NVIDIAは、中国DeepSeek社の巨大推論モデル「DeepSeek R1 0528」の知性を、より小型で効率的なモデル群に凝縮した「OpenReasoning-Nemotron」ファミリーをオープンソースとして公開したのだ。これは最先端のAI技術であった「推論能力」が、一部の巨大テック企業のクラウドから、世界中の開発者や研究者、さらには高性能なPCを持つ一般ユーザーの手にまで届く可能性を示唆する、画期的な出来事だ。
巨大な「教師」モデルから、その本質的な知識だけを効率的に「生徒」モデルへ移転する「知識蒸留」という技術を駆使し、NVIDIAはAIの民主化を新たなステージへと押し上げようとしている。
巨人の肩に乗る巨人:NVIDIAの巧妙な戦略
今回の発表の核心は、NVIDIAが他社、それもAI開発で急速に存在感を増す中国企業DeepSeekのフラッグシップモデル(671Bパラメータ)を「教師」として利用した点にある。そして、その知性を蒸留して生み出された4つの「生徒」モデル(1.5B、7B、14B、32Bパラメータ)を、商用利用も可能なオープンソースライセンスで公開したのだ。
これは一見、奇妙な動きに見えるかもしれない。なぜAIチップの盟主であるNVIDIAが、自社製ではなく他社のモデルを基盤に据えたのか。その答えは、NVIDIAが単なるハードウェアメーカーから、AI開発におけるプラットフォーマーへと脱皮しようとする巧妙な戦略にあると考えられる。
第一に、最高の「教師」を選ぶことで、最高の「生徒」を育成できる。NVIDIAは、数学や科学、コーディングといった論理的な推論能力において、現時点でDeepSeek R1が最高峰の性能を持つと判断したのだろう。自社の威信にこだわるよりも、最高の成果物をコミュニティに提供することで、結果的に自社のエコシステム(GPU、CUDA、NeMoフレームワークなど)の魅力を高めることができる。
第二に、これはオープンソースコミュニティへの強烈なアピールだ。GoogleやOpenAIといった競合が強力なモデルをクローズドなAPI経由で提供する中、NVIDIAは高性能な推論モデルそのものを無償で提供することで、世界中の才能ある開発者を自社のプラットフォームに引き寄せようとしている。これは、長期的に見てNVIDIA製GPUの需要を確固たるものにする上で極めて有効な戦略だ。
「知識蒸留」とは何か? 巨大AIを賢く小さくする錬金術
今回の発表を理解する上で欠かせないのが、「知識蒸留(Knowledge Distillation)」という技術だ。これは2015年に、後にノーベル物理学賞を受賞するGeoffrey Hinton氏を含むGoogleの研究者らによって提唱された概念である。
その発想は、AIモデルの「間違い方」に着目したものだった。例えば画像認識モデルが「犬」の画像を「猫」と間違えるのと、「自動車」と間違えるのでは、意味合いが全く違う。前者は似た動物であり、後者は全くの異物だ。Hinton氏らは、巨大な「教師」モデルが持つ、こうした正解以外の選択肢に対する確率的な出力(ソフトターゲット)にこそ、世界の構造を理解するための本質的な情報、「ダークナレッジ」が隠されていると考えた。
