本日最初の撮影画像を公開し、その“世代的飛躍”を果たす能力を見せつけたヴェラ・C・ルービン天文台は、2025年後半より天文学の歴史を塗り替える10年間の大規模探査「Legacy Survey of Space and Time(LSST)」を開始する。これは単に美しい星空を眺めるプロジェクトではない。人類が初めて手にする、宇宙の「タイムラプス映画」を制作する壮大な試みだ。
しかし、その野心は想像を絶するデータ量を伴う。毎夜生成される生データは20テラバイト(TB)、10年間の調査終了を待たずして、処理後の総データ量は500ペタバイト(PB)に達すると予測されている。これは、人類がこれまでに書き記したあらゆる言語の全著作物を合わせた量に匹敵する、まさに「データ津波」である。
この記事では、この前例のないデータ量をいかにして処理し、科学的知見へと昇華させるのか、その技術的な挑戦と革新の舞台裏を掘り下げてみよう。
毎夜20TB、10年で500PB――天文学を再定義する「データ津波」
LSSTの中核をなすのは、世界最大の3200メガピクセル(3.2ギガピクセル、32億画素)デジタルカメラだ。この怪物的カメラは、わずか40秒ごとに8ギガバイト(GB)もの高精細画像を撮影し、南天の全天を3夜でスキャンする。この驚異的な速度と視野の広さが、宇宙の動的な姿を捉える鍵となる。
プリンストン大学の研究者で、ルービンの画像処理アルゴリズムを統括するYusra AlSayyad氏は、このプロジェクトを「空のドライブレコーダー」と表現する。「これまでの広視野サーベイは、スナップショットを与えてくれたに過ぎません。しかし、空は静的ではなく、生きているのです」。爆発する超新星、突如現れては消える謎の天体、そして太陽系を駆け巡る小惑星。LSSTは、これらの「一瞬」を捉え、時間を巻き戻して何が起きたのかを検証する能力を科学者に与えるのだ。
この「動的な宇宙」という新たな視点を得る代償が、500PBというデータ量である。20年前には、この規模のデータを保存し、処理し、転送する技術は存在しなかった。ストリーミングビデオの普及を支えたストレージ、並列コンピューティング、広帯域ネットワーク、そして高度なアルゴリズムの進歩が、LSSTを現実のものとしたのである。
光速のデータリレー:チリ山頂から世界へ、7秒の戦い
撮影されたデータは、瞬く間に地球規模のデータ処理パイプラインを駆け巡る。この流れは、精密に設計された技術の連携によって成り立っている。
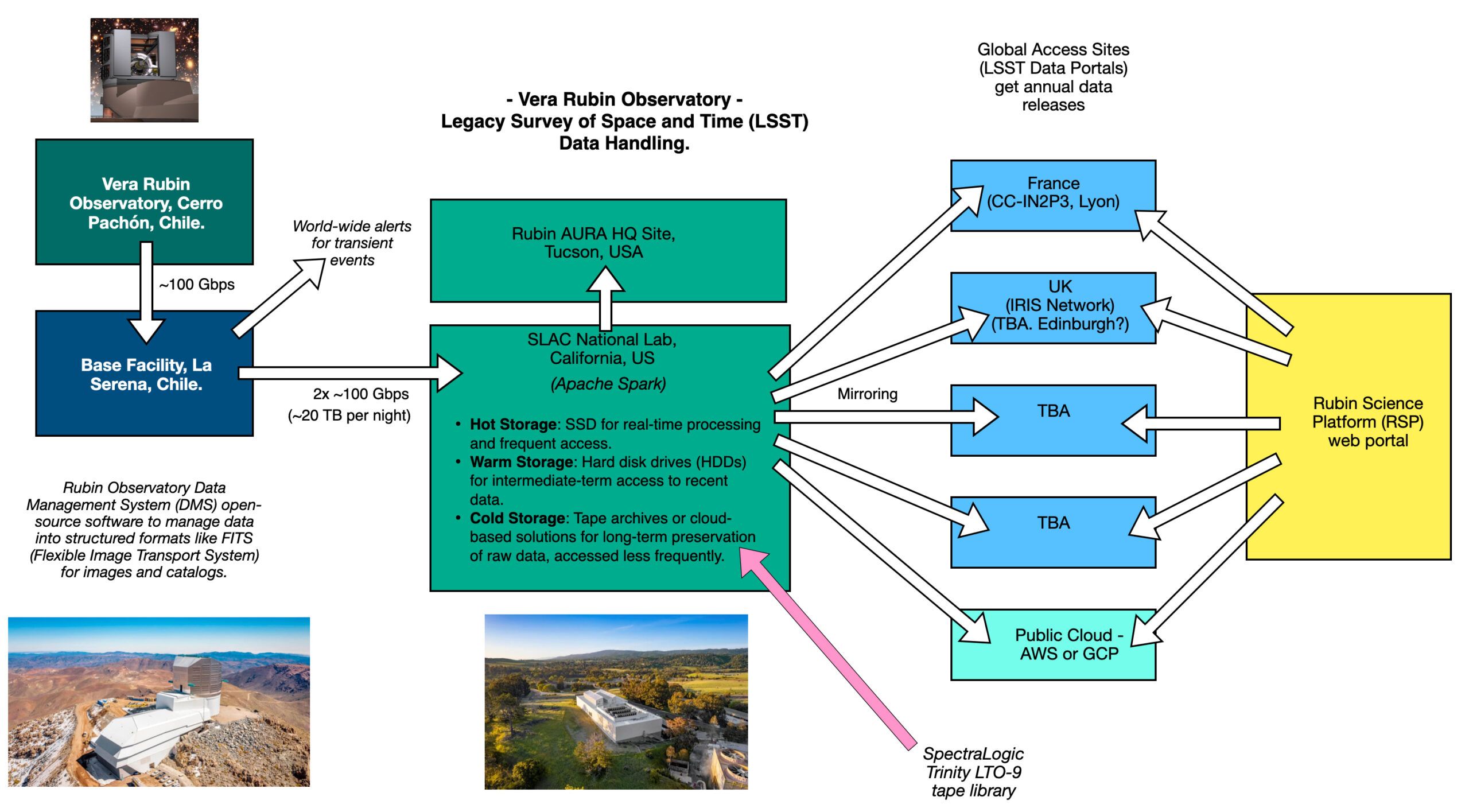
山頂からSLACへ:専用線が繋ぐ9,000km
チリのセロ・パチョン山頂で撮影された画像は、7秒以内に、9,000km離れた米国カリフォルニア州のSLAC国立加速器研究所にある米国データ施設(USDF)に転送される。これを実現するのが、山頂からチリの都市ラ・セレナまで敷設された600ギガビットの光ファイバーと、そこから米国へ繋がる100ギガビットの専用線(および40ギガビットのバックアップ回線)だ。毎夜20TBというデータを滞留させないためには、この極太のデータハイウェイが生命線となる。

60秒の攻防:リアルタイムアラート生成と「ブローカー」の役割
SLACに到着したデータは、直ちに初期処理が開始される。新しい画像は過去の参照画像と比較され、明るさや位置に変化があれば即座にフラグが立てられる。このプロセスを経て、1夜あたり最大1000万件もの「アラート」が生成される。これらは、超新星の爆発や危険な小惑星の発見といった、一刻を争う宇宙イベントの可能性を秘めている。
