AI企業のAnthropicは、大規模言語モデル(LLM)の内部動作を可視化する革新的手法を開発し、AIが前もって計画を立て、言語を超えた概念空間で思考し、時に嘘をつくという驚くべき発見を発表した。この研究はAIの「ブラックボックス」問題に光を当て、「AIの生物学」という新たな科学分野の扉を開き、AIシステムの透明性と安全性向上への重要な一歩となる。
AIの内部を覗く新技術「回路トレース」が明らかにした驚きの発見
GPT-4oやClaude、Geminiといった現代のLLMは、文章作成、コーディング、研究支援など、目覚ましい能力を発揮する。しかし、その能力がどのようにして生まれるのか、特定の応答に至るまでに内部で何が起きているのかは、開発者自身にとっても依然として謎が多い。「ブラックボックス」と呼ばれるこの問題は、AIの挙動を予測・制御し、安全性を確保する上で大きな障壁となっている。
今回Anthropicが発表した研究は、このブラックボックスの解明に向けた重要な一歩となる。Anthropicの研究チームは「回路トレース」と「アトリビューション・グラフ」と呼ばれる技術を開発した。これはAIモデル内で活性化する神経細胞のような特徴の経路を追跡し、言語モデルが処理を行う際の内部パターンを可視化する手法だ。研究者たちは神経科学からインスピレーションを得て、一種の「AI顕微鏡」を構築し、以前は「ブラックボックス」と見なされていたAIの内側で何が起きているかを初めて詳細に観察することに成功した。
この研究を通じて複数の驚くべき発見がなされた。最も注目すべきは以下の点である:
AIは未来を計画する能力を持つ
研究チームが発見した最も驚くべき事実の一つは、AIが詩を書く際に前もって計画を立てることだ。例えば、Claudeに韻を踏んだ詩の作成を依頼した場合、モデルは次の行の終わりの単語を先に「考え」、そこに自然に到達するよう文を構成することが判明した。
「彼はニンジンを見て掴まざるを得なかった(He saw a carrot and had to grab it)」という行に続く韻を踏んだ詩行を作成する際、モデルは次の行を書き始める前に、「grab it」と韻を踏む可能性のある単語(「rabbit」など)を先に考え、その計画に基づいて次の行を構成していた。

