
人工知能の急速な進化は、人類に多大な恩恵をもたらしている一方で、地球規模の深刻な課題を突きつけている。それは、天文学的な規模に膨れ上がる計算リソースとそれに伴う電力消費の激増だ。国際エネルギー機関(IEA)の推計によると、米国におけるAIおよびデータセンターの電力消費量は2024年時点で約415テラワット時(TWh)に達した。この数値は同国の年間総発電量の10%を超える異常な水準であり、さらに2030年までにこの消費量が倍増すると予測されている。現状の力技とも言えるAI開発アプローチが、物理的かつ環境的な限界に直面していることは疑いようのない事実となっている。
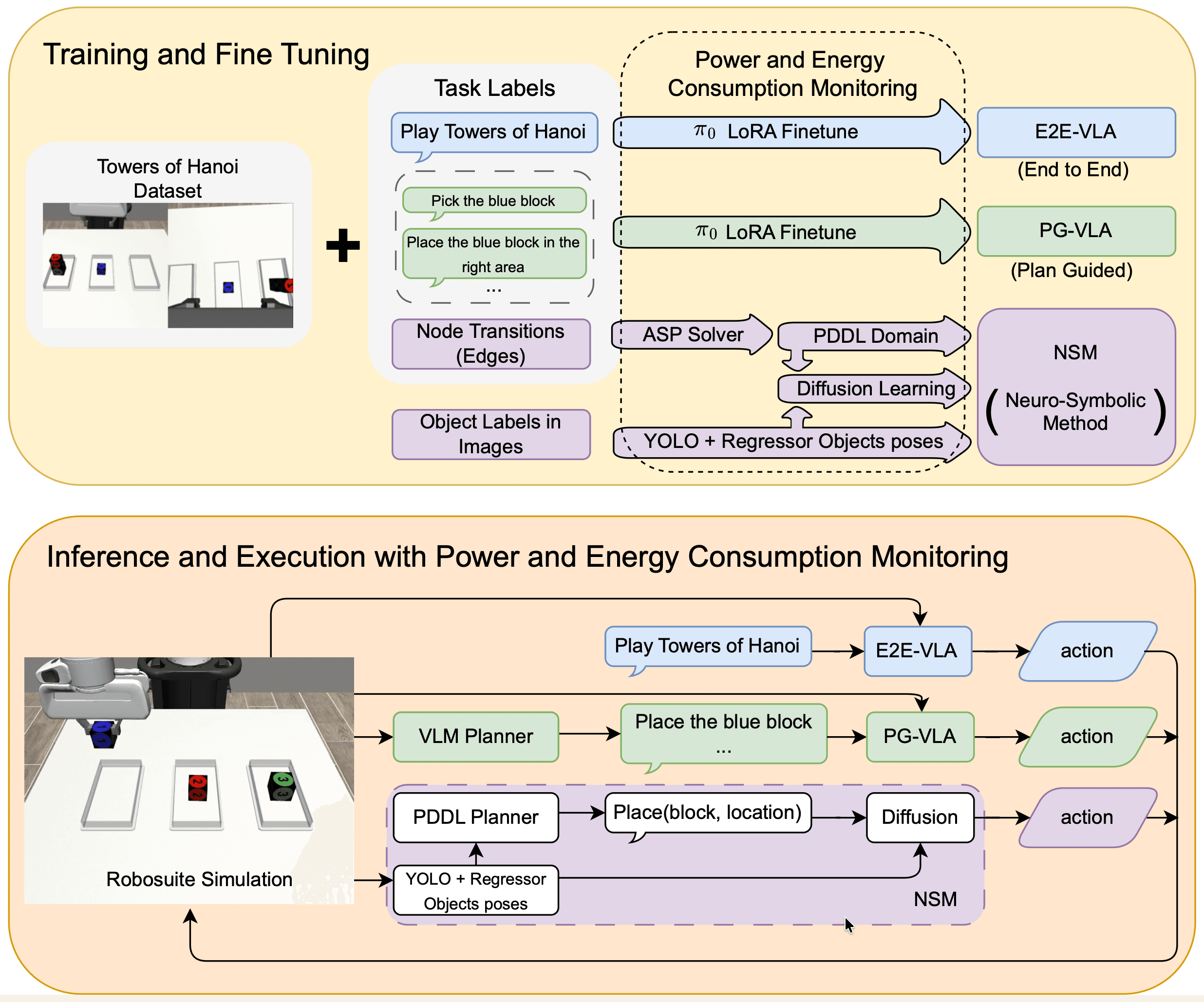
こうした持続不可能なエネルギー消費の軌道に歯止めをかけるべく、タフツ大学のMatthias Scheutz教授率いる研究チームは、オーストリア技術研究所(AIT)との共同研究を通じて、画期的な人工知能アーキテクチャの概念実証を発表した。「Neuro-symbolic AI(神経記号AI)」と呼ばれるこの新しいシステムは、最新のロボット制御タスクにおいて、従来のAIシステムと比較してエネルギー使用量を約100分の1にまで圧縮することに成功した。同時に、未知の複雑なタスクに対しても劇的に高い成功率を記録している。
本研究の成果は、2026年5月にウィーンで開催されるロボット工学分野の最高峰の国際会議「International Conference of Robotics and Automation (ICRA 2026)」で正式に発表される予定であり、それに先駆けてプレプリントサーバーのarXiv(論文番号: 2602.19260)にて詳細なデータが公開された。本稿では、この最先端技術がどのようにして既存の枠組みを打ち破り、次世代のロボット工学とAIの持続可能性にブレイクスルーをもたらすのか、その科学的メカニズムと実験結果の深淵を見ていきたい。
限界に直面する巨大AIとVLAモデルの構造的欠陥
今回の発見が持つ真の価値を理解するためには、現在ロボット工学の分野を席巻している開発トレンドと、それが抱える根本的な弱点を把握する必要がある。近年、ChatGPTやGeminiに代表される大規模言語モデル(LLM)の驚異的な成功を受け、ロボットの制御にも同様のアーキテクチャを適用する動きが加速している。その中心にあるのが「VLA(Vision-Language-Action:視覚・言語・行動)モデル」である。
VLAモデルは、カメラから得られる視覚情報とユーザーからの自然言語による指示を受け取り、ロボットアームや脚部を動かすための物理的な動作コマンドを直接出力するシステムである。現在主流となっているVLA(例えば本研究で比較対象となったOpenPiベースのモデルなど)は、入力から出力までの全過程を巨大な単一のニューラルネットワークで処理する「エンドツーエンド(End-to-End)」という手法を採用している。人間の専門家がロボットを操作した膨大な量のデモンストレーションデータを読み込ませ、入力された画像と言語に対して「統計的に最も妥当な次の動作」を出力するように、ネットワーク全体の結合荷重を微調整(ファインチューニング)していく。
