

Intelは、米フェニックスで開催された「Vision 2024」カンファレンスにおいて、新しいAIアクセラレーター「Gaudi 3」を正式に発表した。

Intelは、Gaudi 3はOEM システムで量産され、2024年第3四半期に一般提供されるが、顧客向けサンプルを既に出荷していることを明らかにした。性能面ではNVIDIA H100 GPUよりも最大50%高速な推論を実現し、さらに40%優れた効率性を備えながら、はるかに安価だと主張している。だが、先日NVIDIAは次世代GPU Blackwellを発表しており、そちらはH100比で最大5倍の演算性能を誇ると主張している。
Intel Gaudi 3の仕様
IntelのGaudi 3は、Intelが2019年に買収したHabana Labsの開発したGaudiアクセラレーターの最新版だ。
Gaudiには2つのフォームファクターがあり、OAM(OCP Accelerator Module)HL-325Lは、高性能GPUベースのシステムで見られる一般的なメザニンフォームファクターとなる。驚いたのは、HBM3Eはまだ早いにしても、HBM3もサポートされていない点だ。ここでIntelがHBM2eにこだわった理由は不明だ(HBM3の方がメモリ帯域幅が広く、メモリ容量も大きい)。利用可能な最大容量のスタックは16GBで、アクセラレーターは合計128GBのメモリを搭載する。これは3.7Gbps/ピンでクロックされ、総メモリ帯域幅は3.7TB/秒となる。各Gaudi 3ダイは4つのHBM2e PHYを提供し、チップの合計メモリスタックは8スタックとなる。
また、24個の200GbpsイーサネットRDMA NICも搭載している。HL-325L OAMモジュールのTDPは900Wで(液冷を利用すれば、より高いTDPも可能)、FP8性能は1,835TFLOPSとされている。OAMはサーバー・ノードごとに8台ずつ配置され、最大1,024ノードまで拡張可能だ。
OAMは、8個のOAMを収納するユニバーサル・ベースボードにドロップされる。Intelは、今年後半の一般提供に向けて、すでにOAMとベースボードをパートナーに出荷している。HLB-325ベースボード上のOAMを8個に拡張すると、性能はFP8で14.6PFLOPSとなり、メモリ容量や帯域幅など他のすべての指標はリニアに拡張される。
