
人工知能(AI)技術の急速な発展と普及に伴い、それを支えるデータセンターの莫大な電力消費と、巨大なサーバー群を冷却するための環境負荷が世界的な課題として浮上している。こうした中、オーストラリアのシドニー大学のSydney Nano Hubの研究チームが、この物理的な限界を突破し得る画期的なプロトタイプを発表した。従来の電気信号(電子)の代わりに光子(フォトン)を用いて計算を行う「ナノフォトニックニューラルネットワーク(PNN)アクセラレータ」である。
科学誌『Nature Communications』にて2026年3月4日に公開された本研究は、人間の髪の毛ほどの極小サイズでありながら、ピコ秒(1兆分の1秒)という光の速度で演算を完了させることに成功している。さらに、医療画像の分類タスクにおいて90〜99%という極めて高い精度を達成し、光を用いたコンピューティングが実用段階へと大きく前進したことを証明しているのだ。
限界を迎える従来型半導体と「光コンピューティング」の夜明け
現代のコンピュータやAIを駆動しているプロセッサは、微細な銅線などの回路上を電子が移動することによって情報処理を行っている。しかし、この仕組みには逃れられない物理的な制約が存在する。電子が物質の中を移動する際、電気抵抗によって不可避的に「ジュール熱」と呼ばれる熱が発生してしまうのだ。AIの能力を向上させるためにニューラルネットワークの規模を拡大し、トランジスタの集積度を高めるほど、発熱量は二次関数的に増大する。現在のデータセンターは、この莫大な熱を逃がすために大量の電力と冷却水を消費しており、持続可能性の観点から大きな壁に直面している。
この根本的な課題を解決するアプローチとして注目を集めているのが、情報処理の媒体を電子から光子(フォトン)へと置き換える「光コンピューティング(オプティカル・コンピューティング)」である。光は、透明な媒質の中を進む限り電気的な抵抗を受けず、したがって計算過程で熱をほとんど発生させない。さらに、宇宙で最も速い「光の速度」で空間を伝播するため、理論上は電子回路を遥かに凌駕する超高速な情報処理が可能となる。
しかし、光を用いて複雑なAIの演算、すなわち膨大なネットワークの重み付けや非線形な計算をどのように実行するかについては、長年にわたり多くの課題が残されていた。シドニー大学のXiaoke Yi教授やJoel Sved氏をはじめとする研究チームは、光の波としての性質を極限まで精密にコントロールする独自のナノ構造を設計することで、この難題に一つの明確な解答を提示したのである。
光の振る舞いが「計算」になる:ナノフォトニック・アクセラレータの仕組み
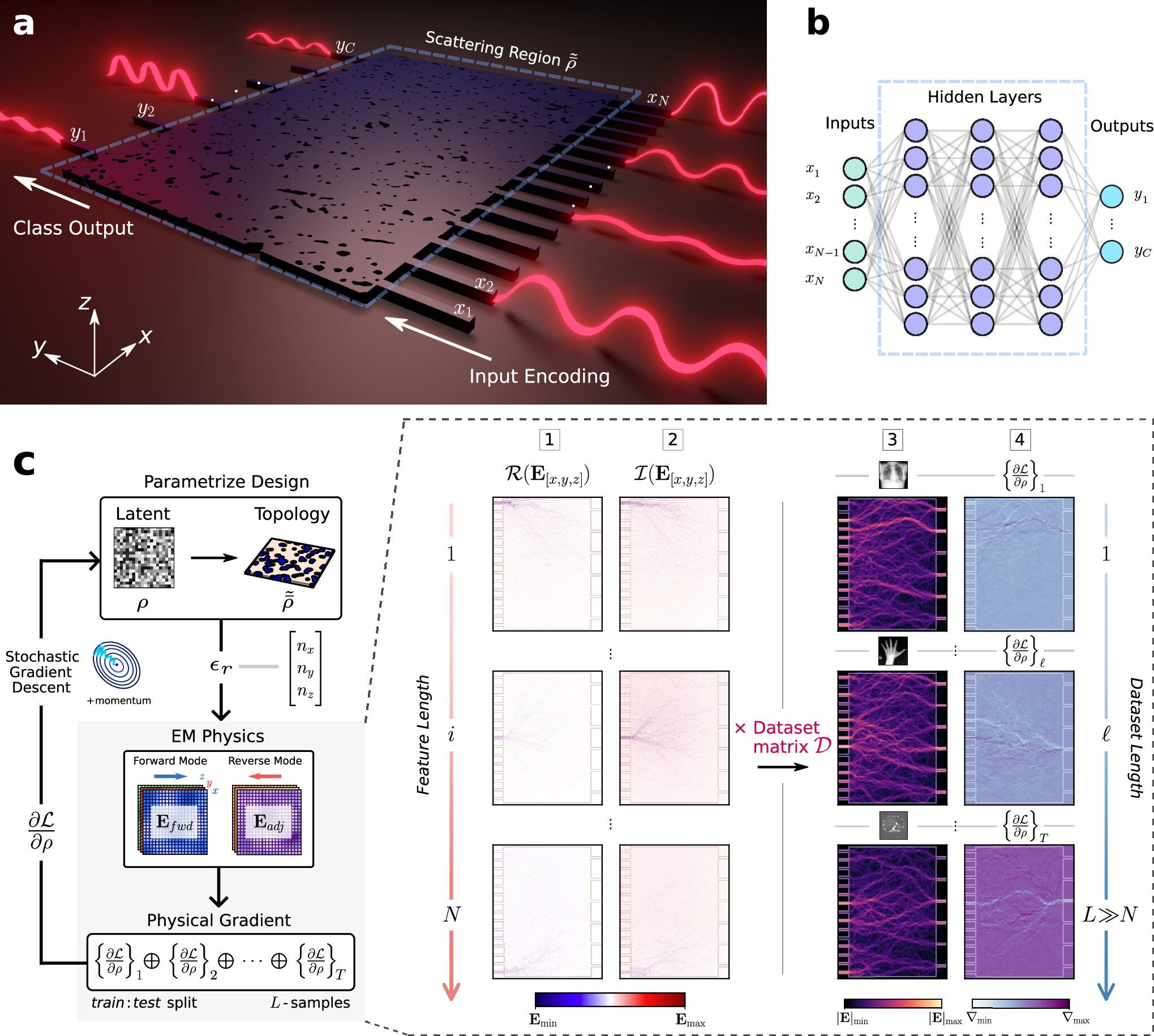
今回開発されたナノフォトニック・アクセラレータは、複雑な電子回路を並べるのではなく、光が通過する「迷路」のようなナノスケールの構造体そのものが計算機として機能する。これを理解するためには、光の「干渉」と「散乱」という物理現象を思い浮かべる必要がある。池に二つの石を投げ入れたとき、広がる波紋が重なり合って特定の場所の波が高くなったり、打ち消し合って消えたりする現象が干渉である。