これらの膨大なアラートは、単に配信されるわけではない。「ブローカー」と呼ばれる、機械学習アルゴリズムに基づいた特殊なソフトウェア群が待ち構えている。ブローカーはアラートを瞬時に分類し、例えば「Type Ia超新星」に興味がある研究者、「地球近傍小惑星」を監視する機関など、世界中の科学者の元へ適切な情報を届ける。撮影からわずか60秒以内にこのアラートが発行されるという驚異的なリアルタイム性が、他の望遠鏡による追跡観測を可能にするのだ。
世界に広がる知の拠点:仏・英データ施設との連携
データ処理の負荷はSLACだけに集中するわけではない。撮影から80時間以内に、画像データはフランスのデータ施設(FrDF)と英国のデータ施設(UKDF)にもミラーリングされ、保存される。この分散処理体制は、データの冗長性を確保するだけでなく、世界中の研究者が自国に近い拠点から高速にデータへアクセスできる環境を提供する。
興味深いことに、この巨大データの管理には、素粒子物理学の知見が生かされている。SLACの情報システムスペシャリスト、Wei Yang氏によると、「我々は元々CERNのATLAS実験のために開発されたソフトウェアを利用しています。これは、巨大なデータ量と数百億もの個別オブジェクトを複数のサイトで管理するという、同様の課題に直面していました」。分野を超えた技術の融合が、このプロジェクトを支えているのだ。
「Coadding」と再処理:ノイズから宇宙の真実を掘り起こす
リアルタイムのアラート処理は、ルービン天文台が生成するデータのほんの序章に過ぎない。真の科学的発見は、毎年行われる大規模なデータリリースと、その後の緻密な再処理から生まれる。
画像を重ねて創る「超高深度宇宙」
毎年、何百枚もの画像が「Coadding(コアディング)」という手法でデジタル的に重ね合わされ、一枚の超高深度合成画像が作成される。SLACのスタッフサイエンティスト、Eli Rykoff氏が説明するように、「空の画像を何度も何度も積み重ね、すべてを足し合わせることで、信じられないほど深い写真を作り出す」のだ。個々の画像ではノイズに埋もれて見えなかった、遥か彼方の暗い銀河や淡い星雲が、この処理によってその姿を現す。
過去への遡及分析:光度曲線が解き明かす天体の生涯
この超高深度画像が完成すると、処理はさらに次の段階へ進む。科学者たちは、この「完璧な地図」を元に、過去に撮影された個々のフレームへと遡るのだ。「この深い画像のこの地点で、あの瞬間の光はどうだったのか?」と問いかける。このプロセスを何百回と繰り返すことで、一つの天体の明るさが時間と共にどう変化したかを示す「光度曲線」を再構築できる。
この光度曲線こそが、ダークエネルギーの謎を解く鍵とされるType Ia超新星を何百万個も発見したり、天の川銀河の構造を精密にマッピングしたりするための、最も重要なデータとなる。
500PBを支える心臓部:SSD、HDD、そしてテープが織りなす階層型ストレージの妙
この巨大なデータフローと複雑な処理を物理的に支えているのが、SLACに構築された最先端のデータセンターと、その巧みなストレージ戦略だ。データの特性に応じて役割を分担する「階層型ストレージ」こそ、このプロジェクトの心臓部と言えるだろう。
ホット、ウォーム、コールド:データ特性に最適化された3階層
ルービンのデータは、そのアクセス頻度や処理の緊急性に応じて、3つの階層に分けて管理される。
- ホットストレージ(SSD): リアルタイムでのアラート生成や即時分析が必要な最新データは、読み書き速度が最も速いSSD(ソリッドステートドライブ)に配置される。
- ウォームストレージ(HDD): 年次データリリースに向けた処理や、比較的頻繁にアクセスされるデータは、大容量かつコストパフォーマンスに優れたHDD(ハードディスクドライブ)に保存される。
- コールドストレージ(テープ): 処理が完了し、長期的なアーカイブが目的となる膨大な生画像データや過去のデータリリースは、最も安価で信頼性の高い磁気テープに保存される。