従来の学習が「この画像は犬である(100%)」という正解のみを教えるのに対し、知識蒸留では「犬である確率が60%、猫である確率が30%、狼である確率が9%…」といった、よりニュアンスに富んだ知識を「生徒」モデルに伝える。これにより、生徒は単に正解を暗記するのではなく、概念間の類似性や関係性をより深く、効率的に学習することができるのだ。
この技術は、巨大言語モデルBERTを小型軽量化した「DistilBERT」などで既にその有効性が証明されており、AIモデルのコスト削減と効率化に不可欠な手法として広く使われている。 NVIDIAは今回、この枯れた技術を最新・最強の推論モデルに適用し、その成果を世界に公開したのである。
OpenReasoning-Nemotronの実力:ベンチマークが示す驚異の性能
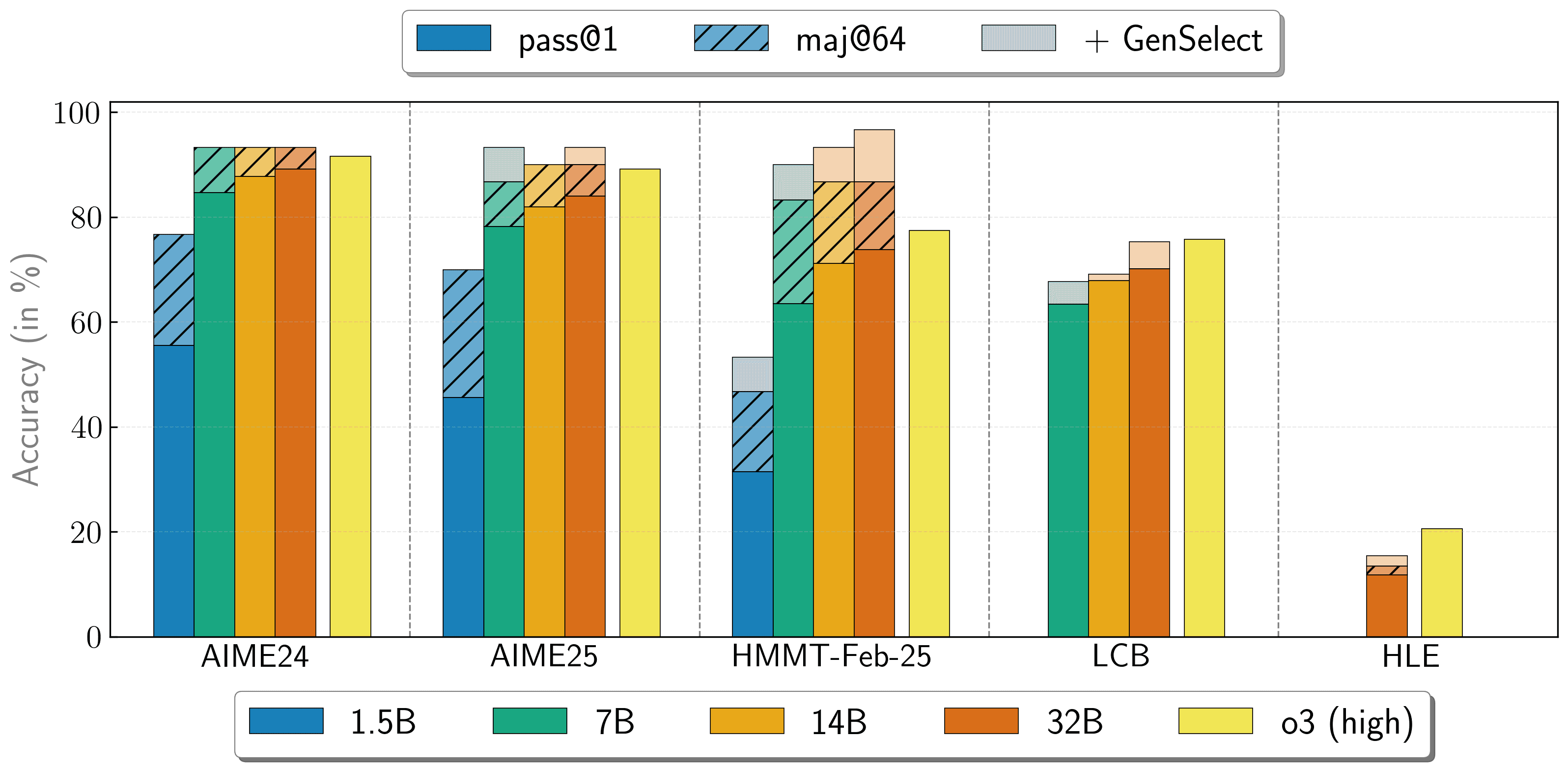
では、蒸留によって生まれた「生徒」たちの実力はどれほどのものか。NVIDIAが公開したベンチマークスコアは、その驚くべき性能を物語っている。
| モデル | パラメータ数 | AIME24 (数学) | HMMT Feb 25 (数学) | LiveCodeBench (コード) |
|---|---|---|---|---|
| Nemotron-1.5B | 15億 | 55.5 | 31.5 | 28.6 |
| Nemotron-7B | 70億 | 84.7 | 63.5 | 63.3 |
| Nemotron-14B | 140億 | 87.8 | 71.2 | 67.8 |
| Nemotron-32B | 320億 | 89.2 | 73.8 | 70.2 |
Source: NVIDIA Hugging Face Blog
特筆すべきは、最大の32Bモデルが、高度な数学オリンピックレベルの問題(AIME24)で89.2という高いスコアを叩き出している点だ。さらに、複数の回答を生成してその中から最も確からしいものを選択する「GenSelect」という手法を用いると、スコアはさらに向上し、一部のベンチマークではOpenAIの最高性能モデルである「o3-high」に匹敵、あるいはそれを超える性能を見せるという。
技術的に興味深いのは、これらのモデルが「教師ありファインチューニング(SFT)」のみで訓練され、強化学習(RL)が意TOO的に用いられていないことだ。 これは、純粋なデータ蒸留だけでどこまで性能を高められるかを示すと同時に、研究者たちに「クリーンな実験場」を提供することを意味する。このモデルをベースとして、様々な強化学習の手法を試すことで、推論AIの研究は大きく加速する可能性がある。
なぜDeepSeekか? AI業界の地政学と協調の兆し