このチップに入力されるデータ(例えば、手書きの数字や医療画像)は、まず1550ナノメートル(nm)の赤外線レーザーの光の「振幅(強さ)」や「位相(波のタイミング)」のデータとして変換(エンコード)される。エンコードされた光がチップ内の「散乱領域(Scattering Region)」と呼ばれる複雑な構造に入射すると、光は無数の微小な障害物にぶつかって散乱し、波同士が複雑に干渉し合いながら進んでいく。
研究チームは、この散乱領域における光の物理的な伝播プロセスそのものが、AIのニューラルネットワークで行われている「行列の積和演算(複数のデータに重みを掛けて足し合わせる計算)」と数学的に等価になるようにチップの構造を設計した。つまり、特定の画像データを表す光の波紋を入力した際、複雑な干渉を経た結果として、チップの終端にある特定の出力ポート(例えば「腫瘍あり」を示すポート)にのみ光のエネルギーが集中するように作られているのである。光が構造体を通り抜けるピコ秒の間に、AIの推論計算が物理現象として自動的に完了するという極めてエレガントな仕組みである。
1平方ミリメートルに4億パラメータを詰め込む「逆設計(Inverse-design)」
このような都合の良い光の迷路を、人間の直感だけで設計することは不可能である。そこで研究チームが導入したのが、「逆設計(Inverse-design)」と呼ばれる革新的な計算手法である。これは、求める結果(どの出力ポートに光を集めたいか)から逆算して、デバイスの最適な材質配置をアルゴリズムに探索させるトポロジー最適化技術である。
具体的には、チップ上の微小な空間(ボクセル)一つひとつを、光を通しやすいシリコン(Si)にするか、屈折率の異なる二酸化ケイ素(SiO2)にするかを、アルゴリズムが自動的に決定していく。この最適化の過程において、チームは電磁波の振る舞いを厳密に計算する「3次元有限差分時間領域法(3D-FDTD)」という高度なシミュレーションを用いた。マクスウェル方程式(電磁気学の基礎方程式)が持つ線形性を巧みに利用することで、膨大なデータセットに対する順伝播のシミュレーションを線形分離可能な独立した計算に分割し、グラフィック処理装置(GPU)の並列処理能力を最大限に引き出すことに成功した。
この高度な逆設計と最適化の結果、チップ内の光波長よりも小さなサブ波長構造(最小加工寸法80 nm)のすべてが、AIのネットワークにおける「学習可能な重み(パラメータ)」として機能するようになった。これにより、わずか1平方ミリメートル(mm²)あたり約4億個ものパラメータを高密度に集積することが可能となった。従来の電子AIチップのように、計算のたびにメモリから重みデータを読み出す必要はなく、重みは物理的な構造としてあらかじめチップ内に焼き付けられている(In-memory optical computing)。これが、圧倒的な低遅延と省電力を実現する核心である。
医療画像分類における実証:ピコ秒スケールの推論精度
