのポテンシャルへの期待からだ。
しかし今回の研究が示すのは、現在のスキルエコシステムが、能力の高いモデル向けに設計された理想的な条件下でのみ機能する、という現実だ。実際の運用環境を想定した場合、スキルの恩恵は驚くほど薄く、弱いモデルには害になる可能性すらある。研究チームは、より優れたスキル検索手法の開発、効果的なオフライン改良戦略の整備、そして異なるモデル能力を考慮したスキルエコシステムの設計が急務だと訴える。
AIエージェントの実用化に向けた競争が加速する中、ベンチマークの数字だけを根拠に技術の成熟度を判断することの危うさを、本研究は改めて明示している。
論文
- arXiv: How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
参考文献
- GitHub: UCSB-NLP-Chang/Skill-Usage