NVIDIAが中国企業のモデルをベースにしたことは、米中間の技術覇権争いが激化する現代において、非常に示唆に富む動きだ。これは単なる技術的な選択にとどまらず、高度な政治的・戦略的判断があったと見るべきだろう。
考えられる一つの側面は、純粋にDeepSeek R1が数学や科学、コーディングといった分野の推論において、現在利用可能な最高の「教師」であったという事実だ。NVIDIAはイデオロギーよりも実利を取り、最高のツールを使って最高のオープンソースモデルを作る道を選んだ。
しかし、より深い視点で見れば、これはNVIDIAがグローバルなAIプラットフォーマーとしての地位を固めるための布石とも解釈できる。特定の国や企業に肩入れするのではなく、最高の技術であれば出自を問わず活用するというオープンな姿勢を示すことで、世界中の開発者からの信頼を勝ち得ようとしているのではないだろうか。これは、AI業界の分断を乗り越え、より普遍的なエコシステムを築こうとするNVIDIAの野心的な試みと言えるかもしれない。
開発者、そして我々にもたらされる恩恵
OpenReasoning-Nemotronの公開がもたらす最も大きなインパクトは、最先端の推論AIが、ごく一部の研究者や巨大企業の占有物ではなくなることだ。
これらのモデル、特に比較的小さなサイズ(1.5Bや7B)は、高性能なゲーミングPCに搭載されたGPUでもローカルに実行できる可能性がある。 これにより、開発者はクラウド利用料を気にすることなく、高度な推論能力を持つAIアプリケーションのプロトタイピングや研究を自由に進められるようになる。
企業にとっては、自社の特定のタスクに合わせてカスタマイズしたAIエージェントを構築するための、強力かつ低コストな基盤を手に入れたことになる。研究コミュニティは、推論能力の向上や効率化に関する研究を、かつてない規模とスピードで進めることができるだろう。
そして、この流れは最終的に我々一般ユーザーにも恩恵をもたらす。将来的には、スマートフォンやPC上で、クラウドに接続せずとも複雑な問いに答え、論理的な思考を助けてくれる、真にパーソナルなAIアシスタントが登場するかもしれない。
AIの「民主化」は新たなステージへ
NVIDIAによるOpenReasoning-Nemotronのリリースは、AIの歴史における一つの転換点として記憶されるかもしれない。それは、巨大化・高コスト化の一途をたどっていたAI開発のトレンドに、「知識蒸留」というエレガントな手法で一石を投じ、AIの能力をより多くの人々の手に解放する動きだからだ。
これは単に高性能なモデルがオープンソース化されたというニュースではない。AIの「知性」そのものが、よりアクセスしやすく、よりカスタマイズしやすく、そしてより安価になる時代の到来を告げている。このオープンな基盤の上で、世界中の開発者や研究者がどのような革新的なアプリケーションを生み出していくのだろうか。
Sources