日常的に利用するGoogle マップなどのナビゲーションアプリや、世界中を瞬時に結ぶインターネットのルーティング、さらには巨大なSNSの繋がりから複雑なタンパク質の相互作用ネットワークまで。現代社会を支えるあらゆるシステムは、点と線で構成される「グラフ(ネットワーク)」として数学的に表現される。
これらのネットワークにおいて、「任意の2点間の最短ルートを見つけ出す」というミッションは、理論計算機科学における最も根源的かつ重要な課題の一つである。これは「全点対最短経路問題(APSP: All-Pairs Shortest Paths)問題」と呼ばれる。
一見シンプルに思えるこの課題は、ネットワークの規模が巨大化するにつれて、計算の「組み合わせ爆発」という冷酷な物理的限界に直面する。この計算量の壁を打破するため、世界中の数学者やコンピューターサイエンティストたちは、厳密な正解ではなく「十分に実用的で正確な近似値」を、いかに超高速で弾き出すかというアプローチを追求してきた。
そして2025年、この分野において四半世紀にわたり難攻不落とされてきた理論的なギャップが、ついに埋められた。インド工科大学ガンディナガル校(IIT Gandhinagar)のManoj Gupta准教授が、計算機科学のトップカンファレンスの一つであるFOCS 2025にて発表した論文「Improved 2-Approximate Shortest Paths for close vertex pairs」は、1996年以来の停滞を打ち破る画期的なブレイクスルーとして注目を集めている。
本稿では、APSP問題が抱える根本的なジレンマから、Manoj Gupta准教授が考案した新アルゴリズムの深層にある数学的直観、そしてこの発見が我々の世界観にどのような影響を与えるのかを見ていきたい。
計算の限界と近似アルゴリズムの台頭
グラフ理論において、頂点(ノード)の数を \(n\)としたとき、すべての頂点ペアの組み合わせは \(n\)の2乗に比例する。APSP問題の厳密解を求める古典的なアルゴリズムは、密なネットワークにおいては最悪の場合 \(n\)の3乗に近い計算時間(立方時間)を要することが知られている。
ネットワークの規模が2倍になれば、計算量は約8倍に膨れ上がる。数千億のWebページや数百億のIoTデバイスが繋がる現代において、このスケーリングの悪さは致命的である。そのため、「正確な最短距離」の代わりに「実際の距離に極めて近い近似距離」を劇的に短い計算時間で導き出す「近似アルゴリズム」の研究が主流となった。
その評価軸となるのが「近似比(Approximation Ratio)」である。例えば「2-近似アルゴリズム」とは、算出される距離が「実際の最短距離と等しいか、最大でも2倍以内には確実に収まる」ことを数学的に保証するアルゴリズムを指す。実際の距離が10キロメートルであれば、アルゴリズムが弾き出す答えは10キロメートルから20キロメートルの範囲に必ず収まるということだ。
1996年の金字塔「DHZアルゴリズム」と長年のジレンマ
近似アルゴリズムの歴史において、1996年は極めて重要な年だ。研究者のDorit Dor、Shay Halperin、Uri Zwickの3氏(以下、DHZ)は、この年、APSP問題に対する非常に強力なアルゴリズムを発表した。
彼らのアルゴリズム(DHZアルゴリズム)は、計算時間をほぼ \(n\)の2乗(厳密には、微小なパラメータ \(k\)を用いて \(\tilde{O}(n^{2+O(1/k)})\)という時間計算量)に抑えつつ、2-近似を達成するという画期的なものであった。このアルゴリズムの根底にあるのは「代表点のサンプリング」というアイデアだ。ネットワーク内のすべての頂点から経路を探索するのではなく、ランダムに選ばれた一部の頂点(サンプル頂点)を基準点として活用し、ネットワーク全体の距離感を大まかに把握するという手法である。