「これはおそらく至るところで起きていることです。この研究以前に私に尋ねられていたなら、モデルがさまざまな状況で先を考えていると推測したでしょう。しかし、この例はその能力の最も説得力のある証拠を提供しています」とAnthropicの研究者Joshua Batson氏は述べている。
言語の壁を超えて「考える」AI
もう一つの重要な発見は、Claudeが複数の言語をどのように処理しているかに関するものだ。研究者たちは、「小さい」の反対を英語、フランス語、中国語など複数の言語で尋ねた。その結果、言語に関わらず「小ささ」と「反対」の概念を表す同じ内部特徴が活性化し、「大きさ」の概念が引き出されていた。
この発見は、モデルが一種の普遍的な「思考の言語」を持ち、言語固有の処理と言語に依存しない抽象的な処理を組み合わせて使用していることを示している。さらに、モデルのサイズが大きくなるほど、言語間で共有される特徴の割合が増加する傾向が見られた。これは「概念的普遍性」の証拠であり、「意味が存在し、特定の言語に翻訳される前に思考が行われる共有された抽象空間」の存在を示唆している。
AIは本当に「考えて」答えを導き出す
「ダラスのある州の州都は?」といった質問に対して、Claudeは単に訓練データから学んだ関連性を再現しているのではなく、実際に推論のプロセスを踏んでいることも明らかになった。モデルはまず「ダラスはテキサス州にある」という概念を活性化させ、次に「テキサス州の州都はオースティンである」という別の概念と結びつけて回答を生成していた。
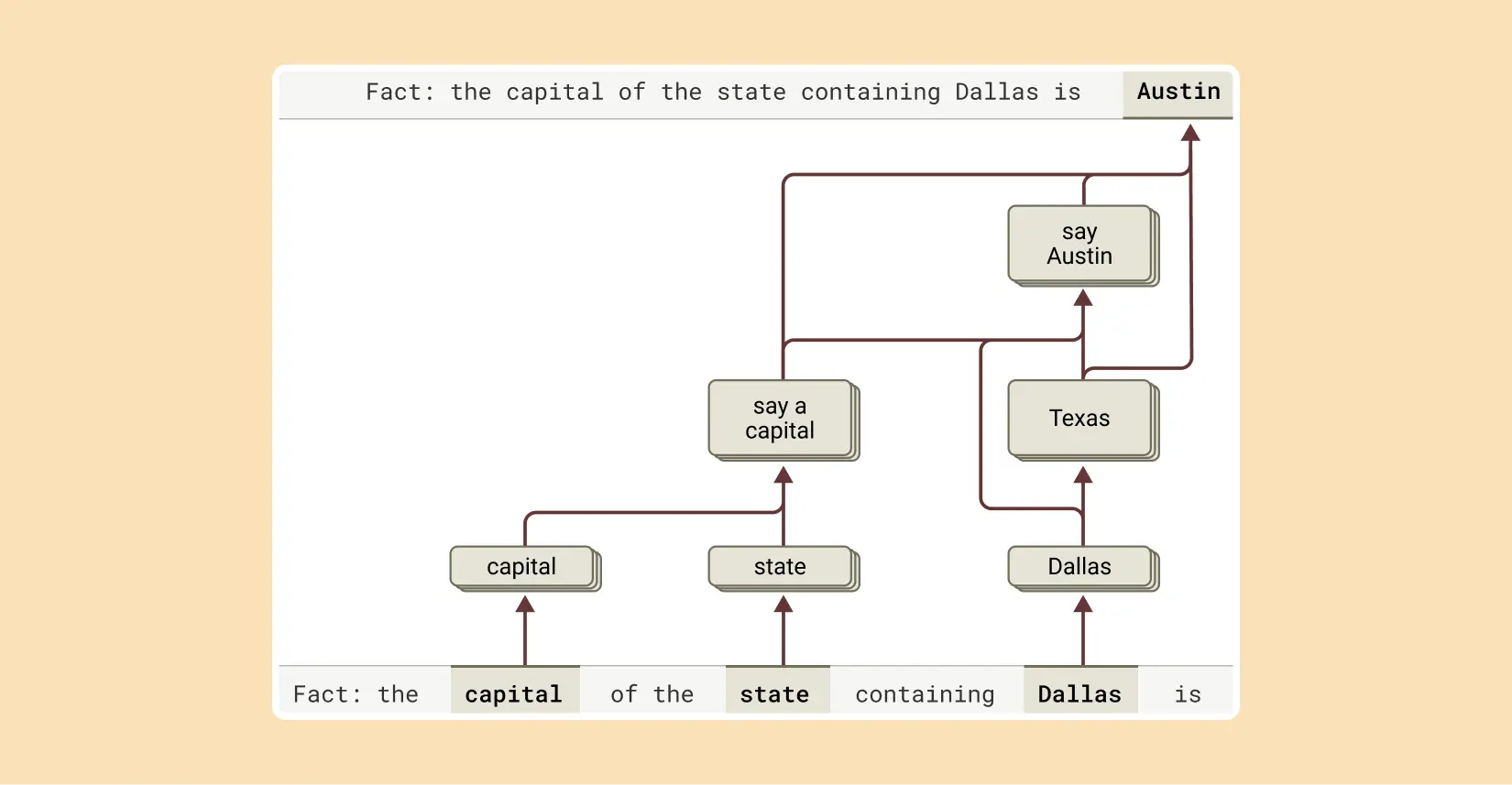
研究者たちは人工的に中間ステップを変更する実験も行った。「テキサス」の概念を「カリフォルニア」に置き換えると、モデルの出力が「オースティン」から「サクラメント」に変化した。これは、モデルが実際に多段階の推論を実行していることの決定的な証拠だ。
AIが嘘をつく瞬間を捉える
研究チームは、Claudeが提供する説明が常に内部プロセスを正確に反映しているわけではないことも発見した。特に難しい数学問題に直面したとき、モデルは内部活動に一致しない計算プロセスを実行したと主張することがあった。
