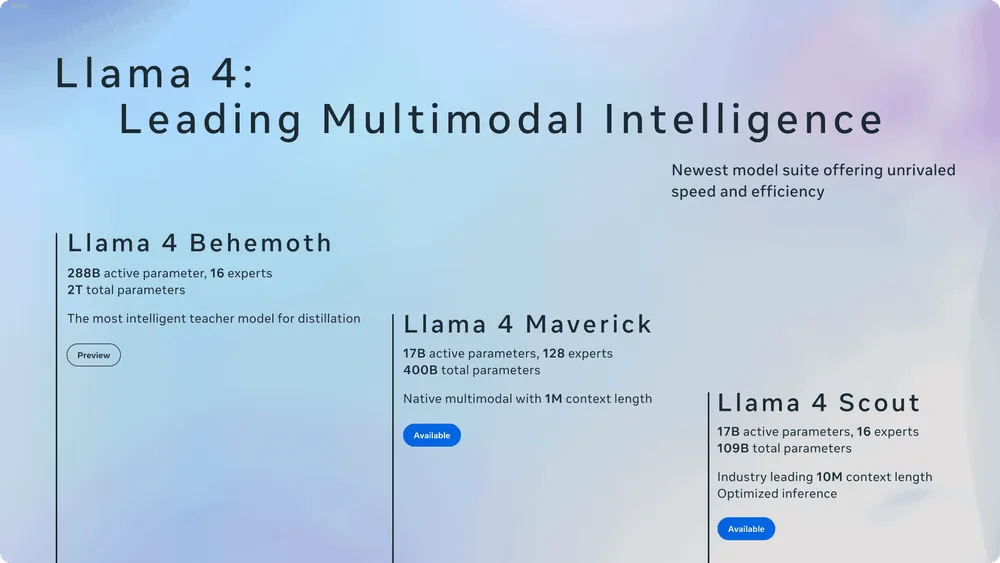
Metaが最新の大規模言語モデル(LLM)ファミリー「Llama 4」を発表した。Llama 4は、ネイティブなマルチモーダル機能、効率的なMixture-of-Experts (MoE) アーキテクチャ、そして最大1000万トークンという驚異的なコンテキスト長を備え、「Maverick」「Scout」「Behemoth」の3モデルで構成されている。多くのベンチマークで競合他社を上回り、オープンソースAIの新時代を切り開く野心的な取り組みとなっている。
Meta、次世代AI「Llama 4」ファミリーを発表
Metaは、パーソナライズされたマルチモーダル体験の構築を可能にするため、Llama 4シリーズの最初のモデル群として「Llama 4 Scout」と「Llama 4 Maverick」を公開した。これらは、Llamaエコシステム全体をサポートする、これまでで最も先進的なモデル群と位置付けられている。
同時に、Meta史上最も強力で、世界トップクラスの性能を持つとされる教師モデル「Llama 4 Behemoth」のプレビューも行われた。Behemothは現在もトレーニング中であり、ScoutとMaverickの性能向上に貢献している。
Metaはオープンソースがイノベーションを推進するという信念に基づき、MaverickとScoutをllama.comおよびHugging Faceにてダウンロード可能にした。また、MetaのAIアシスタント「Meta AI」もLlama 4を基盤としてアップデートされ、WhatsApp, Messenger, Instagram Direct, Meta.AI Webサイトで利用が開始されている(マルチモーダル機能は現時点で米国内英語のみ)。
注目すべき点として、Llama 4のライセンスには制限がある。EU圏に居住または主たる事業所を持つユーザーや企業は、モデルの使用や配布が禁止されている。これは、EUのAI法やデータプライバシー法の要件に対応したものと見られる。また、従来通り、月間アクティブユーザー数が7億人を超える企業は、Metaから別途特別なライセンスを取得する必要がある。
Llama 4の技術革新:マルチモーダル、MoE、超長文対応
Metaによれば、Llama 4には、いくつかの重要な技術的進歩が見られるとのことだ。
ネイティブマルチモーダル設計:テキスト・画像・動画を統合
Llama 4は、テキストと視覚情報(画像・動画フレーム)をシームレスに統合する「アーリーフュージョン」と呼ばれるアプローチを採用した、Meta初のネイティブマルチモーダルモデルである。これにより、大量のラベルなしテキスト、画像、動画データを用いた共同事前学習が可能となり、より深いレベルでのマルチモーダル理解を実現した。視覚エンコーダーもMetaCLIPをベースに改良され、LLMとの連携が強化されている。事前学習では最大48画像、ポストトレーニングでは最大8画像での良好な動作が確認されているとのことだ。
Llamaシリーズ初のMoEアーキテクチャ採用
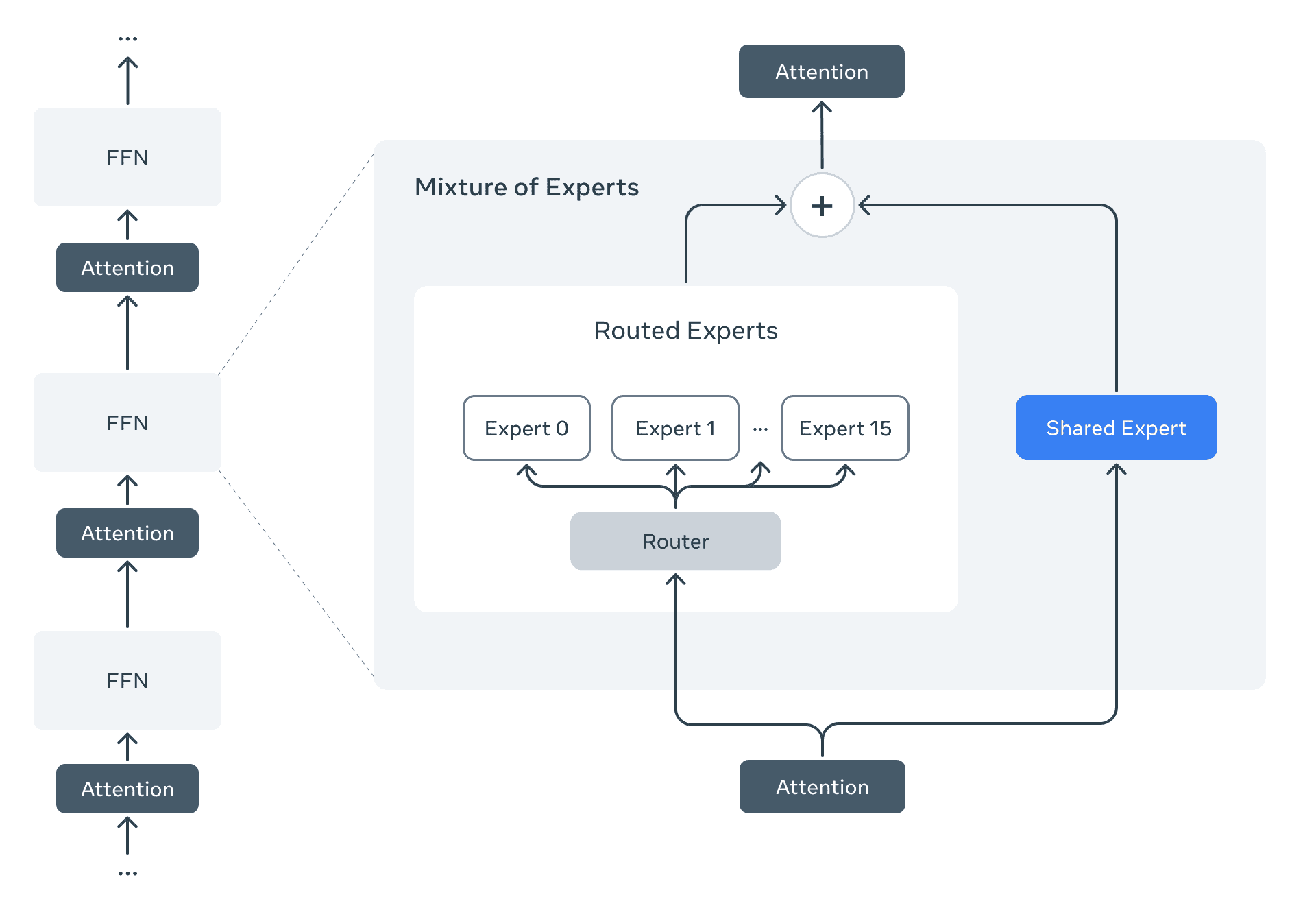
Llama 4は、Llamaファミリーとして初めてMixture-of-Experts (MoE) アーキテクチャを採用した。MoEは、モデル内の一部の「エキスパート」と呼ばれる小さなネットワークのみを特定の入力に対して活性化させる仕組みだ。これにより、トレーニングと推論の両方で計算効率が大幅に向上し、同等の計算リソースでより高品質なモデルを構築できる。DeepSeekのV3やR1でも採用され、その効率性が大きく話題になった技術だ。
例えば、Llama 4 Maverickは総パラメータ数4000億に対し、実際に活性化するのは170億パラメータと128のエキスパートの一部である。これにより、推論時のコストとレイテンシが削減される。
驚異の1000万トークン:Llama 4 Scoutの長文コンテキスト能力
Llama 4 Scoutは、業界をリードする1000万トークンという広大なコンテキストウィンドウをサポートする。これは、Llama 3の128Kトークンから飛躍的な進歩であり、複数文書の要約、広範なユーザーアクティビティの解析、巨大なコードベースに対する推論など、これまで困難だったタスクを可能にする。
この長文対応は、「mid-training」と呼ばれる段階での特殊なデータセットを用いた学習と、「iRoPE (interleaved Rotary Position Embedding)」と呼ばれる新しいアーキテクチャによって実現された。iRoPEは、位置埋め込みを使用しないインターリーブドアテンション層を特徴とし、推論時のアテンションスケーリング技術と組み合わせることで、優れた長さ汎化性能を発揮する。
効率と精度を両立するトレーニング手法
Metaは、Llama 4のトレーニングにおいて効率性と品質の両立を追求した。
- FP8精度: トレーニングにFP8(8ビット浮動小数点数)精度を用いることで、品質を損なうことなく計算効率を高め、GPUの演算性能を最大限に引き出すことに成功。Behemothのトレーニングでは、32,000基のGPUを用いて390 TFLOPs/GPUという高い計算効率を達成した。
- MetaP技術: 層ごとの学習率や初期化スケールといった重要なハイパーパラメータを確実に設定できる新しいトレーニング技術「MetaP」を開発。
- 大規模データセット: Llama 3の2倍以上となる30兆トークンを超える多様なテキスト、画像、動画データで事前学習を実施。
- 多言語対応: 200言語で事前学習を行い、そのうち100言語以上は10億トークン以上のデータを使用。これはLlama 3の10倍以上の多言語トークン量に相当する。
最適化されたポストトレーニングパイプライン
モデルの対話能力や特定タスクへの適応を高めるポストトレーニングも刷新された。Llama 4では、軽量な教師ありファインチューニング (SFT) → オンライン強化学習 (RL) → 軽量な直接選好最適化 (DPO) という新しいパイプラインを採用している。
特に、SFTやDPOがモデルの探索能力を過度に制限し、推論やコーディング能力を低下させる可能性があるという学びから、簡単なデータを除外し、より困難なデータセットでSFTを実施。続くオンラインRL段階では、困難なプロンプトを選択し、継続的にモデルを更新・フィルタリングする戦略により、性能を大幅に向上させた。さらに、Behemothを教師モデルとして用いる「共同蒸留 (Codistillation)」も導入され、高品質化に貢献している。
モデル別詳細:Scout, Maverick, Behemoth の性能と特徴
Llama 4ファミリーは、異なるニーズに対応する複数のモデルを提供する。
Llama 4 Maverick:コスト効率に優れた高性能チャットモデル
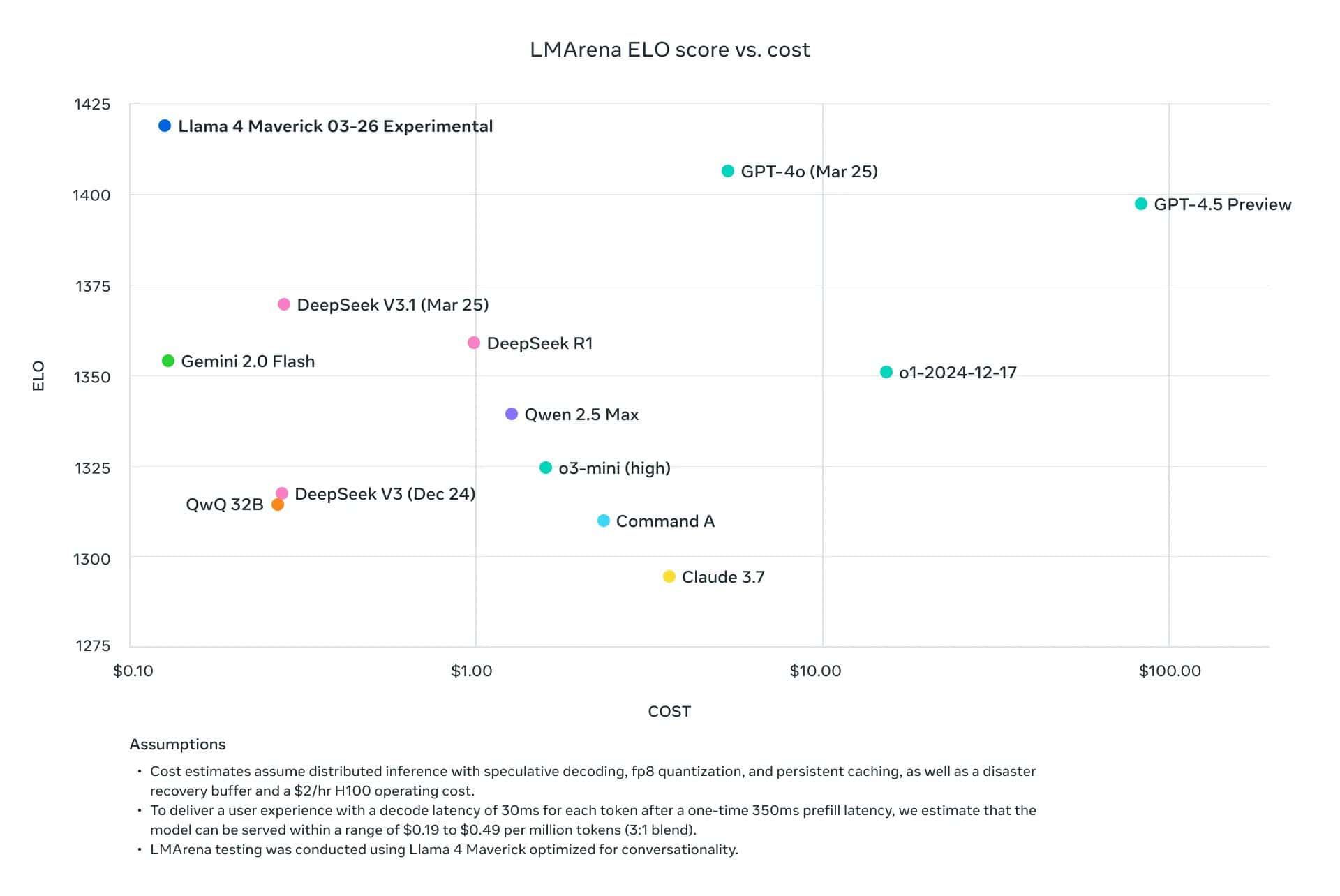
- 概要: 170億アクティブパラメータ、128エキスパート、4000億総パラメータ。
- 性能: 同クラスのマルチモーダルモデルとして最高レベル。GPT-4oやGemini 2.0 Flashをコーディング、推論、多言語、長文コンテキスト、画像ベンチマークで上回る。特に、コーディングと推論では、より大規模なDeepSeek v3.1に匹敵する性能を、半分以下のアクティブパラメータで達成。実験的なチャット版はLMArena ELOスコア1417を記録。
- 特徴: 高い性能とコスト効率のバランスに優れる。画像理解と創造的な文章生成能力が高い。NVIDIA H100 DGXホスト1台での運用、または分散推論による効率化が可能。推論コストは100万トークンあたり
0.19~0.49ドル (入出力3:1混合) と見積もられている。 - 用途: 一般的なAIアシスタント、チャットボット、画像を含むコンテンツ生成、多言語対応アプリケーションなど。
Llama 4 Maverick ベンチマーク比較
| カテゴリ | ベンチマーク | Llama 4 Maverick | Gemini 2.0 Flash | GPT-4o | DeepSeek v3.1 |
|---|---|---|---|---|---|
| 画像理解 | MMMU | 73.4 | 71.7 | 69.1 | – |
| MathVista | 73.7 | 73.1 | 63.8 | – | |
| ChartQA | 90.0 | 88.3 | 85.7 | – | |
| DocVQA | 94.4 | – | 92.8 | – | |
| コーディング | LiveCodeBench | 43.4 | 34.5 | 32.3 | 45.8/49.2 |
| 推論・知識 | MMLU Pro | 80.5 | 77.6 | – | 81.2 |
| GPQA Diamond | 69.8 | 60.1 | 53.6 | 68.4 | |
| 多言語 | Multilingual MMLU | 84.6 | – | 81.5 | – |
| コスト | 100万トークン当たり | $0.19-$0.49 | $0.17 | $4.38 | $0.48 |
Llama 4 Scout:クラス最高峰のマルチモーダル & 超長文対応モデル
- 概要: 170億アクティブパラメータ、16エキスパート、1090億総パラメータ。
- 性能: 同クラス(パラメータ数)のマルチモーダルモデルとして世界最高レベル。Gemma 3 (27B), Gemini 2.0 Flash-Lite, Mistral 3.1 (24B) を幅広いベンチマークで上回る。また、すべての旧世代Llamaモデルよりも強力。
- 特徴: 最大1000万トークンのコンテキストウィンドウ。画像内の特定領域とテキストを結びつける「画像グラウンディング」能力にも優れる。Int4量子化により、NVIDIA H100 GPU 1基で動作可能。
- 用途: 大規模文書の要約、長大なコードベースの解析、複数文書にまたがる情報検索など、長文コンテキストを必要とするタスク。
Llama 4 Scout ベンチマーク比較
| カテゴリ | ベンチマーク | Llama 4 Scout | Llama 3.3 70B | Gemma 3 | Mistral 3.1 | Gemini 2.0 Flash-Lite |
|---|---|---|---|---|---|---|
| 画像理解 | MMMU | 69.4 | – | 64.9 | 62.8 | 68.0 |
| MathVista | 70.7 | – | 67.6 | 68.9 | 57.6 | |
| コーディング | LiveCodeBench | 32.8 | 33.3 | 29.7 | – | 28.9 |
| 推論・知識 | MMLU Pro | 74.3 | 68.9 | 67.5 | 66.8 | 71.6 |
| GPQA Diamond | 57.2 | 50.5 | 42.4 | 46.0 | 51.5 | |
| 長文コンテキスト | コンテキストウィンドウ | 1000万トークン | 128K | 128K | 128K | 128K |
Llama 4 Behemoth:プレビュー公開、2兆パラメータの教師モデル
- 概要: 2880億アクティブパラメータ、16エキスパート、約2兆総パラメータ。
- 性能: 同クラスのモデルの中で高度な知能を示す。特に数学、多言語、画像ベンチマークにおいて、GPT-4.5, Claude Sonnet 3.7, Gemini 2.0 Proといった強力なモデルを上回る性能を示す(ただし、GoogleのGemini 2.5 Proなど、さらに新しいモデルとの比較は限定的)。
- 役割: Llama 4 ScoutおよびMaverickの品質向上に貢献する「教師モデル」として機能。Behemothからの共同蒸留により、生徒モデルの性能が大幅に向上した。
- 課題: 2兆パラメータという巨大モデルのポストトレーニングは困難を伴い、データの大幅な削減(SFTデータの95%)や、大規模RLパイプラインの刷新(非同期オンラインRLフレームワーク、リソース最適化)が必要となった。これにより、従来の世代と比較してトレーニング効率が約10倍向上した。
- 提供: 現在トレーニング中のため、一般公開はされていない。
Llama 4 Behemoth ベンチマーク比較 (一部)
| カテゴリ | ベンチマーク | Llama 4 Behemoth | Claude 3.7 | Gemini 2.0 Pro | GPT-4.5 |
|---|---|---|---|---|---|
| コーディング | LiveCodeBench | 49.4 | – | 36.0 | – |
| 数学・推論 | MATH-500 | 95.0 | 82.2 | 91.8 | – |
| MMLU Pro | 82.2 | – | 79.1 | – | |
| GPQA Diamond | 73.7 | 68.0 | 64.7 | 71.4 | |
| 多言語・画像 | Multilingual MMLU | 85.8 | 83.2 | – | 85.1 |
| MMMU | 76.1 | 71.8 | 72.7 | 74.4 |
安全性とバイアスへの取り組み
Metaは、Llama 4の開発において、有用性と安全性の両立を目指している。
- 多層的な安全対策: 事前学習段階でのデータフィルタリング、ポストトレーニング段階での安全に関するデータ統合、そして開発者がカスタマイズ可能なシステムレベルのセーフガード(Llama Guard, Prompt Guard, CyberSecEval)を提供している。
- レッドチーミング強化: 自動化と手動テストを組み合わせた体系的なテストを実施。特に「GOAT (Generative Offensive Agent Testing)」という新しい手法を導入し、複数ターンにわたる敵対的相互作用をシミュレートすることで、脆弱性の発見効率を高めている。
- バイアス低減への注力: LLMにおけるバイアス、特に政治的・社会的な話題に対する偏りは既知の問題である。MetaはLlama 4でこの問題に対処し、応答性を改善したと主張している。
- Llama 3.3と比較して、議論のある政治的・社会的話題に対する応答拒否率が大幅に減少(7% → 2%未満)。
- 特定の視点に対する応答拒否の偏りも減少(1%未満)。
- 強い政治的偏向を示す応答の割合は、Grokと同程度であり、Llama 3.3の半分になった。
Metaはこの進捗を評価しつつも、さらなる改善が必要であると認識している。一方でTechCrunchは、この調整が、AIチャットボットが「ウォーク(左翼的)すぎる」という一部(特に保守層)からの批判に対応する動きである可能性も示唆している。AIにおけるバイアス問題は技術的に非常に複雑であり、完全な除去は困難である点も指摘されている。
Llama 4の入手方法と今後の展望
公開されたLlama 4 ScoutとLlama 4 Maverickは、開発者や研究者がすぐに利用を開始できる。
- ダウンロード: 公式サイト llama.com および Hugging Face からモデルウェイトをダウンロード可能。今後、主要なクラウドプラットフォームやデータプラットフォーム、エッジデバイス向けシリコン、グローバルサービスインテグレーター経由でも提供される予定。
- Meta AIでの体験: WhatsApp, Messenger, Instagram Direct, Meta.AI WebサイトのMeta AIを通じて、Llama 4の能力を体験できる(マルチモーダル機能は米国内英語限定)。
Llama 4ファミリーの発表は、Metaが進めるオープンなAIエコシステム戦略の新たな一歩である。ネイティブマルチモーダル、MoE、超長文コンテキストといった技術的進歩は、より高度でパーソナライズされたAIアプリケーションの開発を加速させるだろう。Metaは今後もモデルと製品の研究開発を継続し、4月29日に開催されるLlamaConでさらなるビジョンを共有する予定である。開発者コミュニティがこれらの新しいモデルを活用し、どのような革新的な体験を生み出すのか、注目が集まる。
Sources