また、Gaudi 3には、TDP 600WのGaudi 3 PCIeデュアルスロットアドインカードも用意される。このカードも128GBのHBMeEと24個の200GbpsイーサネットNICを搭載しており、Intelによればスケールアウトにはデュアル400Gbps NICが使用されるという。しかし、4つのグループで動作するように設計されているため、ボックス内のスケーリングはより制限されている。Intelは、このカードはより大きなクラスタを作成するためにスケールアウトすることもできると述べているが、詳細は明らかにしていない。

アーキテクチャに目を向けると、Gaudi 3は、Gaudi 2のハードウェアをそのまま進化させたものだ。前世代のGaudi 2アクセラレーターはTSMCの7nmプロセスで製造されていたが、Gaudi 3では新たな5nmプロセスに移行している。
Gaudi 3は、96MBのSRAMを2つのダイに分割した2つの5nmダイを中心に持ち、12.8TB/秒の帯域幅を提供する。このダイの両側には、合計128GBのHBM2Eパッケージが8個配置され、最大3.7TB/秒の帯域幅を実現する。2つのダイ間の高帯域幅インターコネクトは、両方のダイに存在するすべてのメモリへのアクセスを提供するため、1つのデバイスとして見え、動作することができる。また、ホストプロセッサ(CPU)との通信用にx16 PCIe 5.0コントローラも搭載しており、CPUとGaudiアクセラレータの異なる比率を採用することができる。
Gaudi 3のダイは、Gaudi 2の2つのMatrix Math Engineと24個のテンソル処理コア(TPC)から、64個の第5世代TPCと8個の行列演算エンジン(MME)によって処理され、ワークロードはグラフコンパイラとソフトウェアスタックによって2つのエンジン間でオーケストレーションされる。Gaudi 3でのアーキテクチャの変更が限定的であることから、これらのTensor CoreはGaudi 2と同様に256バイト幅のVLIW SIMDユニットであると推測される。Gaudi 3チップパッケージには、24個の200Gbps RoCEイーサネットコントローラーも含まれており、スケールアップ(インボックス)とスケールアウト(ノード間)の両方の接続性を提供し、Gaudi 2の100Gbps接続を2倍にしている。
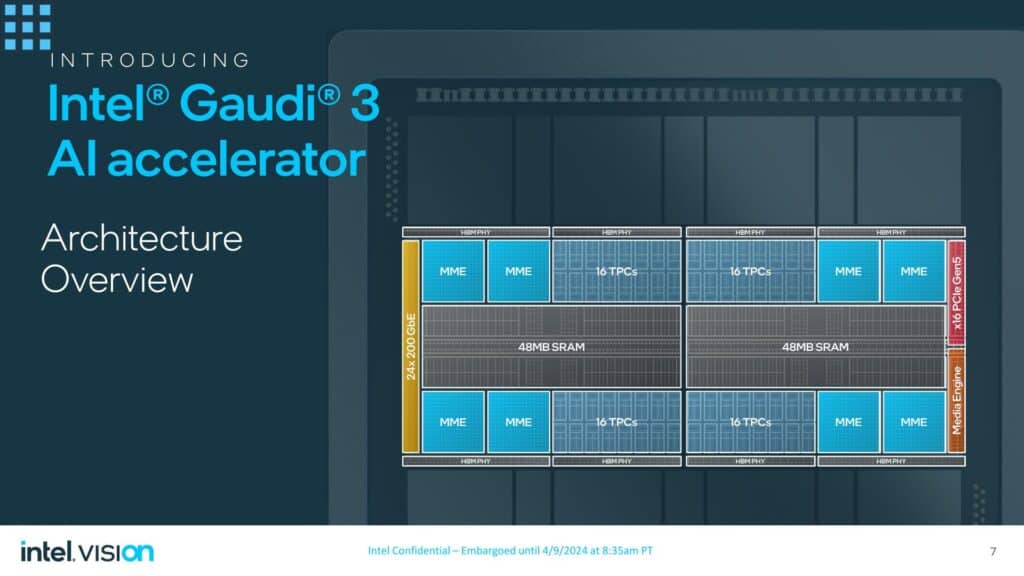
Intelは、Gaudi 3は前世代に比べ、FP8で2倍、BF16で4倍の性能を発揮し、ネットワーク帯域幅は2倍、メモリ帯域幅は1.5倍であるとしている。

