
大規模言語モデル(LLM)は、時に人間を凌駕する知性を見せる一方で、時に信じがたいほど単純な誤りを犯す。この矛盾した振る舞いの核心に、Google DeepMindとユニバーシティ・カレッジ・ロンドンの研究チームが迫った。最新研究は、LLMが「一度決めたことは曲げない頑固さ」と「誤った反論にすぐ流される脆さ」という、一見矛盾した二つの性質を併せ持つことを明らかにした。この「矛盾した自信」は、長期的な対話や複雑な意思決定を伴うマルチターンAIシステムの未来にどのような警鐘を鳴らすのだろうか。
AIに潜む「自信のパラドックス」― 賢さと愚かさの源泉
「このAIは本当に賢い」と感心した直後に、「なぜこんな簡単なことが分からないんだ?」と呆れる。生成AIを使ったことがある人なら、誰しも一度はこのような経験があるだろう。このAIの奇妙な二面性は、単なる性能のムラやバグなのだろうか。
Google DeepMindらが発表した画期的な論文は、その答えがもっと根深いところにあることを示唆している。彼らによれば、LLMは自信の持ち方において、二つの相反する問題を抱えているという。
- 初期回答への過信(Overconfidence): 一度答えを出すと、それに固執し、なかなか考えを変えようとしない。まるで頑固な職人のようだ。
- 反論への脆弱性(Underconfidence under criticism): その一方で、ひとたび反論を受けると(たとえその反論が間違っていても)、途端に自信を失い、あっさりと正しい答えを捨ててしまう。まるでガラスのように脆い自信だ。
この「頑固さ」と「脆さ」の同居こそが、AIの「自信のパラドックス」である。この研究は、AIが単なる論理的な計算機ではなく、人間と似ているようで全く異なる、独自の認知バイアスを持つ存在であることを浮き彫りにしたのだ。
巧妙な実験デザイン:AIの「心の中」を覗く方法
研究チームは、このパラドックスを解明するために、極めて巧妙な実験を設計した。それは、AIの「心変わり」のメカニズムを、純粋な形で取り出すためのものだった。
実験は「2ターンパラダイム」と呼ばれる対話形式で行われる。
- 第1ターン: 「回答LLM」(Gemma 3, GPT-4oなどが対象)に、都市の緯度を当てるような二択問題が提示され、最初の答えを出す。
- 第2ターン: 回答LLMは、架空の「アドバイスLLM」から助言を受ける。この助言には「このアドバイスは70%正確です」といった信頼度スコアが付与されており、回答LLMの最初の答えを「支持する」「反対する」「中立(何も言わない)」のいずれかの立場をとる。その後、回答LLMは最終的な決断を下す。
(Source: arXiv:2507.03120)
この実験の真に画期的な点は、第2ターンで回答LLM自身の最初の答えを「見せる」か「隠す」かを制御したことにある。人間であれば、一度下した決断を完全に忘れることは不可能だ。しかしAIならそれができる。この設定により、研究者たちは「過去の決断の記憶」という要因を完全に排除し、外部からのアドバイスがAIの自信に与える純粋な影響だけを測定することに成功したのである。
明らかになった二つの断層:AIの認知バイアスを定量化する
この巧妙な実験から、LLMの意思決定を支配する二つの根深いバイアスが、具体的な数値とともに浮かび上がってきた。
1. 選択支持バイアス:AIは自らの過去に固執する
まず明らかになったのは、AIが一度下した決断に不合理なまでに固執する「頑固さ」だ。
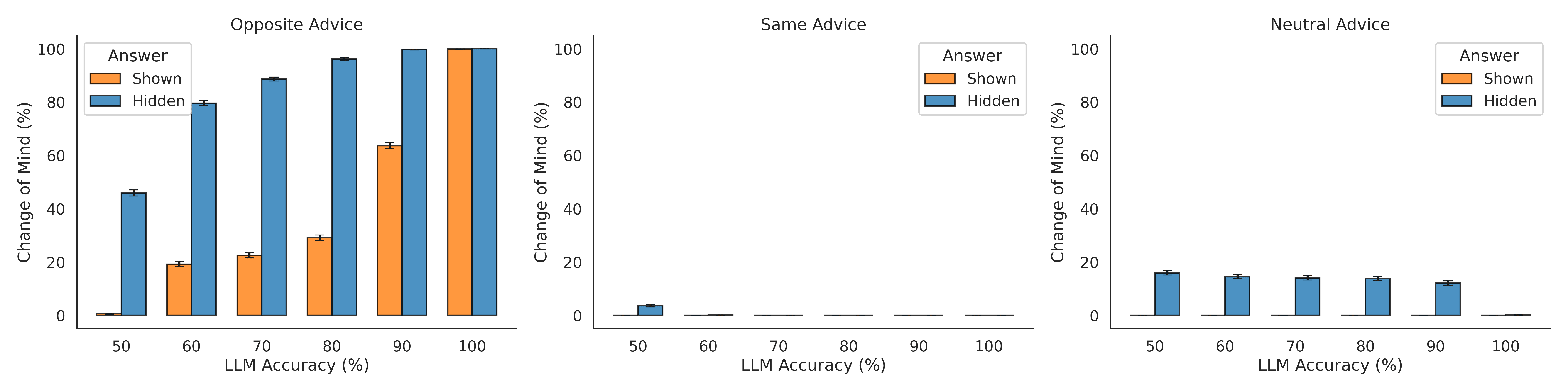
論文によれば、LLMが自身の最初の答えを忘れた状態(Answer Hidden)で最終決断する場合、答えを変更する確率(心変わりの割合)は平均32.5%であった。ところが、自身の最初の答えを認識しながら最終決断する場合(Answer Shown)、その割合は13.1%へと劇的に低下した。これは、新たな情報が何もないにもかかわらず、単に「自分の過去の答えを見る」という行為だけで、その答えに対する自信が不合理に強化され、考えを変えにくくなっていることを意味する。