しかし、この金字塔にも一つの大きな「アキレス腱」が存在していた。それは「十分に離れた頂点ペア」に対しては2-近似を保証できるが、「近接する頂点ペア」に対しては近似の精度が急激に悪化するという問題である。
具体的に言えば、DHZアルゴリズムは距離が \(k\)以上離れているペアに対しては正しく2-近似を保証した。しかし、距離が \(k\)未満の近いペアに対しては、推測された距離が実際の距離の2倍を大きく超えてしまう可能性があったのだ。
このジレンマは、現実世界のアナロジーを用いると直感的に理解できる。例えば、インドのデリーからチェンナイまでの長距離ルートを推測する場合、主要な大都市(サンプル頂点)だけを中継点として大まかに計算しても、実際の最短距離の2倍以内に収まる妥当なルートを容易に提示できる。しかし、ムンバイ市内の隣接する2つの郊外エリア間のルートを同じ手法で推測しようとするとどうなるか。大都市のみを基準とする大雑把なネットワークでは、本来ならすぐ隣にあるはずの目的地へ行くために、一度遠方の主要ハブ駅を経由するような極端な迂回ルートが提示されてしまう。結果として、実際の距離の3倍、4倍といった不正確な見積もりが出力されてしまうのである。
この「遠くの頂点ペアには有効だが、近くの頂点ペアには無力」というDHZアルゴリズムの制約は、その後25年以上にわたり、理論計算機科学における「未解決のギャップ」として重くのしかかっていた。
Manoj Gupta准教授によるブレイクスルー:距離の壁を打ち破る
Manoj Gupta准教授が成し遂げた偉業は、DHZアルゴリズムと同じ時間計算量(\(\tilde{O}(n^{2+1/k})\))を維持したまま、2-近似の保証が成り立つ頂点間の距離のハードルを \(k\)から \(O(\log k)\)へと劇的に引き下げたことである。
これは何を意味するのか。対数関数(\(\log\))の性質上、\(O(\log k)\)は \(k\)に対して非常に小さな値となる。論文によれば、変数を調整して \(k = \log n\)と設定した場合、実行時間はほぼ \(\tilde{O}(n^2)\)(ネットワークサイズの2乗に比例する理想的な計算量)となり、かつ、距離がわずか \(O(\log \log n)\)以上離れたすべての頂点ペアに対して2-近似が成立するようになる。
頂点数 \(n\)が数十億という途方もない数に達する巨大なネットワークであっても、\(\log \log n\) は一桁の微小な値にとどまる。つまり、Gupta准教授のアルゴリズムは、「ほぼ隣接していると言っていいほど近接した頂点ペア」に対しても、最悪計算時間を悪化させることなく、厳格な2-近似保証を与えることに成功したのである。ムンバイ市内の隣接する郊外エリア間であっても、極端な迂回ルートを提示することなく、正しい距離感を把握できるようになったのだ。
マルチスケールな「階層的頂点サンプリング」
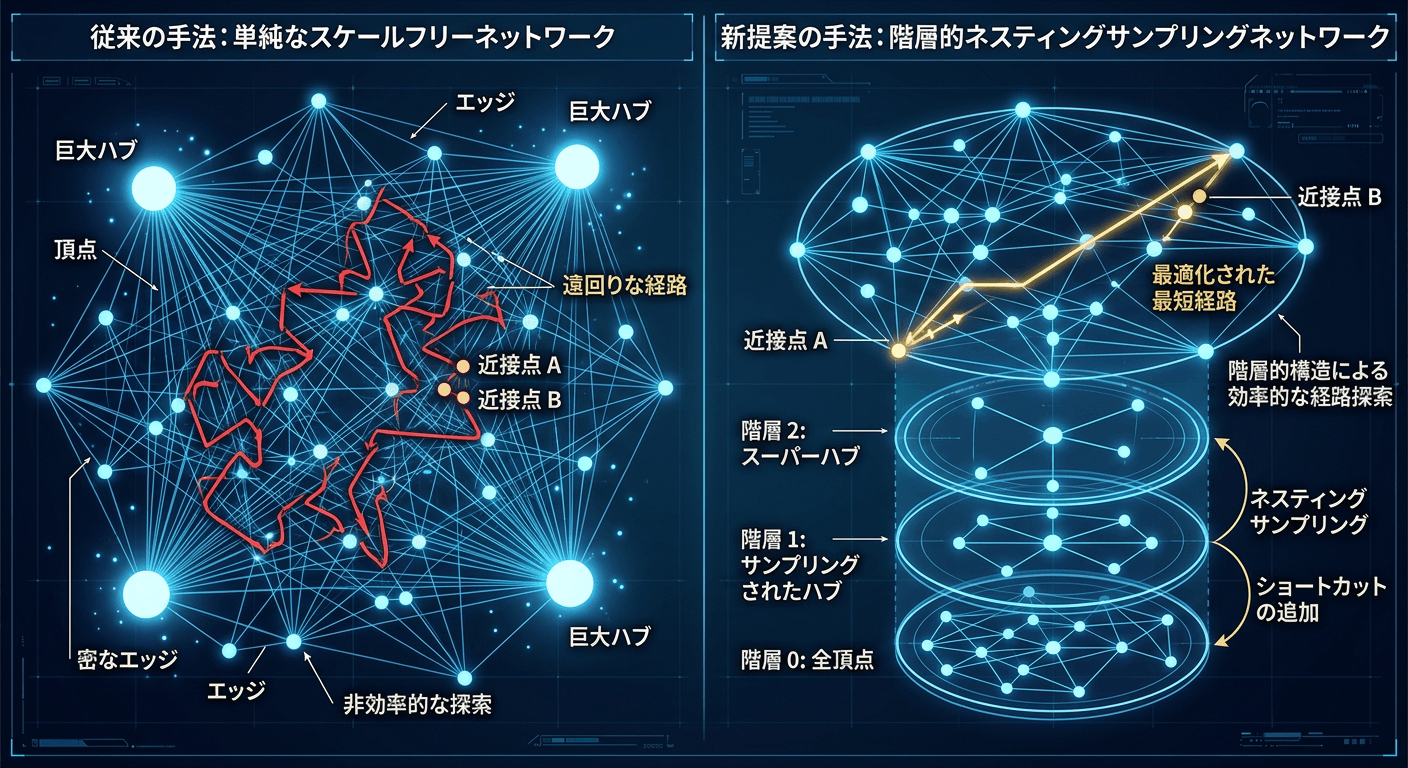
では、Manoj Gupta准教授はいかにしてこの長年のジレンマを克服したのか。その革新の核心は、単一のサンプリングに頼っていた従来の手法を脱却し、「マルチスケールな階層構造」をグラフ上に構築したことにある。論文内で「Nested Vertex Sampling(階層的頂点サンプリング)」と呼ばれるこの数学的アプローチが、近接ペアの距離推定を可能にした鍵である。
ピボット(Pivot)とボール(Ball)による空間の支配
Guptaアルゴリズムでは、ネットワーク上の頂点を一律に扱うのではなく、サンプリング確率を段階的に下げながら、複数の階層(レイヤー)を持った頂点部分集合の入れ子構造(\(A_0 \supset A_1 \supset A_2 \dots \supset A_{\log \log n – 1}\))を作成する。\(A_0\)はすべての頂点を含み、上位の階層になるほど、より「選ばれし少数の代表点」だけが残る。
この階層構造の上で、2つの重要な概念が導入される。
- ピボット(Pivot): ある頂点 \(s\)から見て、特定の階層 \(A_i\)の中で最も自分に近い代表頂点のこと。これは、その階層における自分専属の「最寄りの中継基地」と言える。
- ボール(Ball): ある頂点 \(s\)を中心とし、ピボットまでの距離を半径とする空間内に存在するすべての頂点の集合。ピボットより自分に近い領域(ボールの内部)には、その階層の代表点は存在しないという性質を持つ。
DHZアルゴリズムが抱えていた「近くの頂点ペアに対する推測のズレ」は、基準点となるサンプル頂点が遠すぎるために発生していた。Guptaアルゴリズムは、このピボットとボールの概念を巧みに操ることで、局所的な空間の徹底的な探索と、大域的な空間の効率的な推定をシームレスに結合させるのだ。
帰納的な距離推定と EnsureCloseness の魔法
距離の推定プロセスは、最も代表点が少ない上位の階層(長距離の推定に適したレイヤー)から始まり、徐々に下位の階層(局所的な推定を行うレイヤー)へと段階的に精度を上げていく「帰納法」のアプローチをとる。
アルゴリズムは、遠く離れたピボット間の距離情報を用いて、徐々に目標とする頂点ペア間の距離を絞り込んでいく。このとき、上位階層の粗い情報から下位階層の詳細な情報へとズームインしていく過程で、「目的地がボールの内部(つまり、代表点が配置されていない近接領域)に入り込んでしまう」という問題が発生する。これこそが、近接ペアの距離を正確に見積もれない根本原因であった。
この問題を解決するために、Gupta准教授は EnsureCloseness(近接性の確保)という独創的なサブルーチンを開発した。このプロセスは、局所的なボール内部のすべての頂点間のつながりを、計算量が爆発しない範囲で徹底的に事前計算し、補正をかけるものである。これにより、仮に「最寄りの中継基地」が遠方にしかなかったとしても、ボール内部の局所的な経路情報をつなぎ合わせることで、近接する頂点ペアに対しても「確実に実際の距離の2倍以内に収まる」という数学的な証明を成立させたのである。
理論計算機科学が切り拓く「スケーラブルな未来」
この発見は、一見すると抽象的な数学のパズルのように思えるかもしれない。しかし、基礎的なアルゴリズムの限界を押し広げることは、現実世界のインフラストラクチャーに甚大な影響を与える。
我々を取り巻くデータは、指数関数的な速度で増殖し、複雑に絡み合っている。インターネットの自律システム間のルーティング、都市の交通網におけるリアルタイムの渋滞予測と経路最適化、数十億人のユーザーを抱えるソーシャルプラットフォームでの関係性分析、さらには創薬プロセスにおいて必須となるタンパク質相互作用ネットワークの解析など、巨大なグラフ構造を瞬時に処理する能力は、現代のテクノロジーの限界を決定づける要因となっている。
「ネットワーク全体の大域的な構造」と「近接するノード間の局所的な関係性」という、相反するスケールの情報を、計算時間を犠牲にすることなく同時に、かつ高精度に把握できるようになったこと。これこそが、Manoj Gupta准教授のアルゴリズムがもたらした最大の恩恵である。
25年間、多くの研究者が挑み、跳ね返されてきた「近接ペアに対する2-近似の壁」。その壁が打ち破られたことは、単なる計算機科学の理論的なマイルストーンにとどまらず、今後さらに巨大化し複雑化する情報化社会において、世界中のあらゆるノードを効率的につなぎ合わせる「スケーラブルなエンジンの設計図」を人類が手に入れたことを意味している。
科学の歴史は、このような目に見えない理論の基盤が一段階アップデートされることで、後続の応用技術が一気に花開くというプロセスを繰り返してきた。1996年から2025年へと繋がれた知のバトンは、未来のネットワーク社会をより強靭で最適化されたものへと導いていくだろう。
論文
- IEEE Xplore: all-pairs-shortest-paths-algorithm-breakthrough
参考文献