基本的な空冷式Gaudi 3アクセラレーターのTDPは900Wで、前モデルの600Wより50%高い。IntelはOAM 2.0フォームファクターを採用しており、OAM 1.x(700W)よりも高い電力制限を実現している。しかし、Intelは、さらに高いTDPと引き換えに高い性能を提供する液冷バージョンのGaudi 3も開発し、認定を進めている。すべてのGaudi 3は、PCIeバックホールを使用してホストCPUに接続し、Gaudi 3はPCIe Gen 5 x16リンクを搭載する。

ネットワーキング極限まで進化したイーサネット
Gaudi 3のコアアーキテクチャ以外で、Gaudi 3で行われたもう1つの大きな技術的アップグレードは、I/O面である。Gaudi 2は、チップあたり24個の100Gb Ethernetリンクを提供していたが、Gaudi 3は、これらのリンクの帯域幅を200Gb/秒に倍増させ、チップの外部Ethernet I/O帯域幅の合計を8.4TB/秒の累積アップ/ダウンとした。
Gaudi 3の推奨トポロジー(Intelが自社のベースボードで採用するトポロジー)は、21/3分割である。21のリンクがオンノードのチップ間接続に使用され、3つのリンクがフル実装の8ウェイノード上の他の7つのGaudi 3アクセラレータにそれぞれ接続される。
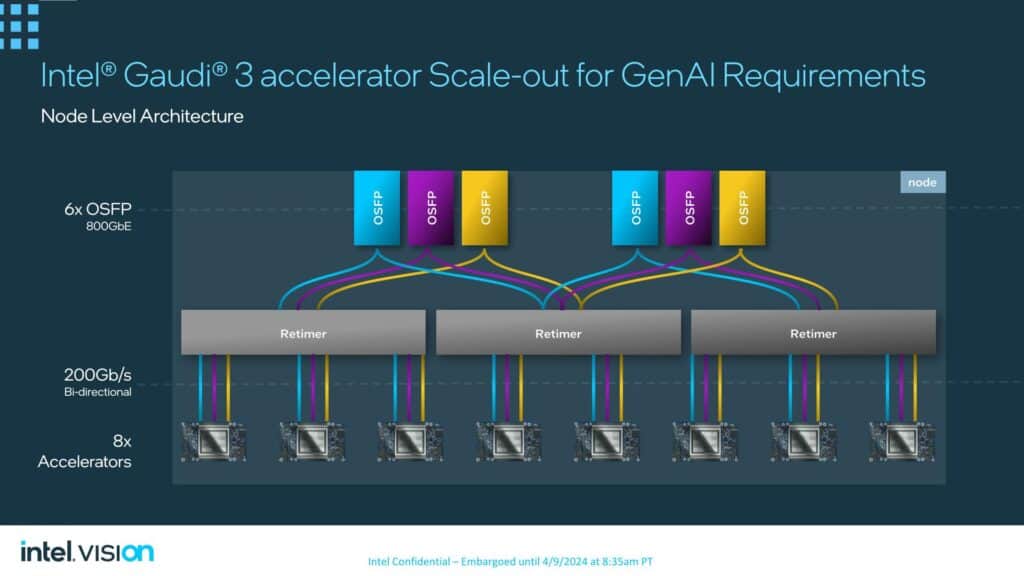
一方、各チップからの残りの3つのリンクは、6組の800Gb Octal Small Form Factor Pluggable(OSFP)イーサネット・リンクに使用される。リタイマーを使用することで、ポートは2つのブロックに分割され、5つのアクセラレーターでバランスされる。
最終的にIntelは、パフォーマンスと市場性の両面から、Gaudi 3のスケーラビリティを押し上げようとしている。最大規模のLLMでは、トレーニングに必要なメモリと計算性能を提供するために、多くのノードを連結して1つのクラスターを形成する必要があるため、IntelがGaudi 3で追い求める最大の顧客は、このような大規模にスケールアウトできるAIアクセラレーターを必要とするだろう。その一方で、純粋なイーサネットを採用することで、Intelは、InfiniBandのような独自のインターコネクトや代替インターコネクトに投資したくない顧客に訴求したい様だ。
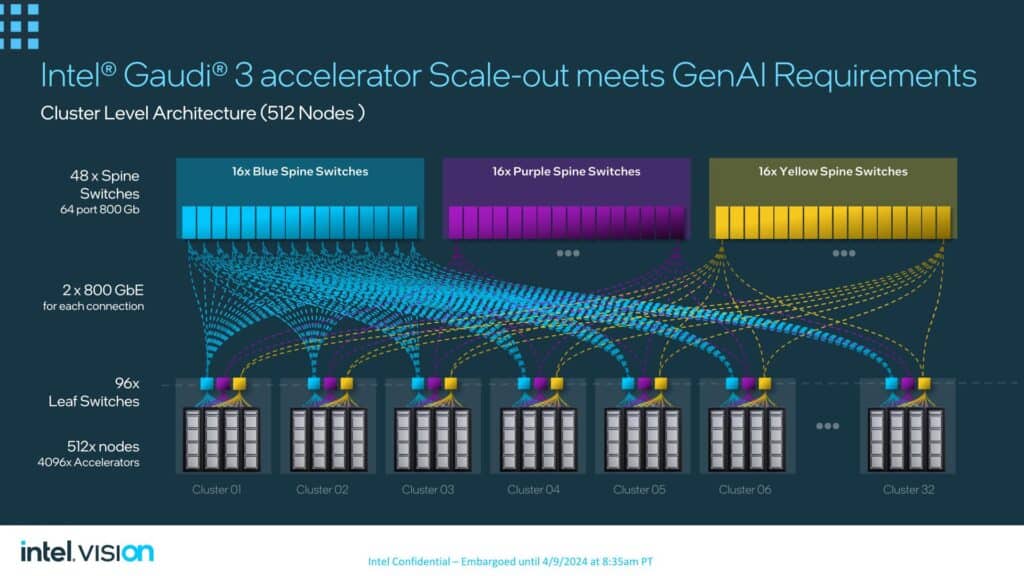
