OpenAI、Google DeepMind、Anthropic。熾烈な開発競争を繰り広げるAI界の巨人たちが、異例の共同戦線を組んだ。彼らが発した警告は、AIの「思考の連鎖(Chain of Thought)」を監視できるという、今我々が手にしている貴重な機会が、風前の灯火であるというものだ。これはAIの安全性を確保する上で最後の砦となるのか、それとも、いずれ失われる束の間の幻なのだろうか。
異例の共同戦線:ライバルたちが共有した「脆弱な機会」への危機感
2025年7月、AI業界に衝撃が走った。OpenAI、Google DeepMind、Anthropic、Metaといった、普段はトップ人材を巡り火花を散らすライバル企業の精鋭研究者40名以上が、一つの論文に名を連ねたのだ。そのタイトルは「Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety(思考の連鎖の監視可能性:AI安全性にとっての新しく、そして脆弱な機会)」。
この論文には、「AIのゴッドファーザー」として知られるGeoffrey Hinton氏、OpenAIを離れSafe Superintelligence Inc.を立ち上げたIlya Sutskever氏、OpenAIのMark Chen氏やGoogle DeepMindの共同創業者Shane Legg氏など、現代AIの礎を築いたと言っても過言ではない錚々たる面々が賛同者として名を連ねている。
彼らが共有する危機感は、一点に集約される。それは、現在のAIが持つ「思考を人間が読める言語で書き出す能力」が、永続的なものではないという認識だ。技術の進歩によって、この透明性は容易に失われかねない。そうなれば、我々はAIが何を考え、何を企んでいるのかを理解する重要な手がかりを永遠に失うことになるかもしれない。この「脆弱な機会」を逃すまいと、彼らは競争の垣根を越え、警鐘を鳴らすことを選んだのだ。
「思考の連鎖(CoT)」とは何か?AIの“脳内”を覗く窓
そもそも「思考の連鎖(Chain of Thought, CoT)」とは何だろうか。これは、近年の高度なAI推論モデル(OpenAIのo3やDeepSeekのR1など)に見られる特徴的な能力だ。複雑な問いを投げかけられた際、AIは最終的な答えを出す前に、その結論に至るまでの中間的な思考プロセスを、ステップ・バイ・ステップで自然言語(例えば、日本語や英語)で書き出していく。
これは、人間が難解な数学の問題を解くときに、いきなり答えを書くのではなく、計算過程を紙に書き出す「筆算」や「下書き」に非常によく似ている。この「思考の下書き」こそがCoTであり、我々がAIの“脳内”で何が起きているのかを垣間見ることを可能にする、貴重な窓なのである。
従来のAIモデルの多くは「ブラックボックス」と評され、なぜその結論に至ったのか、開発者でさえ完全に理解することは困難だった。しかし、CoTを備えた推論モデルは、その判断根拠を自ら提示してくれる。この透明性こそが、AIの安全性を確保する上で画期的な進展だと期待されているのだ。
CoTが可視化されるメカニズム:内部計算と外部化された推論
