OpenAIの最新AIモデル「o3」と「o4-mini」が、AIの推論能力を測るベンチマーク「ARC-AGI」でテストされた。ARC Prize Foundationによる評価結果は、o3が一定の性能を示す一方で、以前テストされたプレビュー版には及ばず、o4-miniは高いコスト効率を示すなど、最新AIの能力と課題を浮き彫りにしている。特に、より複雑な推論タスクでは依然として大きな課題が残る。
最新テスト結果:o3は健闘、o4-miniは高効率
AI評価に特化する非営利団体ARC Prize Foundationは、人間には容易だがAIには難しい推論能力(記号的推論、多段階の構成、文脈依存のルール適用など)を測定するため、ARC-AGIベンチマークを用いている。今回のテストでは、OpenAIのo3とo4-miniが、ARC-AGI-1およびARC-AGI-2のタスクにおいて、3つの推論レベル(低・中・高)で評価された。「低」は速度とトークン使用量の最小化を、「高」はより網羅的な問題解決を意図した設定である。
ARC Prize Foundationによると、主要な結果は以下の通りだ。
- ARC-AGI-1(比較的易しいベンチマーク)での性能:
- o3:「低」設定で41%、「中」設定で53%の正答率を達成。
- o4-mini:「低」設定で21%、「中」設定で41%の正答率を達成。
- ARC-AGI-2(より困難なベンチマーク)での性能:
- 両モデルとも、「低」「中」設定で正答率は3%未満と、著しく低い結果となった。
この結果から、o3(中設定)は現在公開されているモデルの中で最高の性能を示していることがわかる。特に、従来の思考の連鎖(Chain-of-Thought: CoT)アプローチのモデルが約30%の性能上限に留まっていたのに対し、o3(中設定)はその約2倍の性能を達成しており、単純なスケーリングや従来のCoT手法だけでは説明が難しい進歩が見られる。しかし、より高度な推論を要求するARC-AGI-2に対しては、依然として有効な解決策を見いだせていない現状も明らかになった。
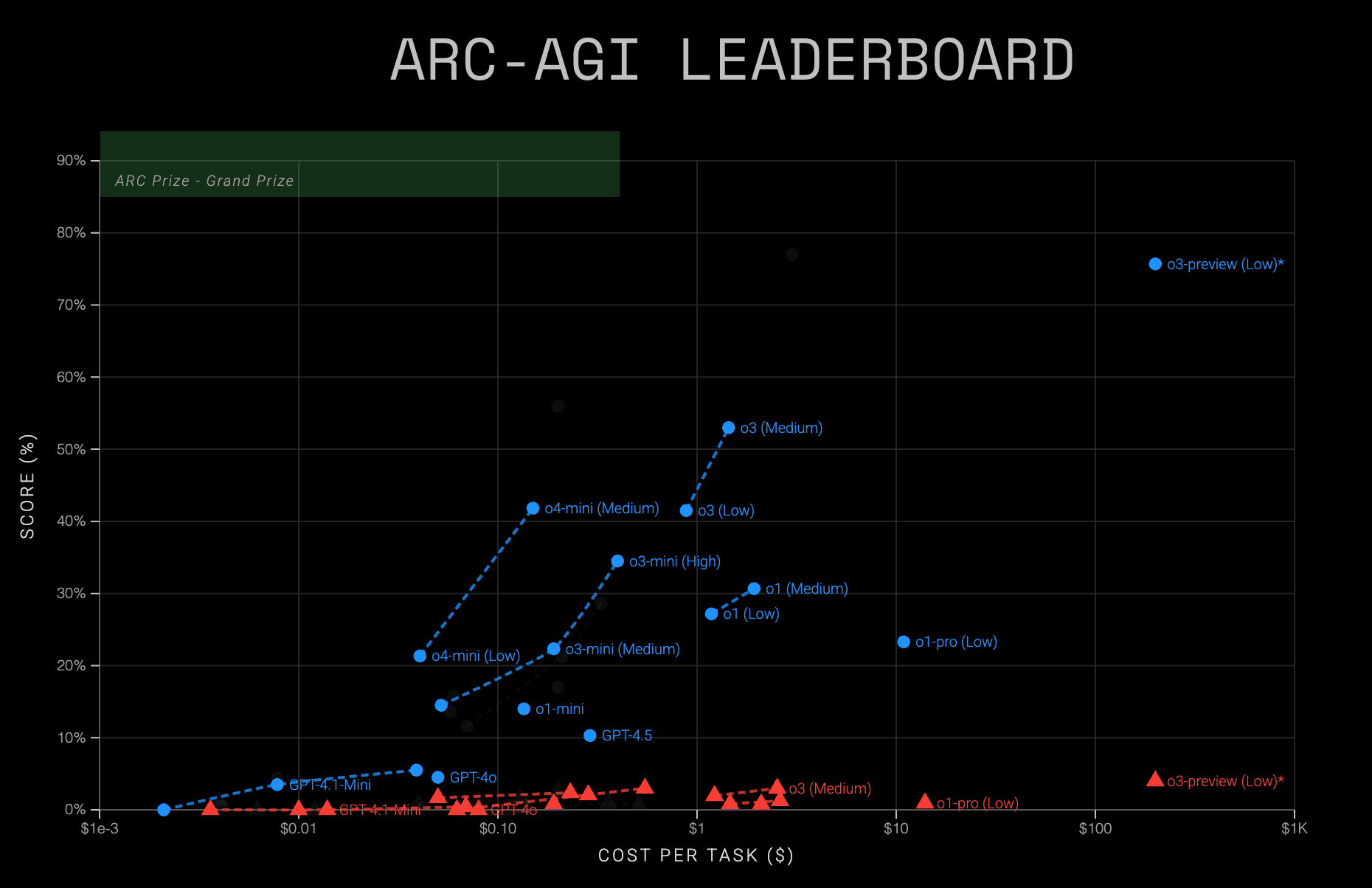
特筆すべきはo4-miniのコスト効率である。ARC-AGI-1において、o4-mini(低設定)はタスクあたり約0.05ドルで21%の正答率を達成した。これは、旧モデルであるo1-proが同等の性能を出すのにタスクあたり約11ドルを要したことと比較すると、驚異的な効率改善と言える。ARC Prize Foundationは、モデル性能が向上するにつれて、効率性(速度、コスト、トークン使用量)が主要な差別化要因になると指摘している。