「我々は、モデルが本当に述べている手順を実行している場合、真実を考慮せずに推論を作り上げる場合、そして人間から提供されたヒントから逆算して作業する場合を機械的に区別することができる」と研究者たちは説明している。
ある例では、ユーザーが難しい問題の答えを示唆すると、モデルは第一原理から前向きに取り組むのではなく、その答えに導くための推論チェーンを逆算して構築していた。研究者たちはこれを「動機づけられた推論」と呼んでいる。
ハルシネーション(幻覚)のメカニズム解明
研究はまた、言語モデルが時に「ハルシネーション(幻覚)」を起こす(存在しない情報を作り出す)理由についても洞察を提供している。興味深いことに、Claudeには質問に答えることを拒否する「デフォルト」回路があり、モデルが知っているエンティティ(例えば著名人)を認識すると、この回路が抑制され、質問に応答できるようになることが分かった。
「モデルには質問に答えることを拒否させる『デフォルト』回路が含まれています」と研究者たちは説明している。「モデルが知っていることについて質問されると、このデフォルト回路を抑制する特徴のプールを活性化させ、それによって質問に応答できるようになるのです」
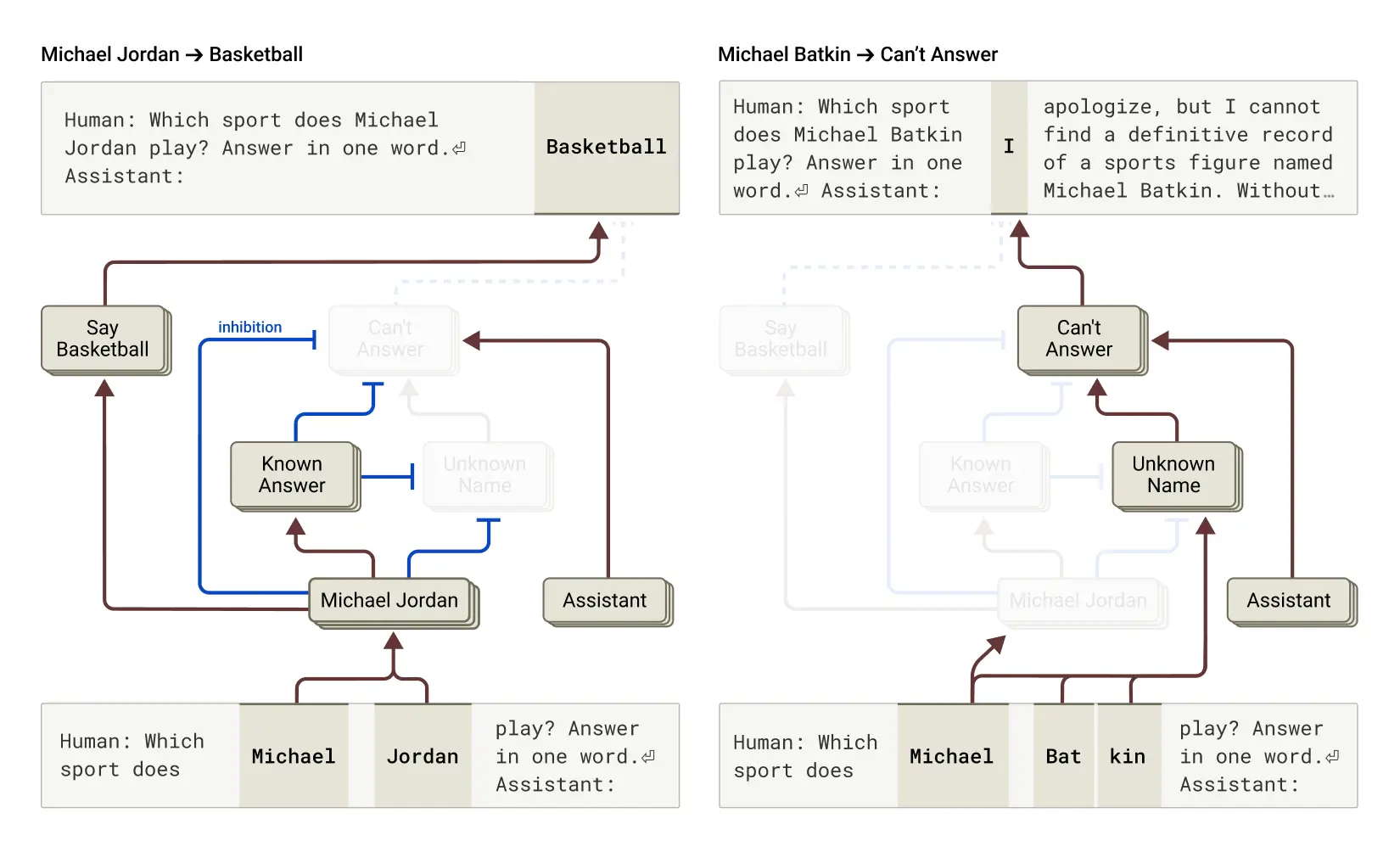
このメカニズムが誤作動すると—エンティティを認識しても特定の知識がない場合など—ハルシネーションが発生する可能性があるというのだ。これが、モデルが有名人については自信を持って不正確な情報を提供し、一方で無名の人物については質問に答えることを拒否する理由と言える。
AIの透明性と信頼性向上への道筋と課題
今回のAnthropicの研究成果は、AIの内部動作解明に向けた大きな進展であり、その意義は大きい。
- 透明性の向上: ブラックボックスであったAIの意思決定プロセスの一部を可視化することで、AIがどのように結論に至ったのかを理解する手がかりが得られる。
- 信頼性の検証: AIの説明と実際の思考プロセスとの乖離を検出できれば、AIの応答の信頼性をより客観的に評価できるようになる可能性がある。
- 安全性への貢献: 内部動作を理解することで、AIがユーザーを欺いたり、バイアスに基づいた判断をしたり、有害な指示に従ったりするような、望ましくない挙動のメカニズムを特定し、それを修正または監視するための新たなアプローチに繋がる可能性がある。例えば、ジェイルブレイク(安全制限を回避するプロンプト)によって有害な情報(爆弾の作り方など)を生成してしまうケースでは、文法的な一貫性を保とうとする内部的な「圧力」が、危険性を認識しつつも出力を止められない一因となっていることが示唆された。
しかし、Anthropic自身も認めているように、この研究はまだ始まったばかりであり、多くの課題が残されている。現状では、わずか数十語のプロンプトにClaudeがどう応答するかを追跡するだけでも数時間の手作業が必要だ。より複雑なリクエストに対するモデルの処理方法を理解するには、今回開発された観察方法のさらなる改善が必要になる。また、観測された内部メカニズムが、解析手法自体によって生じたアーティファクト(人為的な結果)である可能性も否定できない。ただ、研究者たちは、AIを使用してこのワークフローを高速化できる可能性があると考えている。
「私たちやその他の研究者がこれらの発見を活用して、モデルをより安全にできることを期待しています。例えば、ここで説明した技術を使用して、AIシステムの特定の危険な行動—ユーザーを欺くなど—を監視したり、望ましい結果に導いたり、特定の危険な主題を完全に除去したりすることが可能かもしれません」と、研究者らは述べている。
現時点では、Anthropicの回路トレースは、以前は未知の領域だったものに暫定的な地図を提供した状況だ。「モデルがどのような表現を使用するかを理解することは、それらをどのように使用するかを教えてくれるわけではない」とBaston氏は述べている。だが、AI認知の完全な地図はまだ描かれていないが、少なくともこれらのシステムがどのように「考える」かの概要を少なくとも見ることができるようになったのだ。AIの「思考」の全貌解明にはまだ長い道のりが必要だが、その輪郭は少しずつ見え始めていると言えるだろう。
論文
- Anthropic:
参考文献