理論的な設計の妥当性を証明するため、研究チームは実際にシリコン・オン・インシュレータ(SOI)基板上に2種類のプロトタイプチップを製造し、厳密な実証実験を行った。一つは手書き数字の画像データセット「MNIST」を分類するためのチップであり、サイズはわずか20 × 20マイクロメートル(µm²)である。もう一つは、より複雑な医療画像データセット「MedNIST」(乳房MRI、胸部X線、腹部CTなど6種類のクラス分類)を処理するためのチップであり、こちらは30 × 20 µm²のサイズで構成された。
実験では、画像データの特徴を光の振幅データとしてチップの複数の入力ポートから注入し、出力ポートにおける光の強度を測定して分類結果を判定した。その結果、MNISTデータセットにおいては89%、より複雑なMedNISTデータセットにおいても90%という高い分類精度をオンチップ上で達成した。シミュレーション上の理論値(最大99.1%)と比較してわずかに精度が低下しているのは、半導体製造プロセスにおける数十ナノメートルレベルの微小な露光誤差などが影響していると論文内で考察されている。
しかし、注目すべきはこれらの推論処理にかかる時間である。入力された光信号がナノ構造を通過して出力されるまでの時間はピコ秒スケールであり、これは現在の最先端の電子GPUを凌駕する圧倒的なスピードである。さらに、光の振幅を主要な情報伝達手段として用いているため、入力時の光の位相(波のタイミング)に予期せぬズレが生じた場合でも、高い分類精度を維持できるという優れた堅牢性も確認されている。
持続可能なAIインフラに向けた未来の展望
今回のシドニー大学による研究成果は、単なる基礎研究の成功に留まらず、次世代の持続可能なAIハードウェアの社会実装に向けた重要なマイルストーンとなる。製造に用いられたSOIプラットフォームは、現在の半導体産業(CMOSプロセス)で広く標準的に使われている技術であり、既存のシリコンチップ製造ラインとの互換性が極めて高いからだ。これは、ナノフォトニック・アクセラレータの大規模な量産が現実的な視野に入っていることを意味している。
今後の展望として、チームはこの逆設計されたPNNコアを複数層に重ね合わせることで、さらに大規模で深いニューラルネットワークを構築する「スケーラビリティ」の青写真も描いている。さらに、光特有の技術である波長分割多重(異なる色の光を同時に送る技術)や偏波多重を組み合わせれば、同じ極小のチップ上で複数のAIタスクを同時に、かつ干渉することなく並列処理させることも可能になる。
AIの進化が人類に計り知れない恩恵をもたらす一方で、その裏側にあるエネルギー消費という「物理的コスト」はもはや無視できない限界に達しつつある。電子から光へ、計算の媒体そのものを変革するこのナノフォトニックAIチップは、演算能力の向上と環境負荷の低減という、相反する要求を同時に満たす「持続可能なコンピューティング」の切り札となる可能性を大いに秘めている。
論文
- Nature Communications: Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing
参考文献