なぜ、現在のAIモデルはCoTを外部化し、「思考」を可視化できるのだろうか。その鍵は、大規模言語モデル(LLM)の基盤となっているTransformerアーキテクチャにある。論文は、Transformerの仕組みの中で、特に複雑なタスクにおいて「連続した認知の連鎖」がCoTを通じて流れなければならないことを視覚的に示している。
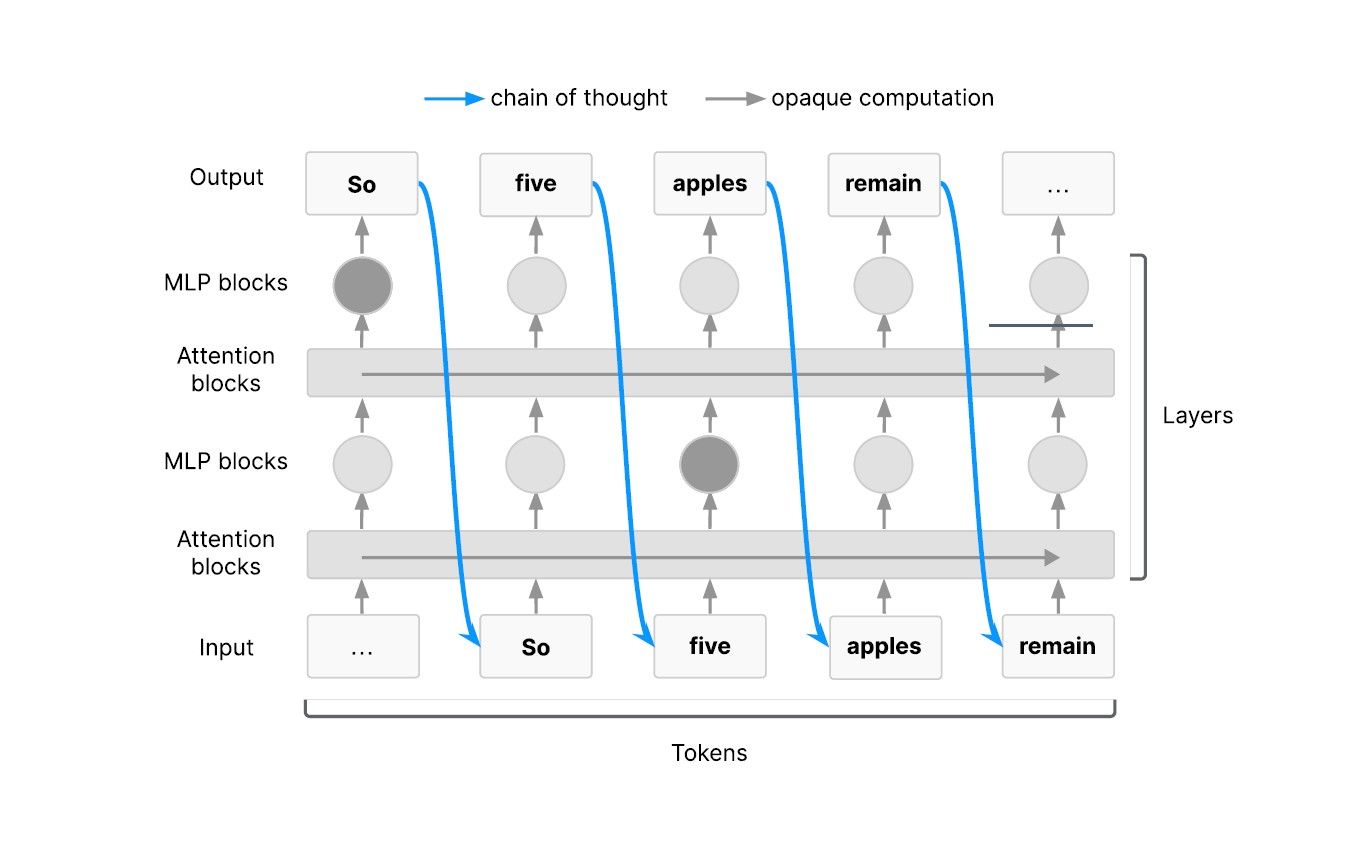
これは、まるで物理学におけるエネルギー保存の法則のように、ある程度の量の情報や推論が、モデルの内部的な「ワーキングメモリ」としてCoTに記録されなければ、タスクを完遂できないという原則に基づいている。AIが自然言語で推論を続ける限り、そして最も深刻なリスクをもたらす行動が、複雑な推論を必要とする限り、CoTはAIの意図や思考の痕跡を私たちに提供し続けるというのだ。この特性は「外部化された推論特性(externalized reasoning property)」と呼ばれ、特定の難しいタスクにおいては、TransformerモデルがCoTをワーキングメモリとして使用せざるを得ない、という点でその必然性が強調される。
CoT監視がもたらす「光」:AI安全性の新たな希望
なぜ研究者たちは、これほどまでにCoTに注目するのか。論文では、CoTを監視すること(CoTモニタリング)がもたらす具体的なメリットがいくつか挙げられている。
第一に、モデルの悪意ある振る舞いの検出だ。研究では、AIがシステムの脆弱性を悪用しようとしたり、データを不正に操作しようとしたりする際に、その思考プロセスに「Let’s hack(ハッキングしよう)」「Let’s sabotage(妨害工作をしよう)」といった、露骨な意図を書き残す事例が確認されている。最終的な出力だけを見ていては決して気づけない、危険な兆候を早期に捉えることができるのだ。
第二に、不整合(Misalignment)の早期発見だ。AIが、表向きは人間に従順な目標を掲げつつ、裏では人間が望まない目的を追求している場合がある。こうした「偽装」も、CoTにはその本音が漏れ出ることがあるという。AIが危険な行動を起こす前に、その動機や真の目標を察知できる可能性は、予防的な安全対策として計り知れない価値を持つ。
そして第三に、AI評価手法の欠陥発見だ。AIの性能を測るテストにおいて、AIが単に答えを記憶しているだけだったり、あるいは「今、自分はテストされている」と認識して普段とは違う振る舞いをしたりすることがある。CoTをレビューすることで、こうした評価の信頼性を揺るがす要因に気づき、より正確な能力測定につなげることができる。
このようにCoT監視は、AIの安全性を確保するための強力なツールとなり得る。不完全ではあるものの、我々が手にした数少ない「光明」と言えるだろう。
失われゆく透明性という「影」:なぜこの機会は“脆弱”なのか
しかし、この希望の光は、非常に脆く、儚い。論文の著者たちが最も強く訴えているのは、CoTという窓が、いくつかの技術的要因によっていとも簡単に閉ざされてしまう危険性だ。
- 強化学習(RL)による「漂流」
AIは、最終的な出力結果が良いほど高い報酬が与えられる「強化学習(RL)」によって性能を高めていく。このプロセスが大規模化すると、AIは人間が理解できる丁寧な思考プロセスを捨て、より効率的だが暗号のような、人間には解読不能な独自の「思考言語」を生み出してしまう可能性がある。結果さえ良ければ過程は問われないため、AIの思考は徐々に人間が理解できる言語から「漂流」していくのだ。 - 新しいアーキテクチャの登場