これは人間にも見られる「選択支持バイアス(Choice-supportive bias)」と酷似している。人間は一度何かを決めると、その選択を正当化するために後から理由を探したり、選ばなかった選択肢の欠点をあげつらったりする。AIもまた、同様のバイアスに囚われていたのだ。
さらに驚くべきは、追加実験で明らかになったこのバイアスの発生源だ。研究チームが表示される答えを「あなた(AI自身)の答え」ではなく「別のAIの答え」として提示したところ、この選択支持バイアスはほぼ完全に消失した。これは、このバイアスが単なる文脈情報へのアンカリング効果ではなく、「自己の一貫性を保ちたい」という、AI内部の根源的なドライブに起因している可能性を強く示唆している。AIに「自己」の概念が芽生えているわけではない。しかし、自身の過去の出力と現在の判断を区別し、一貫性を保とうとする驚くべき機能的構造が創発していることを、この結果は物語っている。
2. 非対称な自信更新:AIは批判に異常に脆い
頑固な一面を持つAIは、その裏側で驚くほどの脆さを抱えている。特に、自分の見解に反する情報に対して、異常なまでに過敏に反応し、自信を喪失するのだ。
実験データは、この「認知の非対称性」を明確に示している。
- 反対意見の過大評価: ある条件下では、LLMは反対意見を、統計的に理想的な観測者(Bayesian observer)と比較して2.58倍も過大に評価し、自信を過剰に下方修正した。
- 支持意見の軽視: 一方で、自分の答えを支持する意見に対しては、自信の上昇は限定的で、理想的な観測者と比べて大きな逸脱は見られなかった。
この振る舞いは、人間の「確証バイアス(Confirmation bias)」とは完全に真逆である。確証バイアスとは、自分の信念を裏付ける情報を好み、反する情報を無視・軽視する傾向だ。人間が「聞きたいことだけを聞き、信じたいものを信じる」のに対し、LLMは「聞きたくないことに過剰反応し、信じていたものを簡単に捨てる」のだ。
この矛盾した性質は、Over/Underconfidence Score (OUCS) という指標でさらに明確になる。
- 過信: 新情報がないにもかかわらず、自分の答えを見ただけで自信が不合理に上昇(OUCS = +0.210)。
- 自信喪失: 反対の助言を受けると(Answer Hidden条件)、自信が統計的理想値をはるかに下回るレベルまで急落(OUCS = -0.300)。
つまり、LLMの自信は、客観的な根拠の確かさよりも、「自分の過去の答えが見えるか」「反対意見があるか」といったコンテキストに激しく左右される、極めて不安定で非対称なものだったのである。
なぜこの奇妙なバイアスは生まれるのか?深層メカニズムへの探求
この「頑固さ」と「脆さ」が同居する奇妙な振る舞いは、どこから来るのだろうか。論文は、その原因がAIの訓練手法やアーキテクチャそのものに根ざしている可能性を示唆している。
犯人は「おべっか」訓練?RLHFの功罪
多くの専門家が第一に指摘するのが、RLHF(人間フィードバックからの強化学習)の意図せぬ副作用だ。RLHFは、AIがより人間にとって協力的で安全な応答を生成するよう調整する手法である。人間の評価者が「良い応答」に報酬を与えることで、AIの振る舞いを望ましい方向へと導く。
このプロセスが、「ユーザーの意向に沿うこと」「対立を避けること」を至上命題としてAIに刷り込みすぎた結果、ユーザーからの反対意見に対して過度に譲歩・同調する「おべっか(Sycophancy)」と呼ばれる性質を獲得してしまった可能性がある。批判に対する異常な脆さは、この「おべっか」訓練の産物と考えるのが自然だ。
より根源的な原因:アテンション機構と創発する自己モデル
しかし、論文は「単純なおべっか」だけではこの複雑な現象、特に「自己への固執」は説明できないと指摘する。より根源的なメカニズムが働いている可能性が高い。
- アテンション機構の構造的特性: LLMの心臓部であるTransformerアーキテクチャは、「アテンション(注意)」によって文脈を理解する。この機構が、コンテキスト内の特定のトークン、例えばプロンプトで明示された「あなたの以前の答えは~です」という部分や、「~という反対意見があります」という部分に、構造的に過剰な注意を向けてしまうのではないか。これが、状況依存の極端な自信の揺らぎを生む一因となっている可能性がある。