最終的に、Intelはすでに512ノードのネットワーク・トポロジーを開発済みで、48台のスパイン・スイッチを使って最大32クラスタ(各クラスタは16ノードを収容)を接続する。Intelによれば、Gaudi 3はさらに数千ノードまで拡張可能だという。
Gaudi 3のベンチマーク
IntelはGaudi 3の性能予測を発表したが、メーカーのベンチマークテストはいささか注意してみる必要がある。Intelは、H100システムについては公開されているベンチマークと比較したが、NIVIDAの次期Blackwell B200との比較は、実世界での比較データが不足しているため行わなかった。同社はまた、AMDの有望なInstinct MI300 GPUとの比較も行っていないが、AMDが業界で認められているMLPerfベンチマークで公開された性能データの公表を避け続けているため、それは不可能だ。
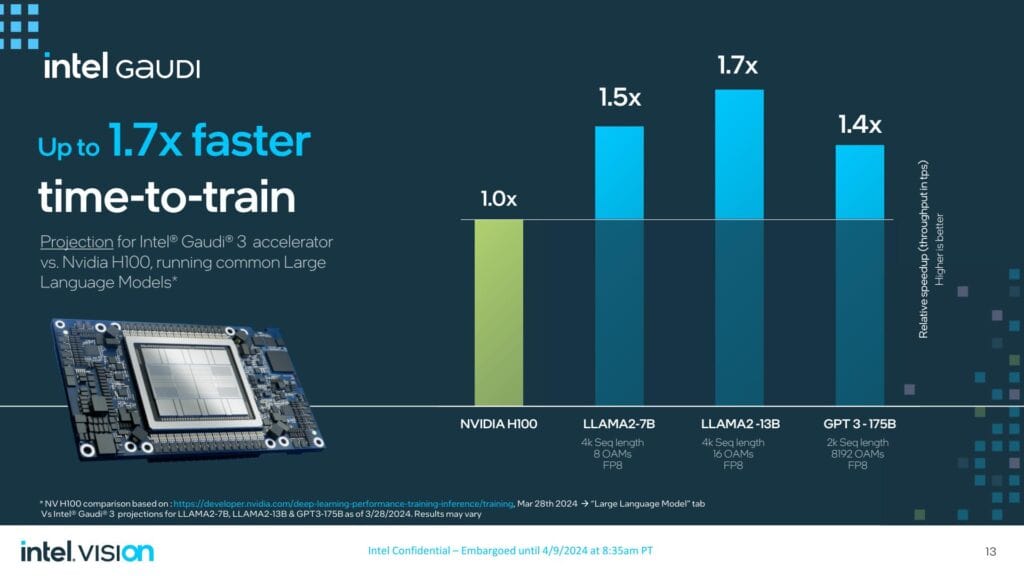
H100と比較して、Intelは、16アクセラレーター・クラスターのLlama2-13BのFP8精度でのトレーニングにおいて、Gaudi 3がH100を最大1.7倍上回るはずだと主張している。H100は2年前にリリースされたものだが、H100をかなりの程度上回ることができれば、Intelにとっては大きい収穫だ。
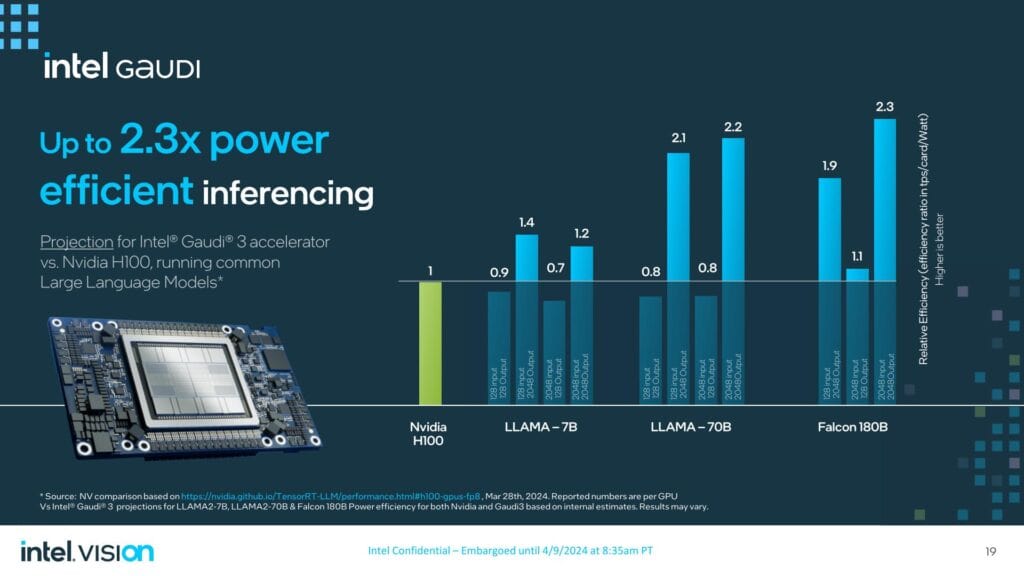
一方、Intelは、Gaudi 3を搭載したH200/H100の1.3倍から1.5倍の推論性能、そしておそらく最も注目すべきは、最大2.3倍の電力効率を予測している。
しかし、これらの推論ワークロード(特に2K出力のないワークロード)において、H100に負けることもある。もちろん、Intelが(意図的に)宣伝していないベンチマーク結果もある。
Intelは推論比較でH200と比較したが、クラスタによるスケールアウト性能の比較とは対照的に、カード1枚での性能にこだわった。LLAMA2-7B/70Bワークロードのうち5つがH100 GPUを10~20%下回る一方、2つはH200と同等、1つはH200をわずかに上回っている。Intelは、Gaudiの性能はより大きな出力シーケンスでより良くスケールすると主張しており、Gaudiは、2048レングスの出力を持つFalcon 1800億パラメータモデルで、最大3.8倍の性能を発揮している。
