
GPU業界の伝説的エンジニア、Raja Koduri氏が次なる舞台に選んだのは、ストレージ大手のSanDiskだった。彼が挑むのは、AIの性能を根底から覆す可能性を秘めた新メモリ技術「HBF(High-Bandwidth Flash)」だ。最大4TBという前代未聞のVRAM容量は、HBMが築いた牙城を崩し、AI業界の勢力図を塗り替える挑戦の始まりとなるのだろうか。
グラフィックスの巨匠、次なる戦場は「メモリ」
Raja Koduri氏の名は、PCハードウェアの歴史と共に歩んできた。S3 Graphicsに始まり、ATI、AMD、Apple、そしてIntel。彼のキャリアは、グラフィックスアーキテクチャの進化そのものと言っても過言ではない。AMDではRadeonシリーズの根幹を築き、Intelでは野心的な「Arc」GPUプロジェクトをゼロから率いた。2023年にIntelを去り、自身のAIスタートアップに注力していた彼の新たな動きは、多くの業界関係者を驚かせた。
なぜ、GPUアーキテクトの彼が、SSDやフラッシュメモリで知られるSanDiskへ向かったのか。その答えは、同社が開発を進める一つの革新的技術にある。それが「HBF(High-Bandwidth Flash)」だ。Koduri氏は、SanDiskが新設したHBF技術諮問委員会の中核メンバーとして参画し、その開発と戦略を主導する。彼の長年の探求テーマであった「高帯域幅」への挑戦が、新たな局面を迎えた瞬間である。
AIのボトルネックを破壊する「HBF」の正体
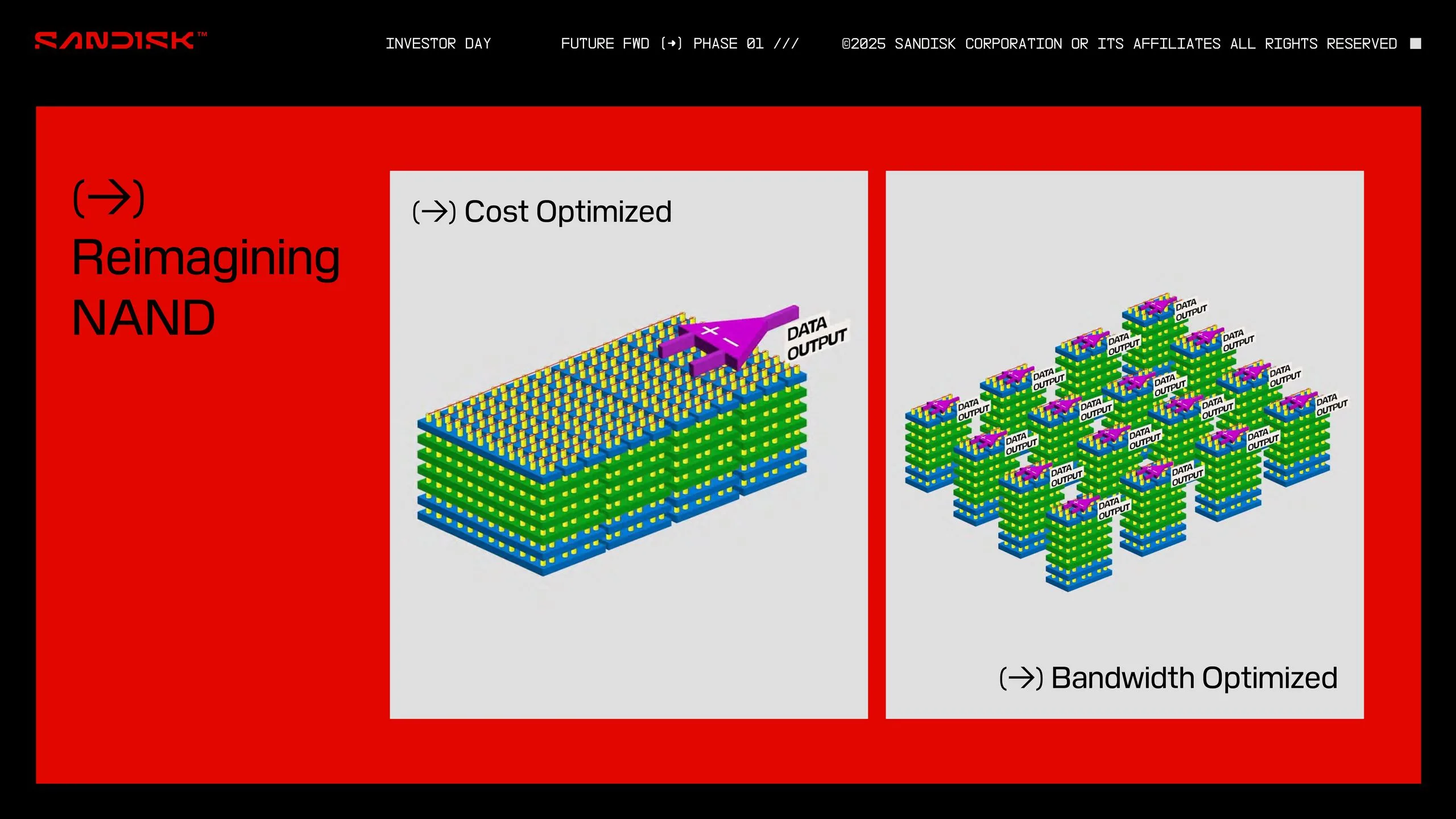
HBFは、AIコンピューティング、特に推論ワークロードにおけるメモリの制約を打破するために設計された、全く新しいメモリソリューションだ。その核心は、既存の技術の巧みな融合にある。
HBMの思想をNANDフラッシュに応用
HBFの基本概念は、現在のAI向けGPUで標準となっている「HBM(High-Bandwidth Memory)」の思想を、DRAMではなくNANDフラッシュに応用するというものだ。
- 技術概要: HBFは、複数のNANDフラッシュのダイを垂直に16層まで積層し、TSV(Through-Silicon Vias、シリコン貫通電極)技術で相互接続する。この積層チップをインターポーザーと呼ばれる基板を介してGPUに直接接続することで、個々のダイのI/Oチャネルを集約し、極めて高い帯域幅を実現する。これは、DRAMダイを積層するHBMと構造的に酷似している。
- 目標性能: SanDiskによれば、HBFはHBMに匹敵する帯域幅を提供しながら、8倍から16倍という圧倒的な容量を、同程度のコストで実現することを目指している。これにより、1基のAIアクセラレータが搭載できるVRAMは、理論上最大4TBに達する。
HBFの核心は、SanDisk独自のBiCS 3D NAND技術とCBA(CMOS directly bonded to Array)ウェハーボンディング技術にあり、これにより超低反りの16層スタッキングを可能にしている。

NVIDIAのフラッグシップAI GPU「H100」が搭載するVRAMは80GB。HBFが実現する4TBという容量は、その実に50倍に相当する。これは単なる性能向上ではなく、ゲームのルールを変えかねないパラダイムシフトだ。
「HBM開発時、我々の焦点はワットあたり・面積あたりの帯域幅向上にあった。HBFでは、焦点はコストあたり・ワットあたり・面積あたりのメモリ容量を劇的に増やすことにある。」
Koduri氏が指摘するように、HBFはHBMとは異なる哲学に基づいている。HBMが「帯域幅」を最優先したのに対し、HBFは「容量」という新たな価値軸で勝負を挑む。
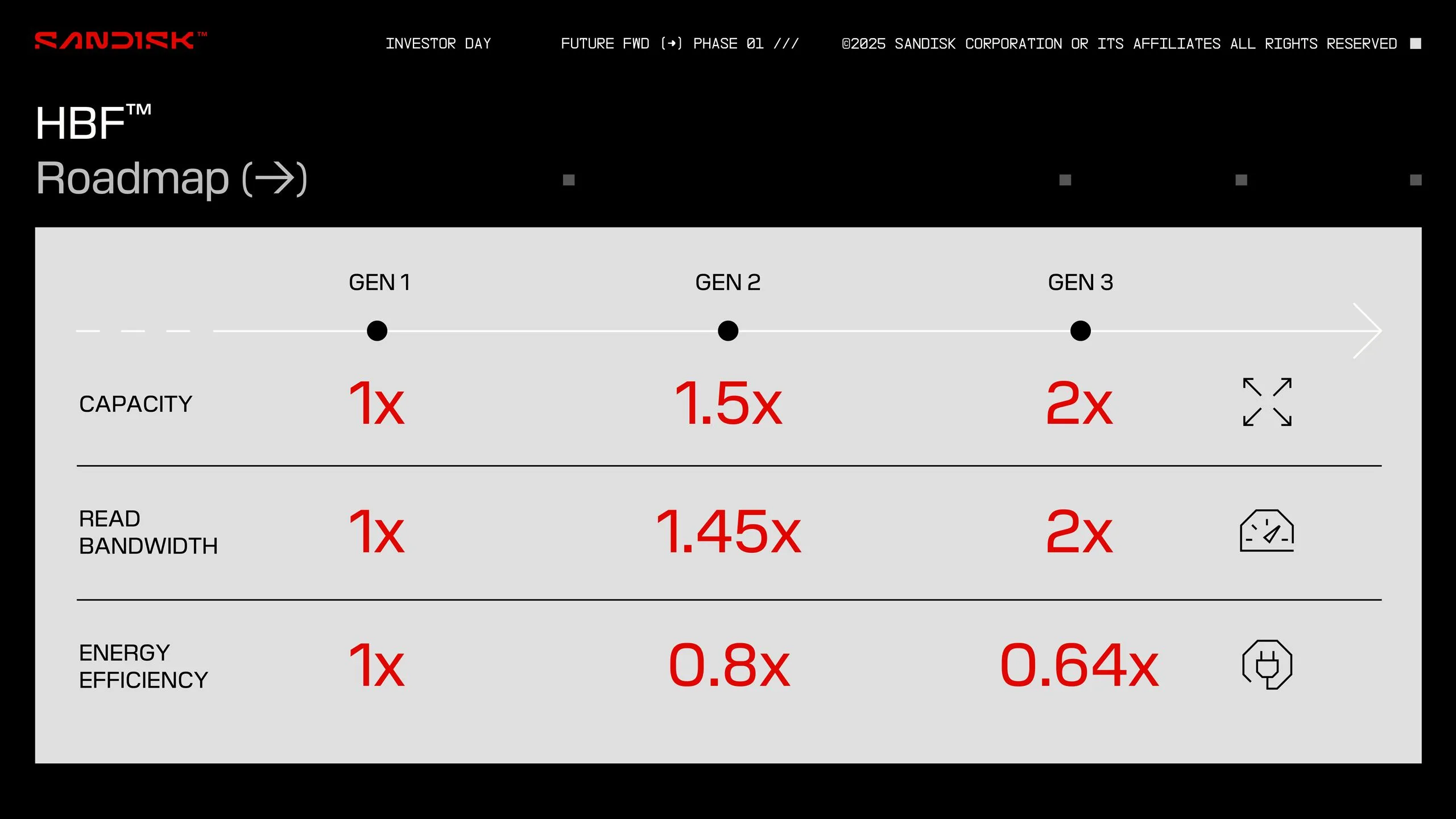
しかし、NANDフラッシュベースであるため、HBFはDRAM(HBM)と比較してアクセスレイテンシが長いという特性を持つ。このため、SanDiskはHBFをHBMの直接的な代替ではなく、むしろHBMを補完する追加のメモリ階層として位置付けているようだ。特に、AIの推論ワークロードや大規模モデルの開発といった、大量のデータがシーケンシャルに読み込まれる用途において、HBFの超大容量と高い帯域幅がそのレイテンシのデメリットを上回るメリットを提供すると考えられている。
AI時代が求める超大容量メモリ:4TB VRAMの衝撃
人工知能、特に生成AIや大規模言語モデル(LLM)の進化は、GPUに搭載されるVRAM(ビデオメモリ)の容量に前例のないほどの要求を突きつけている。現在のNVIDIA H100のようなAI向けGPUが80GBのVRAMを搭載しているのに対し、SanDiskのHBF技術が目指す4TBというVRAM容量は、実に50倍以上もの飛躍的な増加を意味する。
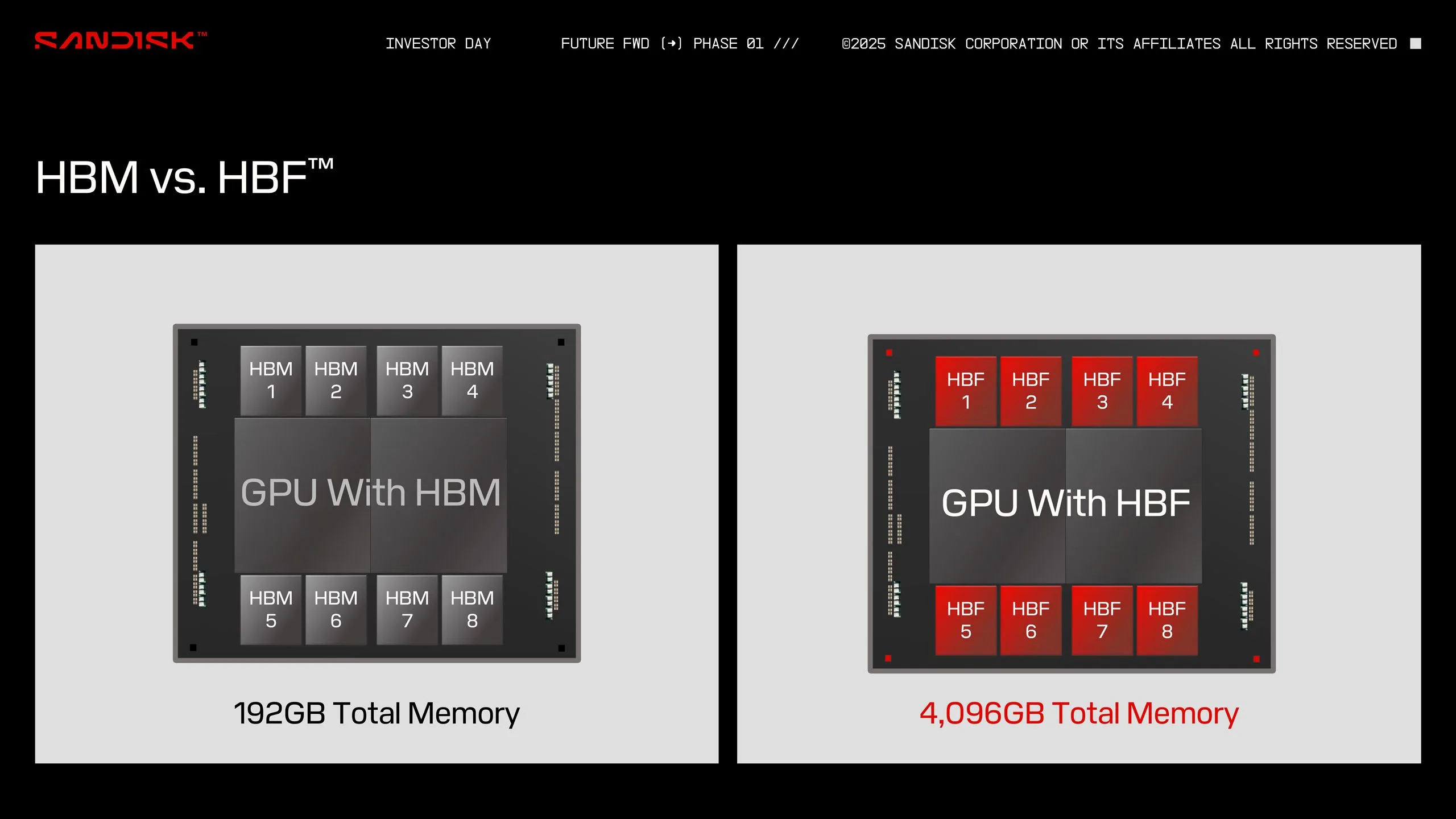
これにより、現在のVRAM容量ではGPU上に全てを保持しきれず、より低速なシステムメモリやSSDとの間で頻繁なデータ交換が必要だった大規模AIモデルも、直接GPUのVRAMに格納できるようになる。これは、AIトレーニングや推論の効率を劇的に向上させ、応答速度を改善する可能性を秘めている。特に、リアルタイムで複雑なモデルをローカルで実行するエッジAIアプリケーションにおいて、HBFは革命をもたらす可能性があるとKoduri氏は指摘している。
「HBFは、デバイスにメモリ容量と帯域幅の能力を付与することで、エッジAIに革命をもたらし、複雑なモデルをローカルでリアルタイムに実行することを可能にするだろう」とKoduri氏は述べている。 この進化は、AI推論の実行方法と場所を根本的に変える可能性を秘めているのである。
巨頭NVIDIAへの挑戦状か?市場へのインパクトと課題
SanDiskの野心的な試みは、強力な布陣によって支えられている。しかしその先には、巨大な壁もそびえ立つ。
諮問委員会に集う「ドリームチーム」
Koduri氏と共にHBF技術諮問委員会を率いるのは、コンピュータ科学の生きる伝説、David Patterson教授だ。RISC(Reduced Instruction Set Computing)アーキテクチャやRAIDの共同開発者として知られ、チューリング賞の栄誉にも輝く同氏は、HBFのポテンシャルをこう語る。
「HBFは、データセンターAIにおいて重要な役割を果たす可能性を示している。現在では法外なコストがかかる新しいAIアプリケーションのコストを押し下げるかもしれない。」
— David Patterson教授
グラフィックスアーキテクチャの第一人者であるKoduri氏と、コンピュータサイエンスの基礎を築いたPatterson教授。この「ドリームチーム」の存在は、HBFが単なるメモリ部品ではなく、未来のAIコンピューティング基盤そのものを見据えたプロジェクトであることを物語っている。
残された最大のピース「NVIDIA」
しかし、HBFの前に立ちはだかる最大の課題は、AI市場の8割以上を支配するNVIDIAの存在だろう。HBFはGPUとインターポーザーで接続する構造上、その採用はGPUメーカーの判断に委ねられる。現在、HBMの仕様とエコシステムは事実上NVIDIAが主導しており、メモリメーカーはそれに追従する構図だ。
注目すべきは、今回発表された技術諮問委員会に、NVIDIAの関係者が含まれていない点だ。これは、SanDiskがまずAMDやIntel、あるいは自社でAIチップを開発するハイパースケーラーといった「非NVIDIA陣営」との連携を深め、HBFをオープンスタンダードとして確立することで、NVIDIAの牙城を外から崩そうという戦略の表れとも考えられる。
この挑戦的な戦略において、AMDとIntelの両社でGPUアーキテクチャを率いたKoduri氏の人脈とエコシステム構築の経験は、計り知れない価値を持つだろう。
これは、単なる新技術の発表ではない。AIの進化がメモリ容量という壁に突き当たり始めた今、その制約を破壊しようとする壮大な挑戦である。HBFが本当にHBMに代わる存在となり得るのか、そしてNVIDIAがこの動きにどう反応するのか。AI業界の次なる覇権争いは、すでに始まっている。
Sources