| モデル | 推論設定 | ARC-AGI-1 正答率 | ARC-AGI-2 正答率 | タスクあたりコスト (V2) |
|---|---|---|---|---|
| o3 | 低 | 41% | 1.9% | 1.22 USドル |
| o3 | 中 | 53% | 2.9% | 2.52 USドル |
| o3 | 高 | N/A | N/A | – |
| o4-mini | 低 | 21% | 1.6% | 0.05 USドル |
| o4-mini | 中 | 42% | 2.3% | 0.23 USドル |
| o4-mini | 高 | N/A | N/A | – |
期待されたo3プレビュー版とのギャップ
今回のo3のテスト結果で注目すべき点は、2024年12月にテストされた「o3-preview」版と比較して、性能が大幅に低下していることである。当時、o3-previewはARC-AGI-1において、「低」設定で76%、「高」設定で88%という高い正答率を記録していた。しかし、今回リリースされた公開版o3は、「低」設定で41%、「中」設定で53%に留まった。
OpenAIはARC Prize Foundationに対し、この性能差について以下の点を説明している。
- モデルの違い: 公開版o3は、プレビュー版とは異なるモデルアーキテクチャを採用しており、全体的により小さいモデルである。
- マルチモーダル: プレビュー版はテキスト専用だったが、公開版o3は画像入力も扱えるマルチモーダル対応となっている。
- 計算リソース: プレビュー版で利用可能だったテスト時の計算リソースレベルは、公開版o3では利用できず、同等の結果は期待できない。
- 訓練データ: OpenAIによると、o3-previewの訓練にはARC-AGI-1データセットの75%が含まれていた。一方、公開版o3はARC-AGIデータで直接訓練されてはいないものの、ベンチマークが公開されているため、間接的にデータに触れた可能性は否定できない。
- 製品最適化: 公開版o3はチャットや製品利用向けにファインチューニングされており、これがARC-AGIベンチマークにおける性能にプレビュー版とは異なる長所と短所をもたらしている。
これらの違いは、特に未公開のAIモデルに関するベンチマーク結果を解釈する際には、慎重な姿勢が必要であることを示唆している。プレビュー版の驚異的なスコアは、特定の条件下での可能性を示したものの、実際の製品版の性能とは乖離があった。
「高推論」設定の課題と効率性のトレードオフ
今回のテストでは、「高」推論設定において、o3とo4-miniの両モデルが多くのタスクを完了できない、あるいはタイムアウトするという問題が発生した。そのため、「高」設定での信頼できる公式スコアは得られていない。
ARC Prize Foundationは透明性のため、限定的ながら得られた「高」設定での部分的な結果を公開している。
- o3-high(部分的結果):
- ARC-AGI-1: 100タスク中37タスクに応答、正答率82%
- ARC-AGI-2: 120タスク中15タスクに応答、正答率6%
- o4-mini-high(部分的結果):
- ARC-AGI-1: 100タスク中29タスクに応答、正答率89%
- ARC-AGI-2: 120タスク中11タスクに応答、正答率18%
ただし、これらの数値は注意深く解釈する必要がある。応答があったタスクは、モデルが比較的容易に解決できたタスクに偏っている可能性が高い。応答できなかったタスクには、より困難な問題が含まれていると考えられるため、これらの部分的な結果はモデルの真の能力を過大評価している可能性がある。ARC Prize Foundationは、これらのスコアは代表的なものではなく、リーダーボードには掲載しないとしている。
「高」設定の分析からは、いくつかの重要な観察結果が得られた。
- 早期応答タスクの高精度: モデルがより早く応答を返したタスクほど、正答率が高い傾向が見られた。これは、モデルが簡単なタスクについては、思考プロセスの早い段階で結論に達することを示唆している。
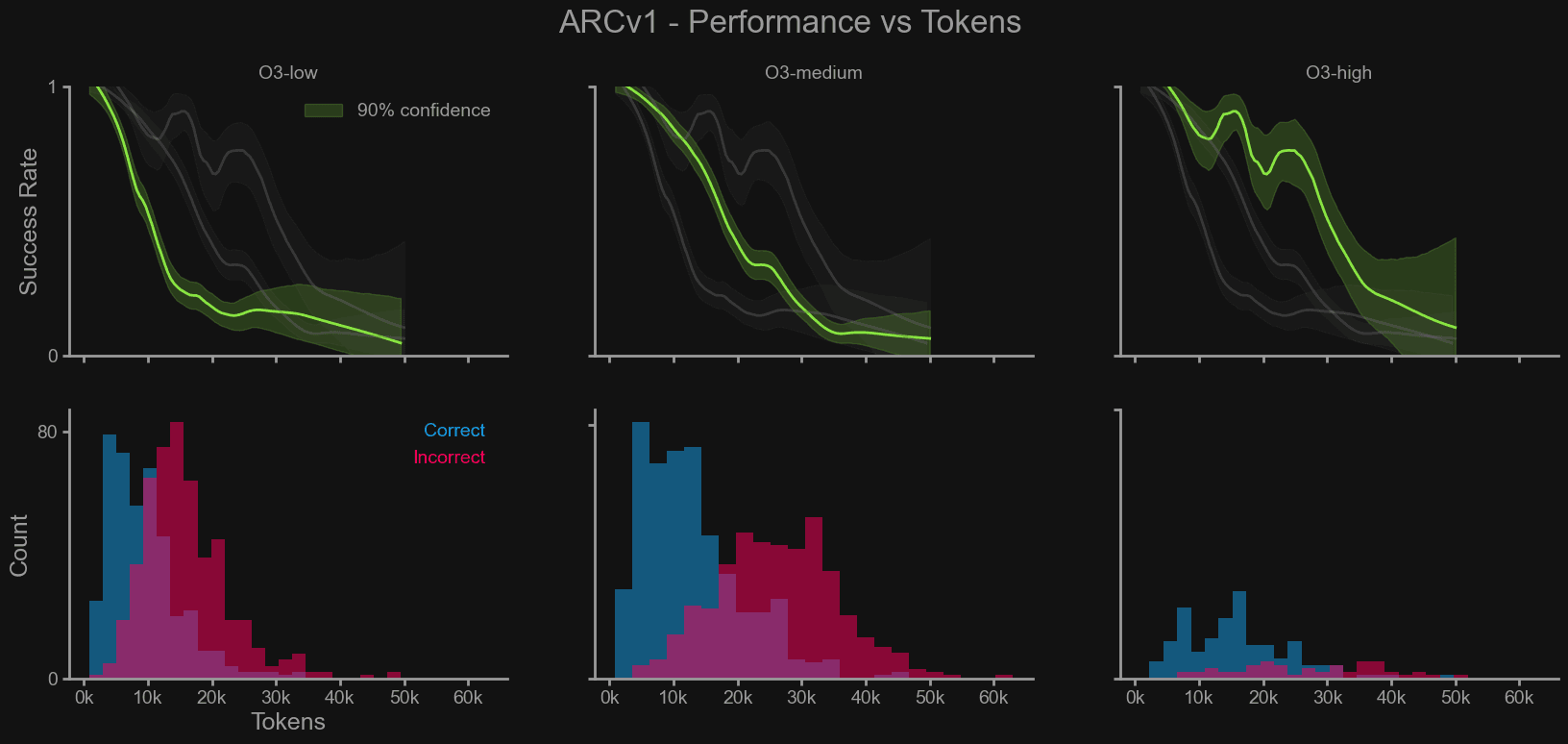
- 高推論設定の非効率性: 同じタスクを比較した場合、「高」設定は「中」設定よりも一貫して多くのトークン(計算量の単位)を消費して同じ答えに到達した。これは、簡単なタスクにおいては、「高」設定が精度向上に寄与せず、コストだけが増加することを示している。ARC Prize Foundationの共同設立者であるMike Knoop氏は、「精度を気にするのであれば、低設定を使う説得力のある理由はない」としつつも、コストを重視する場合は「中」設定がデフォルトとして優れている可能性があると示唆している。最高の精度が不可欠でコストが問題にならない場合にのみ、「高」設定が推奨される。
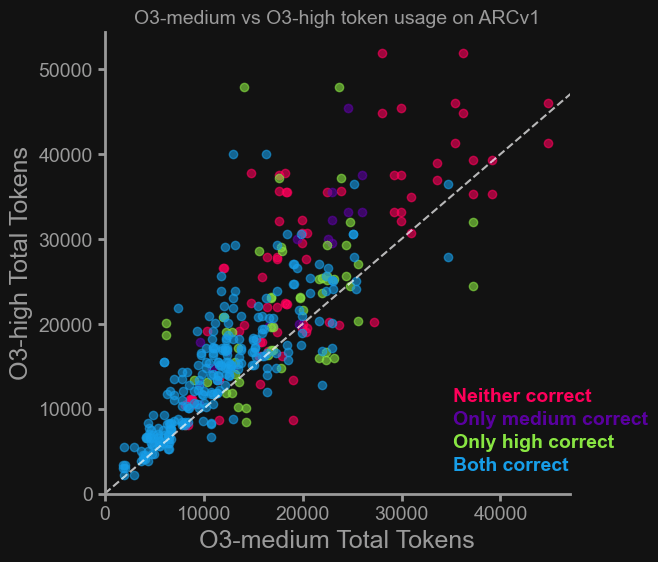
- トークン/秒の差: o3-mini-lowとo4-mini-lowは、それぞれのmediumやhigh設定よりも高いトークン/秒(処理速度)を示した。これは、miniモデルにはアルゴリズム的な違いがある可能性を示唆しているが、具体的な原因は不明である。
AI推論能力の現状と今後の展望
今回のARC Prize Foundationによる評価は、AIの推論能力における現在の到達点と、依然として残る大きな課題を明確に示している。
o3(中設定)は、公開されているモデルの中ではARC-AGI-1において最高の性能を示し、従来のCoTアプローチから顕著な進歩を遂げた。 これは、より洗練された処理モデルや高度なサンプリング・最適化技術が用いられている可能性を示唆するが、具体的なアーキテクチャに関する情報がないため、推測の域を出ない。
しかし、その進歩をもってしても、新たに導入されたより困難なARC-AGI-2ベンチマークに対しては、ほとんど歯が立たない状況である。 人間は特別な訓練なしでもARC-AGI-2タスクの平均60%を解決できるのに対し、OpenAIの最も強力な推論モデルでさえ、現在の正答率は約3%に過ぎない。
Mike Knoop氏が「o3の優れた推論効率をもってしても、ARC v2にはまだ長い道のりがある。新しいアイデアが依然として必要だ」と述べているように、人間とAIの間の問題解決能力には、依然として深い溝が存在する。
また、最近の別の分析では、o3のような「推論モデル」と呼ばれるものが、基盤となる大規模言語モデル(LLM)を超える新たな能力を持っているわけではない可能性も示唆されている。 これらのモデルは、特定のタスク、特に強化学習を通じて訓練されたタスクにおいて、より迅速に正解に到達するように最適化されているに過ぎないかもしれない、という見方である。
Microsoft CEOのSatya Nadella氏が「無意味なベンチマークハック」と表現したような状況とは別に、ARC-AGIのような本質的な推論能力を問うベンチマークにおける進捗は、真の汎用人工知能(AGI)への道のりがまだ遠いことを示している。 今後のAI開発においては、純粋な性能向上だけでなく、コスト効率や、より複雑で抽象的な推論への対応能力が、ますます重要な焦点となるだろう。
Sources
- ARC Prize Foundation: Analyzing o3 and o4-mini with ARC-AGI