
生成AIの進化は止まることを知らない。GPT-4の登場以降、我々はAIがコーディングを行い、詩を書き、司法試験に合格する様を目撃してきた。しかし、人類の知性の最前線である「科学的発見」の領域において、最新のAIモデルは本当に通用するのだろうか?
2025年11月、世界中の物理学者たちが突きつけた現実は、冷徹かつ極めて興味深いものだった。
新たなベンチマークテスト「CritPt」を用いた検証により、Googleの最新鋭モデル「Gemini 3 Pro」やOpenAIの「GPT-5」であっても、博士課程初期レベルの物理学研究タスクにおいては、その正答率がわずか10%前後にとどまることが明らかになったのだ。
「CritPt」:AIの“暗記”を許さない、物理学者たちの挑戦状
なぜ既存のベンチマークでは不十分だったのか。それは、多くのLLM(大規模言語モデル)が、インターネット上の膨大なテキストデータを学習しており、既知の問題であれば「推論」ではなく「検索(記憶の呼び出し)」によって回答できてしまうからだ。
これに対抗するため、30以上の研究機関から集まった50名以上の物理学者たちが開発したのが「CritPt(Complex Research using Integrated Thinking – Physics Test)」である。
検索不可能な「未発表」の問題
CritPtの最大の特徴は、収録されている71の完全な研究課題(Challenge)と190のチェックポイントが、すべて未発表の研究に基づいている点にある。
これは教科書の練習問題ではない。量子力学、宇宙物理学、高エネルギー物理学、物性物理学など11の分野にまたがり、実際に大学院生が新規の研究プロジェクトとして取り組むような、「答えがネットのどこにもない」課題群だ。
これにより、AIは学習データの記憶に頼ることができず、純粋な「推論能力」と「洞察力」だけで未知の解を導き出さなければならない。まさにAIの真価を問うリトマス試験紙である。
惨憺たる結果:SOTAモデルたちの敗北
検証の結果は、現在のAIブームに冷水を浴びせるような厳しいものであった。
Gemini 3 ProとGPT-5のスコア
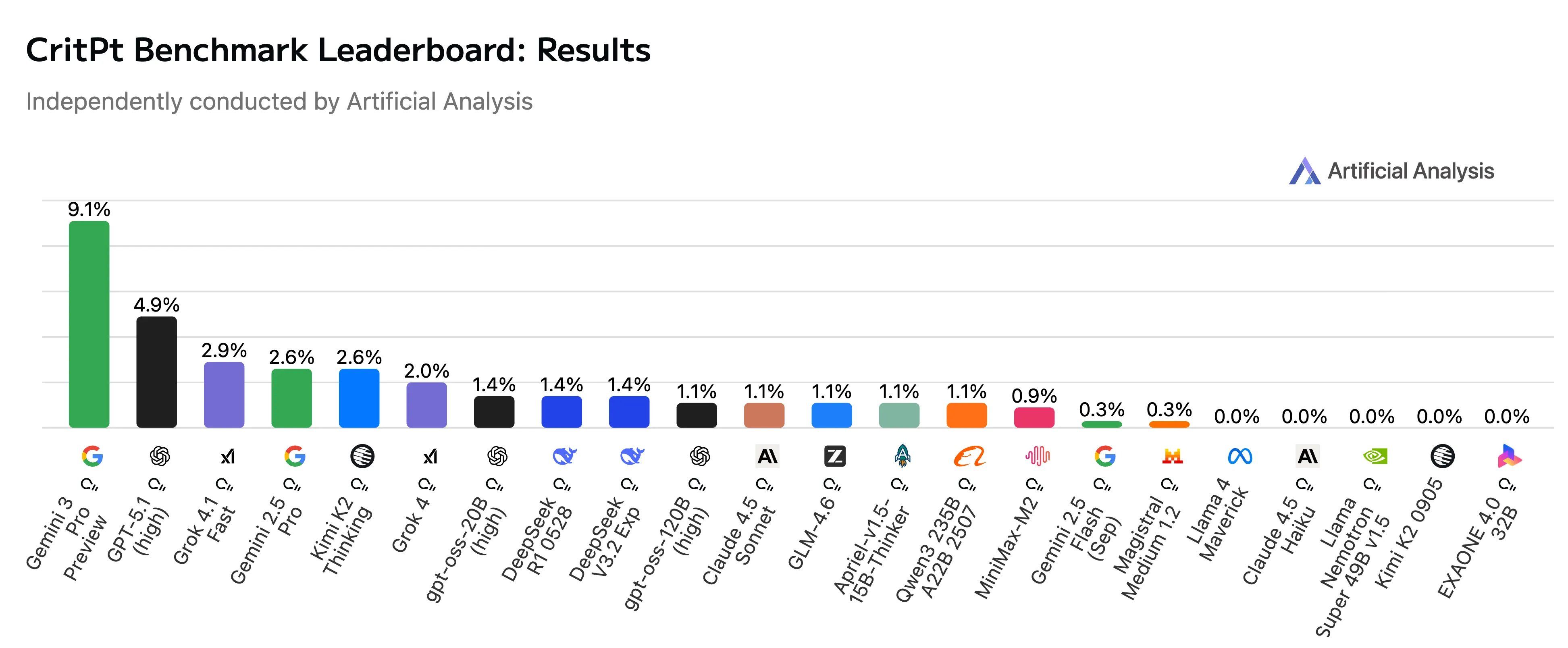
Artificial Analysisによる独立評価、そして論文データの統合的な分析によると、主要モデルのパフォーマンスは以下の通り低迷している。
- Gemini 3 Pro Preview: Googleの最新モデルでさえ、正答率は9.1%にとどまった。
- GPT-5.1 (high): OpenAIの次世代モデルも、独立評価では4.9%という結果に終わっている(論文内のGPT-5 (high) + Code Interpreter + Web Searchの最高構成でも12.6%)。
- ベースモデルの限界: 外部ツール(Pythonコード実行やWeb検索)を持たない「素の」モデル(Base Models)に至っては、正答率はほぼ0%〜2%という壊滅的な数値を示した。
「まぐれ当たり」すら許されない厳格さ
さらに衝撃的なのは、信頼性(Reliability)の欠如だ。研究チームは「Consistently Solved Rate(一貫した解決率)」という指標を導入した。これは「5回試行して4回以上正解できるか」を問うものだ。
科学研究において、計算するたびに答えが変わるようでは使い物にならない。この厳しい基準を適用した結果、ほとんどのモデルのスコアはほぼゼロに張り付いた。 唯一、GPT-5 (high) がツールをフル活用した場合にのみ、辛うじて約10%の課題を一貫して解くことができた。
なぜAIは「物理学」でつまずくのか?
なぜ、司法試験や数学オリンピックの問題を解けるAIが、物理学の研究タスクではこれほどまでに無力なのか。その背景には、物理学という学問特有の構造的要因がある。
1. 「推論の深さ」と「脆さ」
CritPtが求めるタスクは、単なる数式の操作ではない。物理的なシナリオを理解し、適切な仮定を置き、複数のステップを経て論理を構築する必要がある。
LLMは確率的に次のトークンを予測する仕組みであるため、推論のステップが長くなればなるほど、どこか一箇所で微細なエラー(幻覚)を起こす確率が指数関数的に高まる。物理学において、途中の符号一つ、係数一つの誤りは、最終的な結論の全否定を意味する。自然言語のタスクとは異なり、「なんとなく合っている」は「間違い」と同義なのだ。
2. 未知の領域への適応力不足
既存のモデルは、学習データにあるパターンを組み合わせること(Interpolation)には長けているが、既知の知識を統合して全く新しい文脈に適用する「創造的な推論(Extrapolation)」は依然として苦手としている。CritPtの問題は、まさにこの「既知の知識の境界線」にある問題を扱っているため、AIの弱点が露骨に現れた形だ。
3. 「確率」と「厳密性」のミスマッチ
論文の分析によると、AIモデルはしばしば「もっともらしいが間違っている」回答を自信満々に出力する。専門家がその誤りを見抜くには、AIが回答を作成する以上の時間を要する場合がある。これは「研究の効率化」どころか、誤情報による混乱という新たなコストを生む。
希望の光:「AI科学者」ではなく「AI研究助手」へ
しかし、この結果はAIが科学研究に無用であることを意味しない。むしろ、「AIをどう使うべきか」という現実的な解を提示している。
Checkpoint(部分タスク)での有用性
フルスケールの研究課題では失敗したが、それを細分化した「部分タスク」においては、AIは比較的良好なパフォーマンスを示している。
例えば、特定の数式の導出や、条件が限定されたシミュレーションコードの作成といった、スコープが明確なタスクであれば、GPT-5などの上位モデルは20%〜25%程度の成功率を示した(ツール併用時)。
これは、AIに「論文を一本丸ごと書かせる」ことは不可能でも、「計算の一部を任せる」「アイデアの壁打ち相手にする」といった「研究インターン」としての利用価値は十分にあることを示唆している。
OpenAIのロードマップとの整合性
興味深いことに、この結果はOpenAIが描く長期戦略とも合致している。OpenAIは、2026年9月までに「研究インターン」レベルのシステムを、そして2028年までに完全な「自律型研究者」を実現するという目標を掲げている。
現状のCritPtの結果は、まさに「インターンとしてもまだ未熟だが、ポテンシャルはある」という現在地を正確に映し出していると言えるだろう。
今後の展望とビジネス・産業への影響
CritPtベンチマークの登場と、そこでのAIの苦戦は、今後のAI開発と産業応用にどのような意味を持つのか。
1. 「推論コスト」の増大と選別
より高度な推論(Reasoning)を行うには、モデルは膨大な計算リソース(トークン)を消費する。今回のテストでも、推論特化型モデルは汎用モデルに比べて桁違いのトークンを消費した。
これは、企業がAIを導入する際、「単に賢いモデル」を選ぶのではなく、タスクの難易度に応じたコスト対効果をシビアに見極める必要があることを示唆している。高度な科学計算には、それ相応の「高価な」推論が必要になる。
2. 「Human-in-the-Loop」の重要性の再確認
少なくとも今後数年間、AIは自律的な発見者にはなり得ない。重要なのは、AIの出力を検証し、正しい方向へ導く人間の専門家の存在だ。ITや製薬、材料科学の分野において、AIは研究者を「置換」するのではなく、研究者の能力を「拡張」するツールとして進化するだろう。
3. 新たな競争軸:専門特化型AI
汎用LLMの限界が見えたことで、今後は物理学、化学、生物学など、各ドメインに特化したファインチューニングや、記号処理(数式処理)に特化したニューロシンボリックAIのアプローチが再評価される可能性がある。
AIは「クリティカル・ポイント(臨界点)」を超えられるか
ベンチマーク名「CritPt」は、物理学用語の「Critical Point(臨界点)」に由来する。物質の相が劇的に変化する境界点だ。
現在のAIは、表面的なパターンの模倣から、真の理性的推論へと移行する「臨界点」の手前でもがいている。Gemini 3 ProやGPT-5の結果は、その壁がいかに高く、厚いかを示した。しかし同時に、コード実行やWeb検索といったツールを武器に、その壁を登ろうとする確かな足跡も見えている。
我々は今、AIが単なる「検索エンジン」や「チャットボット」を超え、真の意味で人類の知を拡張するパートナーへと進化できるかどうかの、歴史的な分岐点を目撃しているのである。
論文
参考文献


