

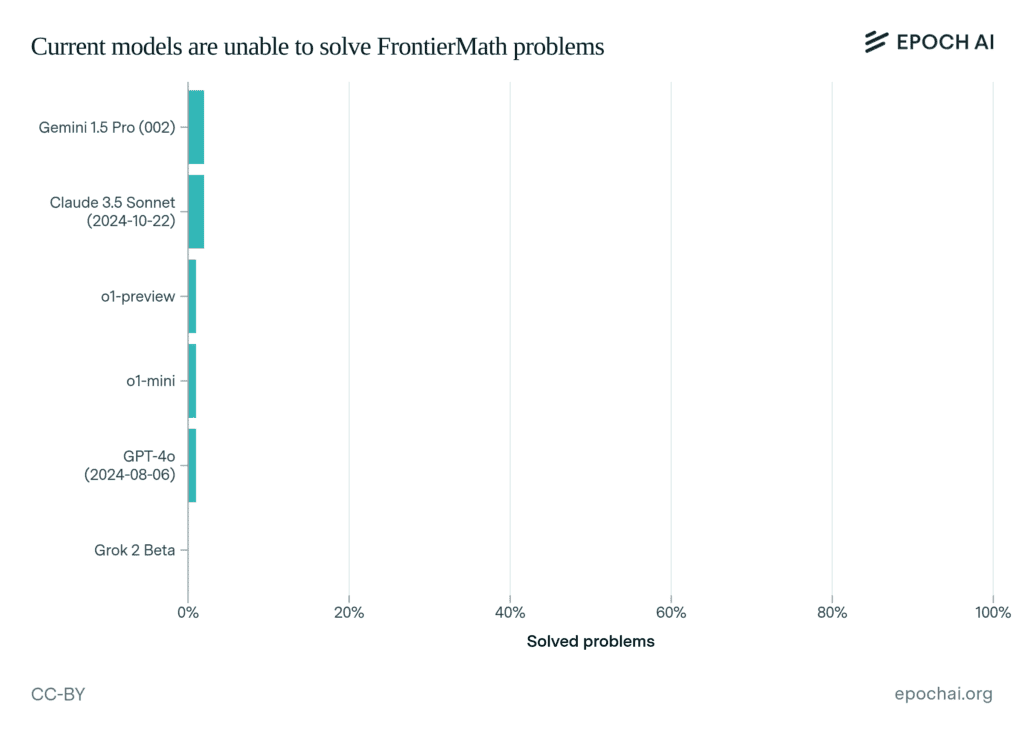
人工知能(AI)の進化が加速度的な発展を遂げ、画像生成や自然言語処理で人間の能力に迫る成果を上げる中、その限界を鮮明に示す新たな指標が登場した。AI研究機関Epoch AIが開発した高度な数学ベンチマークテスト「FrontierMath」において、GPT-4o、Claude 3.5、Gemini 1.5 Proといった最先端AIモデルの正解率が2%未満という衝撃的な結果となった。この結果は、AIの数理的推論能力の現状と本質的な課題を浮き彫りにし、真の人工知能実現への道のりがこれまでの予想以上に遠いことを示唆している。特に注目すべきは、これらのモデルが他の標準的な数学テストでは90%以上の高得点を記録していた点であり、AIの理解力と推論能力の真の姿を映し出す鏡として、FrontierMathの重要性が浮かび上がっている。
従来の数学ベンチマークとの決定的な違い
GPT-4oやOpenAI o1、ClaudeやGeminiと言った最先端のAIモデルは、GSM-8KやMATHのような数学ベンチマークで現在90%以上のスコアを出していると、その華々しい成績を誇示しているが、これは本質的に“データの汚染”による結果である事が指摘されている。これは、AIモデルは、テストセットの問題に酷似した問題で学習されることが多いため解き慣れた問題の成績が向上するのは当然と言える。
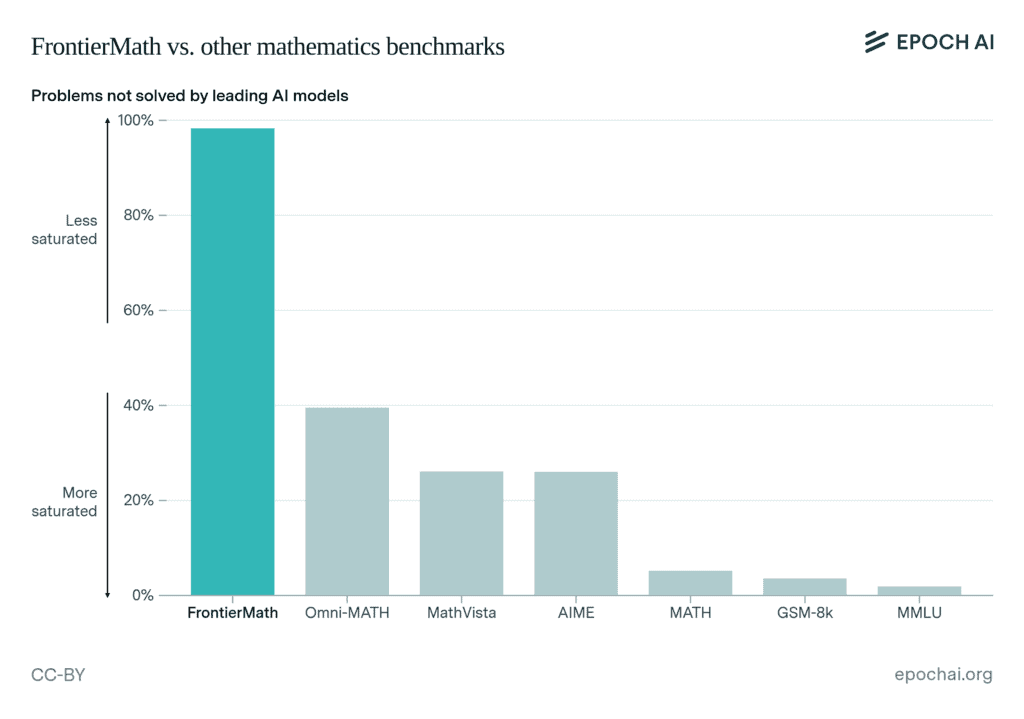
「GSM8KやMATHのような既存の数学ベンチマークは飽和状態に近づいており、AIモデルのスコアは90%を超えている。 FrontierMathは、そのハードルを大幅に引き上げます」と、Epoch AIはXで述べ、このデータ汚染に対処し、真にAIの能力を測ることが今回のFrontierMathの目的であると述べている。
FrontierMathは、60人以上の一流数学者との緊密な協力のもとで開発された、未公開の研究レベルの数学問題群である。このベンチマークの特筆すべき点は、すべての問題が新規に作成され、これまでのAIの学習データには含まれていない点にある。問題の範囲は計算型数論から抽象代数幾何学まで多岐にわたり、各分野の専門家でも解くのに数時間から数日を要する高度な内容となっている。
フィールズ賞受賞者のTimothy Gowers氏は「私が見た問題は、どれも私の専門外で解き方が分からないものばかりだった。これらは国際数学オリンピック(IMO)の問題とは全く異なるレベルの難しさを持っている」と評価している。同じくフィールズ賞受賞者のTerence Tao氏も「これらは極めて難しい問題だ。近い将来解けるとすれば、その分野の大学院生とAI、そして高度な代数パッケージを組み合わせる以外に方法はないだろう」と指摘し、問題の革新性と困難さを強調している。
AIの数学的推論能力の限界
FrontierMathが露呈させたのは、現代AIの本質的な限界である。これらのモデルは単純なパターン認識や既存知識の組み合わせでは対応できない、創造的な数学的思考を要求される。各問題は厳密な「推測防止」設計がなされており、正しい数学的理解なしには1%未満の確率でしか正解にたどり着けない仕組みになっている。この設計により、AIが単純なパターンマッチングや確率的な推測で解答することを防いでいる。
テストされた6つの主要モデルには、Pythonによる仮説検証や中間結果の確認機能など、充実した支援環境が提供された。にもかかわらず、2%以上の問題を解くことはできなかった。特に注目すべきは、これらのモデルがGSM-8KやMATHといった既存のベンチマークでは90%を超える高いスコアを記録していた点である。この著しい成績の差は、AIが表面的なパターン認識には長けているものの、深い理解と論理的推論を必要とする問題では著しく能力が低下することを示している。
数学的推論から見えるAIの未来と課題
AI研究者のMatthew Barnett氏は、FrontierMathの意義について重要な指摘を行っている。「FrontierMathは本当に極めて難しい。地球上のほとんどの人が、一日かけても0%のスコアしか取れないだろう。しかし、このベンチマークはAIの真の知的能力を測る重要な指標となる」と述べ、AIの進化における重要な分岐点としてこのテストを位置づけている。
さらにBarnett氏は「FrontierMathが完全に解けるようになった時、我々は真に知的な人工の存在と地球を共有することになる」と、このテストの達成がAGI(Artificial General Intelligence)実現の重要な指標となる可能性を示唆している。元OpenAI開発者のAndrej Karpathyも、これらの結果がモラベックのパラドックスの新たな側面を示していると指摘し、AIが明確なルールを持つ複雑なタスクには強い一方で、人間にとって容易な直感的問題解決に苦手を示す傾向を改めて浮き彫りにした。
Epoch AIは今後、ベンチマークの拡張と定期的な評価の実施を計画している。数学という普遍的な領域でAIの推論能力を評価し続けることで、人工知能の発展度合いを客観的に測定することが可能になる。また、このような評価基準の存在は、AIの実際の能力と限界について、より現実的な理解を促し、今後の開発方向性に重要な示唆を与えると考えられている。
Sources









コメント