Spectra Logic Tfinity:天文台の記憶を刻む巨大テープライブラリ
特に重要なのが、このコールドストレージだ。SLACでは、Spectra Logic社製の「Tfinity ExaScale」テープライブラリシステムが導入されている。この巨大なロボットアーム付き書庫は、LTO-9規格のテープカートリッジを自動で出し入れし、年間6PBのペースで増え続けるデータを確実にアーカイブしていく。管理には、階層型ストレージ管理ソフトウェアの標準である「HPSS」が用いられる。この戦略は、フランスのCC-IN2P3データセンターでも採用されており、グローバルな標準技術で天文台の「記憶」を守っている。
ローカルにも要塞を:チリに設けられた1ヶ月分のデータセンター
さらに、万が一の事態にも備えは万全だ。チリの天文台施設内には、ネットワーク障害など不測の事態が発生した場合に備え、最低1ヶ月分の観測データをローカルに保存できるデータセンターが建設されている。この冗長性が、10年間にわたる観測の継続性を保証する最後の砦となる。
天文学の未来:AIが拓く「データマイニング」の新時代
これほどのデータが揃ったとしても、それを人間だけで分析するのは不可能だ。ルービン天文台は、天文学を「望遠鏡を覗く」時代から「データを掘る(データマイニング)」時代へと完全に移行させる。そして、その主要なツールとなるのがAIである。
GitHubで公開されるコードと「Rubin Science Platform」
ルービンは、オープンサイエンスの精神を徹底している。データ処理に使われるコードはすべてGitHubで公開され、世界中の誰もがそのロジックを検証し、改善提案を行うことができる。さらに、「Rubin Science Platform」という強力なWebポータルを通じて、科学者はSLACの計算資源を直接利用し、このデータの大海を航海できる。
「火の出るようなデータ」を乗りこなすAI
カーネギー科学研究所の天文学者Scott Sheppard氏は、この状況を「火の出るようなデータ(firehose of data)が流れ込んでくる」と表現する。この膨大なデータストリームから意味のある信号、すなわち科学的発見を見つけ出すために、AIの活用は不可欠だ。副プロジェクトマネージャーのWilliam O’Mullane氏も、AIがこの規模のデータを分析する上で重要な役割を果たすことを示唆している。パターン認識、異常検知、分類など、AIは人間では不可能な速度と精度でデータをふるいにかけ、有望な発見の候補を提示するだろう。
発見は「未知との遭遇」:予期せぬ発見への期待
しかし、ルービン・プロジェクトが最も期待されているのは、私たちがまだ予測すらしていない「未知との遭遇」かもしれない。この前例のないデータセットは、既存の理論では説明できない現象や、全く新しい種類の天体を必ずや明らかにするはずだ。それこそが、技術の限界を押し広げてまで、この壮大なデータ収集に挑む真の理由ではないだろうか。
このプロジェクトは、ハードウェアの偉業、ソフトウェアの洗練、そして国境を越えた「人の協力」という三位一体によって成り立っている。技術の粋を集めて構築されたこのシステムは、私たちの宇宙観そのものを根底から覆す、パラダイムシフトの幕開けを告げているのだ。
Sources
- Vera C. Rubin Observatory: Ready, Set, Process: Preparing for Rubin Observatory’s Data Deluge
- IEEE Spectrum: How the Rubin Observatory Will Reinvent Astronomy