
大規模言語モデル(LLM)を中核に据えたAIエージェントのコーディング能力は、ここ数年で飛躍的な進化を遂げている。与えられた要件定義に基づいて関数を生成したり、既知のバグを特定してパッチを当てたりするタスクにおいて、AIは驚異的な速度と精度を叩き出すようになった。この進歩を牽引してきたのは、「HumanEval」や「SWE-bench」といった評価指標である。これらのベンチマークは、AIが生成したコードがテストを通過するかどうかを厳密に測定し、AI開発競争の羅針盤となってきた。
しかし、現場の最前線で働くソフトウェアエンジニアたちは、AIが生成するコードに対してある種の違和感を抱き続けている。どれほどベンチマークのスコアが高くとも、実稼働しているプロダクトにAIのコードを組み込むと、時間が経つにつれてプロジェクト全体が身動きの取れない状態に陥ることがあるからだ。この事象の根本的な原因は、既存の評価指標が「一発勝負のテスト通過」に極端に最適化されており、ソフトウェアの長期的な保守という現実世界の要件を完全に無視している点にある。
この深刻なギャップを埋めるため、Alibaba Cloudと中山大学の研究チームは新たな評価フレームワーク「SWE-CI(SoftWare Engineering – Continuous Integration)」を開発し、論文として公開した。これは、静的な機能の正確性から、長期的なコードの保守性へと評価のパラダイムを根本的に転換させる試みだ。本稿では、SWE-CIが暴き出したAIモデルの限界と、各開発プロバイダーの思想の違い、そしてソフトウェアエンジニアリングの未来について見ていきたい。
スナップショット評価の死角と技術的負債の隠蔽
ソフトウェア開発において、要件が一度のリリースで完璧に定まることはあり得ない。ユーザーからのフィードバック、市場環境の変化、あるいは技術基盤の刷新に伴い、コードベースは継続的な変更を要求される。既存のベンチマークが採用している「スナップショット型」の評価手法は、特定の時点における単一の要件と、それに対する修正結果だけを切り取って判定を下している。
この評価手法の最大の死角は、場当たり的な強引な修正と、将来の拡張を見据えたクリーンなモジュール設計の区別がつかないことにある。どちらのアプローチで修正されたコードであっても、用意されたユニットテストを通過しさえすれば「正解」として扱われる。その結果、AIエージェントはテストをすり抜けるための最短経路を選択するようになり、再利用不可能なスパゲッティコードを量産していく。
この時点では問題は表面化しない。しかし、システムに新しい機能を追加しようとした瞬間に、過去の設計の脆さが「技術的負債」として重くのしかかることになる。インターフェースが変更できず、一部の改修が予期せぬモジュールの崩壊を引き起こす。真のコーディング能力とは、単に今日のテストを通過するコードを書くことではなく、明日の変更を許容するアーキテクチャを維持することである。
進化のプロセスを再現するデータ抽出と環境構築
研究チームが構築したSWE-CIは、連続的なコード進化のプロセスをエミュレートするために設計された初のリポジトリレベル・ベンチマークである。彼らは単純に既存のデータセットを流用するのではなく、GitHub上の膨大な履歴から、過酷な実世界の開発シナリオを抽出する複雑なパイプラインを構築した。
初期段階として、3年以上にわたって活発に保守されており、500以上のスターを獲得しているMITまたはApache-2.0ライセンスのPythonリポジトリ4,923件を収集した。そこからメインブランチのコミット履歴を解析し、パッケージの依存関係が変化しない期間のサブシーケンスを特定している。これは、外部ライブラリのアップデートによる環境要因のノイズを排除し、純粋な論理的変更の履歴を抽出するための精緻な工夫である。