Intelはまた、推論ワークロードの消費電力において最大2.6倍のアドバンテージがあると主張している。これは、データセンターにおける制限された消費電力を考慮する上で重要な考慮事項であるが、トレーニングワークロードについては同様のベンチマークを提供していない。これらのワークロードについて、IntelはパブリックインスタンスでH100を1台テストし、H100の消費電力を記録した(H100が報告したもの)。より大きな出力シーケンスの場合、Intelは再び、より優れたパフォーマンス、ひいては効率性を主張している。
Gaudi 3のソフトウェアエコシステム
CUDAにおけるNVIDIAの優位性が示すように、ソフトウェア・エコシステムはハードウェアと同様に重要な検討事項である。Intelはエンド・ツー・エンドのソフトウェア・スタックを売りにしており、現在エンジニアの「ほとんど」がサポートの強化に取り組んでいるという。Intelが現在注力しているのは、マルチモーダル・トレーニングと推論モデル、そしてRAG(検索拡張生成)のサポートだ。
Hugging Faceには60万を超えるAIモデルのチェックポイントが用意されており、INtelによれば、Hugging Face、PyTorch、DeepSpeed、Mosaicとの連携により、ソフトウェアの移植プロセスが緩和され、Gaudi 3システムの展開に要する時間が短縮されたという。また、ほとんどのプログラマーはフレームワークレベルかそれ以上のプログラミング(つまり、単にPyTorchを使用したり、Pythonでスクリプトを書いたり)をしており、CUDAを使用した低レベルのプログラミングは認識されているほど一般的ではないという。
Intelのツールは、基礎となるカーネルと通信ライブラリとしてOneAPIが機能することで、基礎的な複雑さを抽象化しつつ、移植プロセスを容易にするように設計されている。これらのライブラリは、Arm、Intel、Qualcomm、Samsungなどが参加する業界コンソーシアムであるUnified Accelerator Foundation(UXL)によって概説された仕様に準拠しており、CUDAに代わるものを提供することを目的としている。PyTorch 2.0は、Intel CPUやGPUでの推論やトレーニングにOneAPIを使用するように最適化されている。Intelによると、OpenVinoも急速な普及を続けており、今年これまでに100万ダウンロードを超えたとのことだ。
Gaudi 3のPCIeバージョンは、OAMモジュールの液冷バージョンと並んで、今年の第4四半期に発売される予定だ。
Sources









コメント