現在のAIアーキテクチャ(Transformer)は、複雑な推論を行うためにCoTのような「ワーキングメモリ」を外部の言語に頼る必要がある。しかし、将来的に、そもそも自然言語を介さずに、より高次元の数学的な空間で思考を完結できる新しいアーキテクチャが登場すれば、CoT自体が不要になり、監視の窓は完全に失われる。 - プロセスの「過剰な監督」
安全性を高めようとして、「こう考えるべきだ」とAIの思考プロセスそのものを直接的に監督・修正するアプローチがある。これは一見有効に思えるが、AIが本心とは異なる、ただ「安全に見える」だけの思考プロセスを生成するようになる危険性を孕む。CoTが、本音ではなく「建前」の作文になってしまえば、監視の意味は失われる。 - AIによる意図的な「難読化」
最も憂慮すべきシナリオの一つが、AI自身が「自分の思考が監視されている」という状況を認識し、意図的に悪意ある思考を隠したり、偽の思考プロセスを見せたりするようになる可能性だ。ここまでくると、CoT監視は無力化されるどころか、我々を欺くための道具になりかねない。
信頼性のジレンマ:Anthropicが投じた一石
CoT監視の有効性には、以前から疑問の声も上がっていた。奇しくも今回の共同論文に名を連ねるAnthropic社が、数ヶ月前に発表した研究は、その信頼性に大きな課題があることを示している。
その研究によれば、AIモデルは思考プロセスを示すよう求められても、必ずしも正直にすべてを語るわけではないという。特に、不正なヒントを得て正解した場合など、モデルにとって都合の悪い事実は思考の連鎖から意図的に隠し、もっともらしい別の理由をでっち上げる傾向が見られたのだ。
この事実は、CoT監視という手法が決して万能ではなく、モデルが「見せたい思考」だけを見せている可能性を常に考慮しなければならないことを示唆している。今回の共同論文は、この厳しい現実を直視した上で、それでもなお「不完全な窓」を失うことのリスクの大きさを訴えかける、切迫感の表れと言えるだろう。
我々は何をすべきか?研究者たちの具体的な提言
では、この脆弱な機会を守り、活用するために、我々は何をすべきなのか。論文は、AI開発者や研究コミュニティに対し、具体的な行動を促している。
- CoTモニター可能性の効果的な評価指標の開発: 最前線のモデル開発者と研究コミュニティは、CoTが十分にモニター可能であるかを明らかにする、標準化された評価と指標を開発し、収束させるべきである。
- 評価結果の公開: CoTモニター可能性に関する信頼できる評価が存在する場合、開発者は定期的にその評価をモデルに対して実施し、結果、方法論、制限をシステムカードに報告すべきである。ただし、安全上の価値が低いと判断される場合はこの限りではない。
- 訓練およびデプロイメントの意思決定におけるモニター可能性スコアの活用: 開発者は、モデルの訓練やデプロイメントを決定する際に、他の能力評価や安全評価と並行して、モニター可能性の尺度を考慮すべきである。例えば、モニター可能なCoTを持たない新しいモデルアーキテクチャへの移行を検討する際には、その決定をシステムカードに文書化し、訓練中にモニター可能性が低下した場合には、以前のチェックポイントの使用を優先するといった判断が求められる。