さらに、抽出されたコードベースを動作させるためのDocker環境を自動生成し、依存関係の欠落による起動エラーを動的に検知して自己修復するメカニズムまで組み込んでいる。こうした厳格なフィルタリングと環境構築を経て、最終的に100のタスクが厳選された。これら100のタスクは、平均して233日間にわたる開発期間と、71回の連続したコミット履歴を含んでいる。変更されたソースコードは平均500行を超えており、単純なバグ修正とは次元の異なる、重厚な機能反復の歴史そのものである。
デュアルエージェントが回す継続的インテグレーション
長期間にわたるコードの進化をAIに体験させるため、SWE-CIは「アーキテクト」と「プログラマー」という2つの役割を持たせたエージェントによる協調プロトコルを採用している。これは、熟練のシニアエンジニアと実装担当者がペアを組む現実の開発現場のワークフローを忠実に模倣したものである。
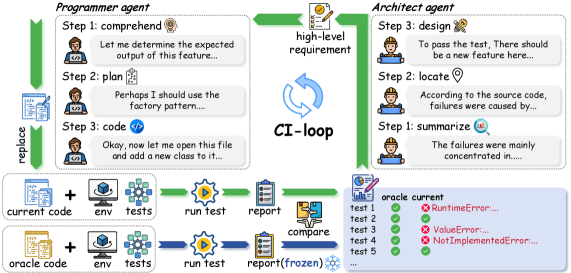
評価プロセスは、ベースとなる古いコードベースからスタートする。まずアーキテクトエージェントが、目標となる状態(オラクルコード)とのテスト結果のギャップを分析する。アーキテクトは失敗したテストの原因を要約し、ソースコード上の欠陥を特定した上で、高次な要件定義書をXMLフォーマットで出力する。この際、一度に過剰な設計を行うことを防ぐため、アーキテクトは最も緊急度の高い5つ以内の要件に絞り込んで指示を出すよう制約が設けられている。
次に、プログラマーエージェントが要件定義書を読み込み、具体的なコードの修正計画を立てて実装を行う。重要なのは、プログラマーにはテストを直接実行して結果を確認する権限が与えられていないことである。彼らは純粋にアーキテクトからの行動契約に基づいてコードを編集しなければならない。修正が完了すると、外部の評価システムによってテストが実行され、残存する課題に対して再びアーキテクトが分析を行う。この継続的インテグレーション(CI)のループを数十回にわたって繰り返すことで、目標状態への到達を目指していく。
評価指標の革新が暴くプロバイダーの設計思想
一連のループを通じてエージェントの保守能力を数値化するため、研究チームは「正規化された変化」と「EvoScore(Evolution Score)」という新しい指標を導入した。これはテストの通過率をベースラインからの改善度としてマイナス1からプラス1の範囲で測定するものである。
EvoScoreの根幹をなすのは、連続するイテレーションの後半に発生する結果に対して、より高い重み付け(ガンマ値の設定)を行うという計算ロジックである。初期の段階で無理な修正を行い技術的負債を抱え込んだエージェントは、後のイテレーションで変更が困難になり、テストの通過率が劇的に低下する。この指標は、短期的な成功を犠牲にしてでも、拡張性の高いクリーンな設計を選択したモデルを高く評価するように作られている。
このガンマ値を変動させることで、各AIプロバイダーが自社のモデルに対してどのような強化学習の報酬設計を行っているかが浮き彫りになる。論文の分析によれば、DeepSeek、MiniMax、そしてOpenAIのGPTシリーズは、長期的な利益を優先する挙動を示した。一方で、GLMやKimiといったモデルは、目先のテストを通過させるための短期的なリターンを追求する傾向が強いことが確認されている。これは、各社がAIエンジニアに求める「正しさ」の定義が根本的に異なっていることを示唆している極めて興味深いデータである。
18モデルの過酷なテストが示すリグレッションの悪夢
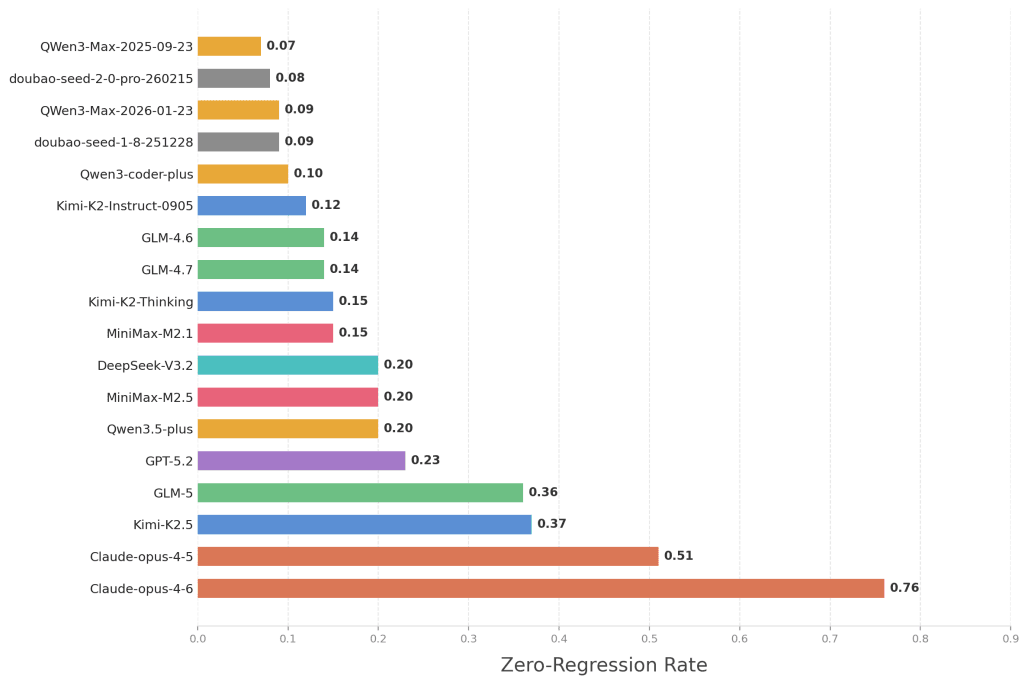
合計100億トークン以上を消費した大規模な実験の結果は、現在のLLMが抱えるソフトウェア保守の限界を冷酷なまでに提示している。テストされた18の最先端モデルのうち、実に75パーセントのモデルが、保守作業の過程で「以前は正常に機能していたコードを破壊してしまう」という致命的なエラーを引き起こした。