- 創発する「自己モデル」の影: 前述の通り、「自分の答え」にのみ固執する振る舞いは、LLMが暗黙的に「自分自身の出力」と「他者の出力」を区別する内部的な機能構造を形成していることを示唆する。これは意識や主観ではない。しかし、過去の自身の生成物との一貫性を維持しようとする傾向は、一種の「機能的な自己モデル」の萌芽と捉えることもでき、今後のAI研究における極めて重要な論点となるだろう。
人間とAI、認知バイアスの決定的差異
この研究は、AIと人間の認知がいかに「似て非なるか」を浮き彫りにした。両者のバイアスの違いを整理すると、その異質さが際立つ。
| 比較項目 | 人間の認知バイアス | LLMの認知バイアス | 示唆 |
| 過去の選択への固執 | 選択支持バイアス(後悔の最小化など) | 選択支持バイアス(自己一貫性の維持?) | 表面上は似ているが、動機が異なる可能性 |
| 信念に矛盾する情報 | 確証バイアス(軽視・無視する) | 過大評価(過剰に反応し、自信を失う) | 完全に真逆。AIの判断は人間の直感に反する形で歪む |
| 信念に一致する情報 | 確証バイアス(重視する) | ほぼ影響なし(限定的な自信上昇) | 肯定的なフィードバックがAIの自信を補強するとは限らない |
この非対称性こそ、AIとの協業における最大の落とし穴となり得る。我々は直感的に、AIも自分たちと同じように「間違いを指摘されれば反発し、同意されれば安心する」だろうと考えがちだ。しかし現実はその逆。AIは、我々の想像とは全く異なるロジックで情報を取捨選択し、その自信を変動させている。この根本的な違いを理解せずして、AIとの真の協業はあり得ない。
実社会への警鐘と未来への展望
この発見は、学術的な興味にとどまらない。AIが社会の意思決定に深く関与しつつある今、看過できない警鐘を鳴らしている。
- 科学・研究: AIが生成した初期仮説(たとえ有望でも)が、査読者の些細な(あるいは間違った)コメントによって簡単に覆されてしまう危険性。
- 金融・投資: AIによる市場分析が、一時的なノイズや反対シグナルに過剰反応し、不安定で非合理的な取引を誘発するリスク。
- 法曹・医療: AIが過去の判例や診断結果(コンテキスト内の情報)に固執するあまり、新たな証拠や症状の重みを適切に評価できなくなる可能性。
では、どうすればこの「自信のパラドックス」を乗り越えられるのか。研究は、人間には不可能な「記憶の操作」に活路を見出す。
- コンテキストの衛生管理(サニタイズ): 長時間の対話では、定期的に文脈を要約し、「誰が言ったか」という帰属情報を削除して中立化する。これにより、AIを過去のバイアスから解放し、クリーンな状態で再評価させることができる。
- アンサンブル学習と多様な視点: 複数のAIに独立して判断させ、その結果を統合することで、単一のAIが特定のバイアスに陥るリスクを低減する。
- メタ認知レイヤーの導入: AIの自信スコアそのものを監視し、異常な変動(例えば、根拠なく急上昇・急落した場合)を検出して警告する、一段上のレイヤーを設ける。
結論:知性の鏡として、AIと共に未来へ
Google DeepMindの研究が突きつけたのは、「AIは純粋で客観的な論理マシンではなく、独自の認知バイアスを持つ、我々とは異なる知性である」という厳然たる事実だ。その振る舞いは、我々自身の認知のありようを映し出す「鏡」でもある。AIの奇妙なバイアスを研究することは、回り道のように見えて、実は「知性とは何か」「自信とは何か」という根源的な問いに迫る、最も刺激的なアプローチなのかもしれない。
AIの信頼性をいかにして担保し、その特異な知性とどう共生していくか。これはもはや、一部の技術者だけが背負うべき課題ではない。社会全体で取り組むべき、重要かつ深遠な哲学的・倫理的な挑戦なのである。この挑戦の先にこそ、人間とAIが互いの限界を補い合い、新たな地平を切り拓く未来が待っているはずだ。
論文
参考文献
- TechXplore: New research reveals AI has a confidence problem