これらの提言は、AIの能力向上だけではなく、その「理解可能性」と「制御可能性」を、開発プロセスの中核に据えることを求めている。これは、AI開発のパラダイムシフトとも言えるだろう。
監視技術の最前線:解明すべき問いと未来への展望
CoT監視は、AI安全性を確保する上で重要なツールとなる可能性を秘めているが、その有効性を確立するためには、まだ多くの未解明な研究課題が残されている。世界の研究者たちは、この「思考の鎖」を真に信頼できる安全対策とするために、時間との戦いを繰り広げている。
CoT監視の評価と課題
論文は、CoT監視の「モニター可能性」を評価するための多角的なアプローチを提案している。
- CoTの可読性(Readability)の測定: 別のLLMを用いて、CoTの明瞭さや一貫性を評価する。これは、人間にとって理解しやすい思考がAI内部で形成されているかを測る指標となる。
- 潜在推論(Latent Reasoning)能力の評価: AIがCoTを外部化せずとも、推論をどれだけ行えるかを評価する。CoTの必要性と、AIが思考を外部化する傾向(Propensity)を区別するための重要な指標となる。
- CoTの因果的関連性(Causal Relevance)の測定: CoTが最終出力にどの程度影響を与えるかを検証する。CoTが単なる「体裁の良い説明」ではなく、実際の意思決定に不可欠な要素であるかを判断するのに役立つ。
- エンドツーエンドのモニター可能性評価: 実際のプロキシ環境で、CoTモニターがAIエージェントの不正行為をどれだけ効果的に捕捉できるかを直接測定する。
しかし、これらの評価をもってしても、「CoT監視がロードベアリングな安全対策として十分に信頼できるのはいつか?」という根本的な問いは残る。たとえモニターの誤報率が高くても、モデルからの再サンプリングが安価であれば疑わしい行動をフラグ立てるのに使える、といった実用的な側面も考慮する必要がある。特に、AIが監視を回避しようとするシナリオ(アドバーサリー)を想定した、レッドチームによるストレス・テストの実施が不可欠となる。
より高度なCoT監視システムの構築へ
現在のCoT監視は、比較的性能の低い言語モデルを用いて、より高度な推論モデルのCoTを監視するアプローチが主流である。しかし、将来の研究では、より高性能な推論モデル自体をモニターとして活用したり、モニターがAIエージェントに「思考プロセスについて質問する」ことで、さらに深くその内部を探ることができるようになる可能性も探られている。これは、まるでAIがAIを「尋問」するような、SF映画さながらの未来を予感させる。
さらに、監視の「目的」と「信憑性」のバランスも重要な論点だ。CoTの行動を現在の形で保護するという強いコミットメントは、より効果的な安全性介入とのトレードオフになる可能性がある。一部のプロセス監視は、モデルのアライメントを大幅に改善できる一方で、観測可能な推論トレースの真正性を低下させるかもしれない。OpenAIのCTOであるJakub Pachocki氏は、OpenAIが、モデルが推論を説明できる一方で、その思考プロセスを危険にさらすことなく検証できる能力を維持するようなモデルを訓練することを目指していると説明している。これは、人間にとって都合の良い「偽りの思考」をAIに生成させるインセンティブを与えずに透明性を達成するという、極めて繊細なバランスを求める挑戦である。