一見すると万能に思えるこのアプローチには、重大な欠陥が潜んでいる。最大の課題は、AIが物理世界のルールを本質的に理解しているわけではなく、表面的なパターンの相関関係を暗記している状態に近いことだ。言語モデルが尤もらしい嘘を出力する現象(ハルシネーション)と同様の事態が、物理世界でも発生してしまう。Scheutz教授が指摘するように、VLAモデルは与えられた膨大な訓練データから次に起こるべき最も確率の高い行動を推論している。環境の光の加減が変わって影ができたり、物体の配置が訓練データとわずかに異なったりすると、モデルは途端に混乱し、ブロックを何もない空間に置こうとしたり、重心のバランスを無視して塔を崩落させたりといった致命的なエラーを引き起こす。
さらに深刻なのがエネルギー効率の問題である。エンドツーエンドの巨大なネットワークは、ロボットがわずかに指を動かすたびに、数十億個規模のパラメータの計算を全層にわたって実行しなければならない。学習フェーズにおいては膨大な計算電力を消費し、実環境への配備後(推論フェーズ)においても、常に高性能なGPU(画像処理半導体)をフル稼働させ続ける必要がある。このアーキテクチャの構造そのものが、電力を際限なく貪食する巨大なブラックボックスを生み出しているのである。
直感と論理のハイブリッド:Neuro-symbolic AIのアーキテクチャ
タフツ大学の研究チームがこのジレンマを解決するために構築したNeuro-symbolic AIは、人間の認知メカニズムをモデル化し、情報処理の階層を明確に分離するアプローチを採用している。これは、過去数十年にわたって対立してきたAIの二大潮流、すなわち「記号主義(Symbolic AI)」と「コネクショニズム(ニューラルネットワーク)」を高度な次元で融合させる試みである。
人間の思考プロセスを想像すると理解しやすい。私たちがコーヒーカップを持ち上げる際、どの筋肉をどう収縮させるかを論理的に計算している人はいない。それは無意識下における連続的で直感的な運動制御の領域である。対照的に、複雑な手順が求められるパズルを解いたり、料理の段取りを考えたりする際には、「まずAを行い、次にBの条件を満たす」といった明確なルールに基づく記号的な推論を行っている。
Neuro-symbolic AIは、この二重構造をAIシステム上に実装している。高次認知を担う部分には、自動計画の分野で標準的に用いられる「PDDL(Planning Domain Definition Language:プランニングドメイン定義言語)」ベースの記号的プランナーを導入した。このプランナーは、タスク全体を抽象的なカテゴリや段階(ステップ)に分解し、物理的制約やルールに違反しない確実な手順を論理的に生成する。
一方で、低次運動を担う部分には、最新の生成AI技術である「拡散モデル(Diffusion Models)」を用いたニューラルポリシーを採用している。記号的プランナーから「赤いブロックを青いブロックの上まで移動させる」という抽象的な指示を受け取ると、ニューラルポリシーがロボットのカメラ画像と関節の現在位置を処理し、ノイズを除去しながら滑らかで正確なアームの運動軌道を生成する。
この役割分担の明確化により、AIは状況の統計的な推測に頼り切る必要がなくなる。「パズルのルール」や「物体の重心」といった不変の論理構造を制約として適用しつつ、現実世界の不確実性(センサーのノイズや微妙な位置のズレ)に対してはニューラルネットワークの柔軟性で対応する。結果として、学習時の無駄な試行錯誤が極限まで削ぎ落とされ、圧倒的に速く、正確な動作の獲得が可能になるのである。
「ハノイの塔」が証明した圧倒的な学習効率とゼロショット汎化