この現象はリグレッション(退行)と呼ばれ、品質保証の観点からは最も忌み嫌われる問題である。100のタスクを遂行する中で、リグレッションを一度も起こさなかった割合(ゼロリグレッション率)を測定したところ、GPT-5.2やDeepSeek-V3.2を含めた大半のモデルが0.25を下回る結果となった。つまり、大半のAIエージェントは、新しい機能を追加するたびにどこか別の場所を壊し、その修復に延々と時間を奪われているのである。
この惨状の中で唯一、AnthropicのClaude Opusシリーズだけが別格の安定感を示した。Claude Opus 4.6は0.76、Opus 4.5は0.51という圧倒的なゼロリグレッション率を記録し、長期にわたるコード変更においてもシステム全体の整合性を維持し続ける能力を証明した。現在のところ、人間の介入なしに自律的かつ安全に長期間のコード保守を任せられる水準に達しているのは、この限られたモデル群のみであるという事実が確認された。
開発現場のパラドックスとAIの破壊的価値
SWE-CIが数値化したこれらの限界は、現場のエンジニアたちが日々直面している問題と完全に符合している。開発者向けコミュニティであるHacker Newsにおける議論を分析すると、AIがコードベースにもたらす特有の「静かなる破壊」に対する懸念が多数寄せられている。
ある開発者は、AIが記述したコードが文法チェック(Lint)もテストも完璧に通過し、論理的にも間違っていないにもかかわらず、パラメータの名前を変更したり不要な中間処理を追加したりする癖を指摘している。こうした表面上は無害に見える変更が、数日後にまったく関係のないモジュールの依存関係を崩壊させる。過度に複雑化したコードの異常に気づくためには、結局のところ人間のシニアエンジニアが多大な時間をかけてレビューを行う必要があり、AIによる開発速度の向上がレビューのボトルネックによって相殺されてしまう。
その一方で、AIがもたらす複雑性の増大を、劇的に低下した「複雑性の解体コスト」が上回っているという鋭い指摘も存在する。あるモジュールが度重なるAIの修正によって管理不能なスパゲッティ状態に陥ったとしても、現在のClaudeのような高性能モデルを活用すれば、そのモジュールの挙動を完全に再現するテストスクリプトを記述させることができる。そして、そのテストを担保にした上で、古いコードを根こそぎ破棄し、最初からクリーンな状態に書き直させる作業が、かつての人力作業のわずかな時間で完了してしまうのである。
ソフトウェアが生きる場所と未来のエンジニアリング
AIエージェントは確かに驚異的な速度でコードを書き出す。しかし、技術者であるNicholas MatsakisがSNS上で言及しているように、ほとんどのモデルはコードを書くことはできても、それを維持することはできない。そして、本番環境のソフトウェアというものは、まさにその「機能すること」と「維持できること」の深いギャップの中に存在している。
SWE-CIの登場は、AIによるソフトウェア開発の評価軸を、単なるコードの断片の生成から、長期的なアーキテクチャの育成へと引き上げる歴史的な転換点となる。AIモデルの開発企業は今後、一発勝負のパッチ作成能力ではなく、過去の文脈を理解し、未来の変更を見据えた上で慎重にシステムに手を加える「思慮深いエージェント」の育成を迫られることになる。
ソフトウェアエンジニアリングの未来において、人間の役割はコードをタイピングすることから、AIが引き起こす構造的な歪みを監視し、適切なタイミングで解体と再構築を指揮するシステムアーキテクトへと完全に移行していく。技術的負債という概念そのものが消滅するわけではないが、その負債との向き合い方は、AIの台頭によって劇的に変化し始めている。
論文