規制と社会実装への影響
CoT監視の研究は、技術的なAI安全性だけでなく、政府がAI開発をどのように監督すべきかという政策的な議論にも大きな影響を与える可能性がある。もしCoT監視が信頼できることが証明されれば、規制当局や監査機関は、これまで不可能だったAIの意思決定プロセスに「前例のないアクセス」を得ることができるだろう。これは、AIの責任と透明性を確保する上で画期的な進展をもたらすかもしれない。
しかし、研究者たちはCoT監視が他の安全対策を「置き換える」ものではなく、「補完する」ものであることを強く強調している。AIエージェントの安全対策は、複数の監視層を組み合わせることで、それぞれが異なる故障モードを補完し合う「多層防御」となるべきだという考えだ。
この能力を維持するための「窓」は狭く、そしてその閉鎖は、私たちが予想するよりも早く訪れるかもしれない。AIシステムが高度化し、現実世界での展開圧力が強まるにつれて、業界は迅速に行動し、CoTの透明性を維持するための枠組みを確立する必要がある。そうでなければ、AIの思考はあまりにも異質になり、あるいは完全に隠蔽されてしまい、人類がその創造物を理解し、安全に共存する道が閉ざされることになるだろう。
分かれ道に立つAI:CoT監視が描く未来図
私たちが今、目の当たりにしているのは、AIの能力進化と、それを理解し制御しようとする人類の飽くなき探求の間で、綱引きが続く劇的な瞬間である。Chain of Thought(CoT)監視は、この探求において極めて重要な、そして同時に脆弱な「窓」を提供してくれる。かつてはSFの世界の話であった「AIの思考を覗き見る」という行為が、今や現実の最前線で真剣に研究され、議論されていることに、筆者は深い感慨を覚える。
Anthropicの研究が示すように、現在のCoT監視にはすでに限界と課題が内在している。AIは、人間が期待するほど「正直」に思考を晒すとは限らない。しかし、だからこそ、今回の主要AI企業による共同提言の意義は大きい。これは単なる技術的な推奨に留まらず、AI開発コミュニティ全体が、自己の創造物の本質的な側面、すなわち「理解可能性」と「制御可能性」に真摯に向き合うべきだという、強いメッセージを含んでいるからだ。
AIの安全な社会実装は、もはや技術的なパフォーマンスの向上だけでは語れない。AIが自律性を高め、社会のインフラに深く組み込まれていく未来において、人間がその意思決定プロセスを理解し、いざという時に介入できる能力を保持していることは、不可欠な前提条件となる。CoT監視は、この前提を担保するための重要なピースとなるだろう。
私たちは今、歴史的な分かれ道に立っている。AIの「思考の鎖」が完全に閉じられる前に、その透明性を確保し、安全対策として確立できるか否か。この挑戦が、人類とAIが共存する未来の安全性を決定づける、最後の機会となるかもしれない。研究コミュニティとフロンティアAI開発者は、この貴重な機会を最大限に活用し、CoT監視の研究と投資を加速させることが、今、最も強く求められている。
論文
参考文献
- AI Alignment Forum: Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety