
Google DeepMindから、Geminiシリーズの最軽量かつ最速の階層を担う「Gemini 3.1 Flash-Lite」のプレビュー版が公開された。前世代であるGemini 2.5 Flash-Liteの後継として位置付けられる本モデルは、処理速度の向上と推論能力の強化を両立させている一方で、出力コストが3倍以上に跳ね上がるという、これまでのLLM(大規模言語モデル)の低価格化トレンドとは一線を画す価格設定が行われている。本稿では、公開されたベンチマークデータや技術仕様から、Googleがこのモデルを通じてどのような市場戦略を描いているのか見ていこう。
推論能力の底上げ:ベンチマークが示す相対的位階の変動
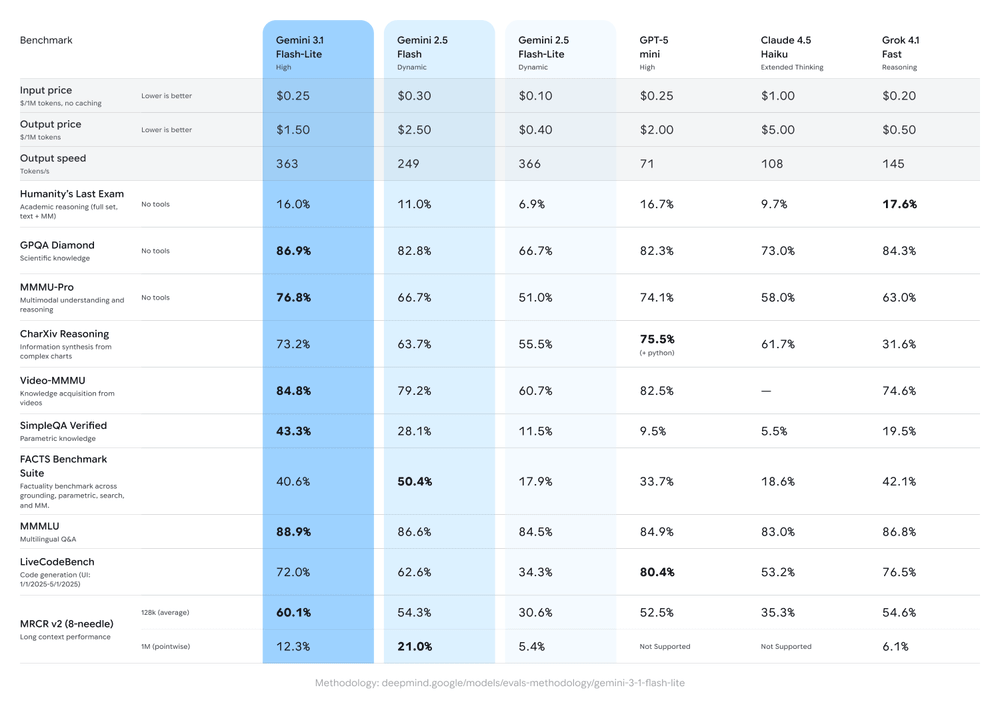
Gemini 3.1 Flash-Liteの最大の特徴は、軽量モデルとしての枠組みを超えた基礎推論能力の向上である。Arena.aiのリーダーボードにおいて1432というEloスコアを記録し、GPQA Diamondで86.9%、MMMU Proで76.8%という数値を叩き出した。これらの結果は、同等のクラスに属するモデルを上回るだけでなく、前世代の上位モデルであるGemini 2.5 Flashすらも凌駕する水準に達している。
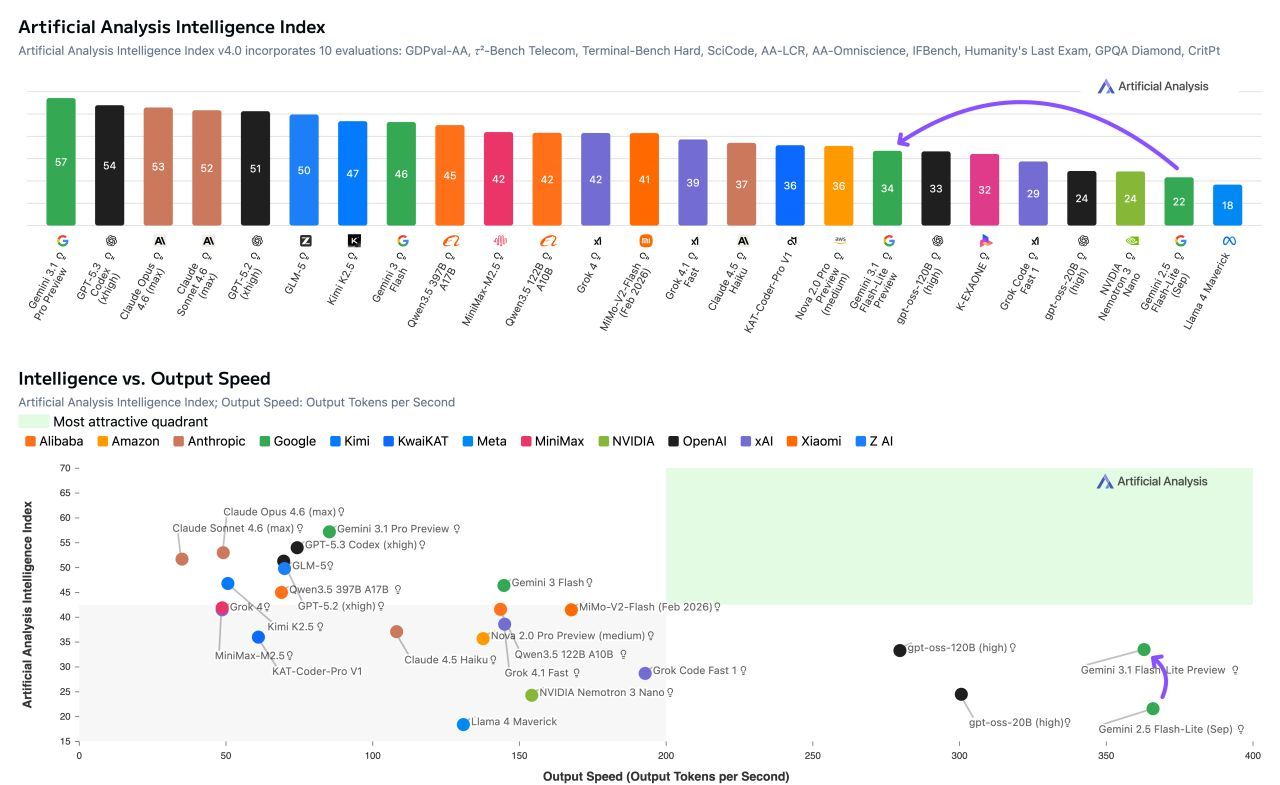
第三者評価機関であるArtificial Analysisのレポートによれば、同社のIntelligence IndexにおいてGemini 3.1 Flash-Liteはスコア34を獲得した。これはGemini 2.5 Flash-Lite(スコア22)から12ポイントの顕著な改善である。とりわけ、マルチモーダル推論能力を測定するMMMU-Proにおいて78%を記録し、AnthropicのClaude Opus 4.6やKimi K2.5といったフロンティアクラスのモデルを部分的に上回っている事実は特筆に値する。Googleは元来マルチモーダルアーキテクチャに強みを持つが、その恩恵が最軽量モデルであるFlash-Liteにも色濃く反映されている。計算資源を制約した中で、テキスト、画像、音声を跨いだ高度な推論を可能にしている点は、他社に対する強固な競争優位性である。
しかし、全ての指標で劇的な改善が見られるわけではない。ツールの使用能力機能(Tool use capabilities)に関する評価では、Tau2-Telecomで31%と前モデルから据え置きの状態であり、GDPval-AAでも958と、トップ層(gpt-oss-120bの970など)には及ばない領域が存在する。基礎的な地頭の良さは向上しつつも、複雑なエージェント的タスクの完全自律実行機能においては、まだ上位ティアのモデルに分があると言える。
極限のレイテンシと「思考レベル」の標準実装
処理速度の観点からは、Gemini 3.1 Flash-Liteは1秒間に360以上の出力トークンを生成するという数値を記録している。Average answer latency(平均回答遅延)は5.1秒であり、これは第一者のAPIエンドポイントとして提供されるモデルの中で最速クラスにある。特筆すべきは、Time to First Answer Token(最初の回答トークンが生成されるまでの時間)がGemini 2.5 Flashと比較して2.5倍高速化している点である。
この高速性こそが、Gemini 3.1 Flash-Liteの本来の主戦場を決定づけている。すなわち、リアルタイム性が厳しく要求される動的ダッシュボードの生成、高頻度の金融データフィード処理、SaaSプラットフォーム上での多段階タスクの即時実行といったワークロードである。公開されたデモンストレーションにおいても、最新の天気予報や過去のデータを元にした動的ダッシュボードの生成や、大量の画像コンテンツの瞬間的な分類処理が提示されている。
さらに今回、Google AI StudioおよびVertex AIにおいて「思考レベル(Thinking levels)」が標準機能として提供された。これは、タスクの複雑さに応じてモデルが回答を生成する前の「思考時間(計算資源)」を開発者が動的に調整できる機能である。単純な自動翻訳やコンテンツモデレーションのような高ボリュームかつ単調なタスクでは思考を最小化し、UIコンポーネントの生成や複雑なインストラクションへの追従が求められるタスクでは思考を深めるといった柔軟なリソース配分が可能になる。
コスト構造の逆転現象:性能向上の代償としての価格改定
Gemini 3.1 Flash-Liteの実装において、開発者エコシステムに最も大きな波紋を呼んでいるのがその価格設定だ。入力トークンあたり100万トークンで0.25ドル、出力トークンで1.50ドルという価格が設定されている。これは、入力と出力の比率を3対1とした複合価格で計算した場合、前モデルであるGemini 2.5 Flash-Liteから3倍以上という大幅な値上げを意味する。Artificial AnalysisによるIntelligence Indexの実行コスト測定においても、前モデルの38ドルから94ドルへと上昇している。
これまで、AIモデルのバージョンアップは「性能向上かつ低価格化」が業界の暗黙の定石であった。計算効率の改善とインフラの最適化によって、世代が進むごとにトークン単価は下落する傾向にあった。今回、Googleがこの定石を破り、最軽量モデルで大幅な値上げに踏み切った背景には、業界全体の構造的な変化が見え隠れする。
一つの要因として、モデル内部における「思考プロセス」の組み込みが推論コストを押し上げている可能性が高い。表面的な出力を行う前に内部空間で推論ステップを踏む構成(あるいはそれに類するアーキテクチャの変更)は、ユーザーに見えるトークン数以上のコンピュートを要求する。品質とマルチモーダル能力を上位モデル並みに引き上げるための計算リソースの増加が、価格に転嫁されていると解釈できる。
また、APIプロバイダー各社が初期の市場シェア獲得のために行っていた「原価割れのダンピング(価格競争)」が終わりを迎え、持続可能な収益モデルへの移行フェーズに入ったとも捉えられる。安価なトークンを大量に消費させる段階から、確実な推論結果を適正な価格で提供する段階へのパラダイムシフトである。
開発者と企業の選択:新たなROIの算定基準
この価格改定は、企業や開発者に対するモデル選択の算定基準(ROIの考え方)を複雑化させる。出力コストが1.50ドル/1Mトークンに達したことで、一部の単純なバルク処理(数千万件の単純なテキストフィルタリングなど)においては、旧モデルの継続利用、あるいは他社の超安価なオファリングを模索する動機付けとなる。実際、OpenAIのGPT-5 miniやAnthropicのClaude 4.5 Haiku、さらにはGrok 4.1 Fastといった競合モデルが存在する中で、単なるコスト単価だけで勝負することは難しくなった。
しかし、アプリケーションの全体設計の観点から見れば、Gemini 3.1 Flash-Liteの価値算定は単純なトークン単価に留まらない。高速化によるユーザー体験の向上、より正確な出力による後工程のエラー処理コストの削減、マルチモーダル入力の一元的処理によるアーキテクチャの簡略化といった要素を含めて総合的なROIを評価する必要がある。特に、これまで上位の高価なモデル(Gemini AdvancedクラスやGPT-4/5クラス)でしか達成できなかった精度のタスクにおいて、このFlash-Liteで十分な品質が担保されるのであれば、トータルとしての運用コストはむしろ下落する可能性もある。
Googleが示しているのは、単一の静的なモデルによる画一的な処理ではなく、「思考レベル」を用いた可変的なリソースの割り当てによる最適化である。軽量モデルの定義は「単にパラメーター数が少なく安価なもの」から、「開発者が要求水準に合わせて精度と速度とコストのバランスを動的にチューニングするための柔軟な基盤」へと変容しつつある。Gemini 3.1 Flash-Liteの登場は、AIアプリケーションのアーキテクチャ設計がいかにコンピュートの効率的配分というソフトウェア工学の原点へと回帰しているかを示す鮮明な事例である。
Sources