研究チームは、このハイブリッドアーキテクチャの真価を厳密に測定するため、長期的な計画能力と正確な物理操作の両方が求められる古典的なタスク「ハノイの塔(Towers of Hanoi)」を用いた実験を行った。Robosuiteという物理シミュレーション環境内にFranka Pandaロボットアームを配置し、最先端のオープンウェイトVLAモデル($\pi_0$をベースとしたもの)とNeuro-symbolic AIの性能を直接対決させた。
タスクの基本ルールは、「大きなブロックを小さなブロックの上に置いてはならない」という順序制約を厳守しながら、積み上げられたブロックの塔を別のプラットフォームへ完全に移動させることである。実験の結果は、設計思想の違いがもたらす性能差を残酷なまでに浮き彫りにした。

3つのブロックを使用する標準的なハノイの塔タスクにおいて、最良のパフォーマンスを示したエンドツーエンドのVLAモデル(E2E-VLA)のタスク完了率は34.0%に留まった。VLAは把持の失敗や不正確なリリースといった低レベルの実行エラーを繰り返し、自力でリカバリーできずにエピソードの制限時間を迎えてしまった。これに対し、Neuro-symbolic AIモデルは95.0%という極めて高い成功率を叩き出し、複雑な手順と精密な操作を両立させてみせた。
両者の知能の構造的な違いがさらに明白になったのは、4つのブロックを使用する高難度タスクにおける結果である。この4ブロックの構成は、AIモデルに対する訓練データには一切含まれていない未知の状況であった。従来型のVLAモデルはこの環境に直面した際、成功率0%(全エピソードで完全失敗)という結果に終わった。VLAは過去のデータセットに存在した3ブロックの軌道を盲目的に再現しようとし、新しい状況に適応する手順を生成できなかった。対照的に、Neuro-symbolic AIモデルは、未経験の複雑なタスクであるにもかかわらず78.0%の成功率を記録した。抽象的な記号レベルでルールを理解しているため、ブロックの数が増えても即座に新しい解答手順を立案し、正確に実行できたのである。
特筆すべきは、モデルに与えられた「学習データ」の質と量の非対称性である。従来型のVLAモデルは、ハノイの塔を最初から最後まで解き切る完全なデモンストレーション映像を300エピソードも読み込んで学習させられた。それでもなお、ルールの本質を自ら見出すことはできなかった。一方で、Neuro-symbolic AIモデルに与えられたデータは、単に「一つのブロックを持ち上げて、別の場所に置く」という極めて単純な基本動作のデモンストレーションわずか50エピソードのみであった。Neuro-symbolic AIは、この断片的な情報の連なりから背後にある「記号的なルール(シンボリック・ドメイン)」を自律的に抽出し、自らの知識体系として再構築するという魔法のような情報圧縮を実現している。
消費エネルギーを1%に圧縮するメカニズムの深層
本研究がロボット工学の枠を超えて産業界全体に衝撃を与えている最大の理由は、計算リソースとエネルギー消費の劇的な削減効果にある。論文に記録されたハードウェアの緻密な計測データは、巨大なニューラルネットワークに過度に依存する現状のAI開発がいかに非効率な道を進んでいるかを明らかにしている。
モデルを特定の環境に適応させるためのファインチューニング(学習フェーズ)において、NVIDIA GeForce RTX 4090 GPUを用いて計測が行われた。従来型のVLAモデルの学習には、GPUをフル稼働させた状態で1日と15〜16時間以上(約40時間)という長大な時間を要した。対するNeuro-symbolic AIは、同じハードウェア環境下においてわずか34分で学習プロセスを完了している。
この学習時間の絶対的な差は、消費エネルギーの途方もない格差を生み出す。VLAモデルの学習にはトータルで68.5メガジュール(MJ)の物理的エネルギーが投入された。これに対し、Neuro-symbolic AIが消費したエネルギーはわずか0.85 MJである。Neuro-symbolic AIは従来手法の約1.2%(およそ100分の1以下)の電力消費で、より精度の高い、かつ汎用性のある知能を獲得したことになる。
さらに、実世界の運用において最も重要となるタスク実行時(推論フェーズ)の省電力性も際立っている。エンドツーエンドのVLAモデルは、毎秒数十回の頻度で巨大なネットワーク全体を順伝播させるため、実行中常にGPU電力を大口で消費し続ける(平均総消費電力115.2W)。これに対し、Neuro-symbolic AIは論理的なプランニングの大部分を計算負荷の軽いCPU側で処理し、ニューラルネットワークへの依存を局所的な運動制御のみに限定している。その結果、GPUによる重い推論を回避でき、平均総消費電力を19.4Wまで抑制することに成功した。
タスクごとの実行エネルギーを比較すると、3ブロックのハノイの塔を1回完了するのに、VLAモデルが7.96キロジュール(kJ)を消費したのに対し、Neuro-symbolic AIは0.83 kJしか消費しなかった。実運用においてエネルギー効率を圧倒的に高められる構造が実証されたことは、バッテリー駆動を前提とする自律型ロボットやドローンの設計において、決定的なブレイクスルーとなる。
力技からの脱却が拓く持続可能なロボット工学の未来
タフツ大学とAITの共同研究チームが示したこの実証データは、現在シリコンバレーを中心に蔓延している「パラメータ数と計算リソースを倍増させ続ければ、AIは自律的に汎用的な知能を獲得する」という、スケーリング則に対する過信への強力な反証である。
Scheutz教授は、現在の巨大AIモデルの無駄を日常的なサービスになぞらえて警告を発している。Google検索を利用する際、ページ上部に表示されるAIサマリー(AI Overview)を一つ生成するプロセスは、従来のWebサイトのインデックス検索に比べて最大100倍ものエネルギーを浪費することがある。入力される計算資源と電力の規模が、達成すべきタスクの難易度や生み出される価値に対して完全に不釣り合いな状態に陥っているのである。
工場での精密な組み立て作業、物流倉庫での多品種ピッキング、あるいは厳密な手順が求められる医療現場の支援など、明示的な手順や厳格な物理的制約が伴うロボットの操作(Structured Long-Horizon Manipulation)においては、ニューラルネットワークの直感的なパターン認識能力に全てを委ねるアプローチは脆く、非効率である。過去のAI研究が蓄積してきた記号的で論理的な推論能力を再評価し、それらを最新のディープラーニングと構造的に統合することにこそ、真の知能の飛躍が隠されている。
AIモデルが社会インフラのあらゆる場所に組み込まれ、データセンターの群れが一国の総電力を脅かす時代において、より賢いシステムを構築するための道筋は、必ずしもネットワークの規模を盲目的に巨大化させることではない。Neuro-symbolic AIが指し示すように、知能のアーキテクチャそのものを根本から見直し、目的に応じた適切な推論メカニズムを設計することこそが、人類が環境的制約の中でAI技術を持続的に発展させていくための唯一の現実的な道筋となるだろう。
論文
参考文献