
現代のサイバーセキュリティは、暗闇の中で微かな足音を聞き分ける終わりのない神経戦である。企業のエンドポイントやクラウド環境からは、毎日ペタバイト級のテレメトリデータが生成されている。しかし、その大多数は無害な日常のノイズに過ぎない。防御側であるセキュリティチームの真の目的は、その膨大な砂漠の中から、高度な隠蔽工作を施された国家支援型ハッカーやランサムウェアグループの「悪意ある足跡」という一粒の砂金を発見することにある。
この砂金を見つけ出すためのフィルター、すなわち検知ルールを構築し検証する作業は、長らく泥臭く物理的な制約に縛られてきた。新たな攻撃手法が発見されるたびに、エンジニアは隔離されたラボ環境を構築し、実際のマルウェアを動作させ、そこから漏れ出るログを収集するという危険で労力のかかるプロセスを繰り返してきたのだ。実環境における本物の攻撃データは極めて稀少であり、プライバシーや機密情報の壁に阻まれて組織間で共有することも難しい。
この絶望的な非対称性を覆すべく、Microsoft Defender Security Research Teamがひとつのブレイクスルーを提示した。彼らはマルウェアそのものを動作させるのではなく、攻撃者がシステム上に残す影(ログやプロセスツリー)だけを、大規模言語モデルを用いて人工的に合成する手法を開発した。これはウイルスそのものではなく、免疫系を訓練するための極めて精巧な不活化ワクチンをオンデマンドで大量生産する技術に等しい。本稿では、この合成攻撃ログ生成アーキテクチャの全貌と、それがセキュリティ業界の構造に与える影響を解き明かす。
ログという名の砂漠。ラボ環境に縛られた検知エンジニアリングの限界
既存のサイバー防衛体制が抱える最大のボトルネックは、攻撃テレメトリの圧倒的なデータ不足にある。SIEMやEDRなどのソリューションは、エンドポイントからプロセスの挙動やシステム改ざんの記録を絶え間なく吸い上げている。しかし、異常検知モデルを訓練したり精緻なシグネチャを作成したりするためには、質の高い悪意あるデータが不可欠である。
現状のセキュリティオペレーションセンターのエンジニアたちは、MITRE ATT&CKフレームワークに定義された攻撃者の戦術・技術・手順をベースに検知ルールを手作業でコーディングしている。そのルールが正しく機能するかを確かめるには、レッドチームがシステムに対して擬似的な侵入テストを行うか、サンドボックス環境で実際のマルウェアを起爆させるほかない。
このアプローチは極めて歩留まりが悪い。初期の侵入から深部への横展開に至る複雑な攻撃チェーンをラボで完全に再現するには莫大なコストがかかる。さらにラボ環境のログは本番環境特有のノイズを含まないため、いざ本番環境に検知ルールを適用すると、誤検知の山に埋もれてしまうというジレンマを抱えていた。攻撃の進化速度に対して、防御側のテストサイクルは物理的な実行環境に依存しているがゆえに遅延を余儀なくされていたのである。
TTPからテレメトリを錬成する。AIが描く「仮想の侵入者」
Microsoftの研究チームが設定した大胆な問いは、もしAIが攻撃者の意図を理解し、それを直接機械可読なテレメトリデータに翻訳できたらどうなるかというものだ。
彼らのアプローチは、攻撃者の行動原理を入力とし、構造化されたセキュリティログを出力するという極めてシンプルなパイプラインから始まる。例えば、間接的なコマンド実行という手法において、攻撃者が特定のWindowsシステムファイルを悪用し、環境変数でコマンドを難読化した上でインタプリタに渡す、という具体的なシナリオを想定する。
AIはマルウェアのコードを書くわけではない。このシナリオが実際の環境で実行された場合に記録されるはずの実行ファイル名、親プロセスの名前、複雑なコマンドライン引数を、意味論的な整合性を保ちながらテキストデータとして直接生成する。生成されたログはそのままSIEMに流し込むことができ、既存の検知エンジンを正確に作動させることが可能になる。
エージェントの協調と強化学習。3つの生成アーキテクチャの進化
この研究の最大の技術的ハイライトは、ログ生成の精度を高めるために検証された3つの段階的なAIアーキテクチャにある。単一の言語モデルにプロンプトを投げるだけの単純な手法から、複数のエージェントが自律的に議論し合うシステムへと進化を遂げている。
初期のアプローチであるプロンプトベースの生成では、熟練のセキュリティ専門家が設計した複雑なプロンプトを単一の言語モデルに入力する。システムは複数のターンに分けてログを生成し、独立した別のAIがその現実味や一貫性を評価する。この方法は比較的単純な攻撃シナリオには有効であったが、マルチステージにわたる複雑な攻撃チェーンにおいては、プロセスの親子関係に矛盾が生じる限界があった。
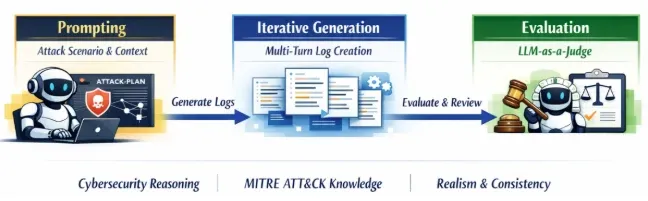
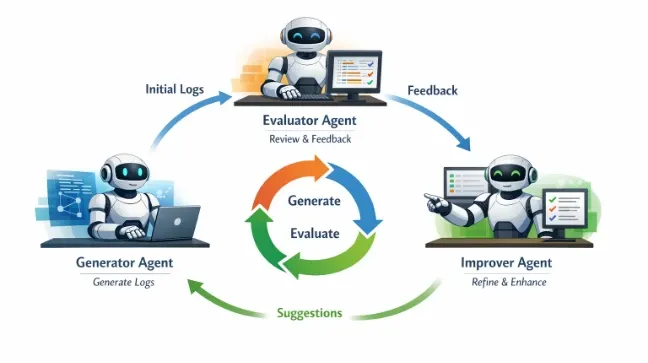
この複雑な依存関係を解決するために導入されたのが、エージェントワークフローベースの生成である。システムの中核を担うのは、3つの特化型AIエージェントによる自律的な反復サイクルだ。まず生成役が入力された攻撃シナリオに基づいて初期のログセットを作成する。次に評価役がこれを精査し、親プロセスが存在する前に子プロセスが起動しているといった論理的欠陥や構文エラーを構造化されたフィードバックとして提示する。そして最後に改善役がその指摘を受けてログの矛盾を修正し、より本物に近い形へと洗練させていく。この工程を繰り返すことで、プロセスパスの正確性やコマンドの難読化手法など、熟練の脅威ハンターが見ても不自然さのない高精細なログが完成する。
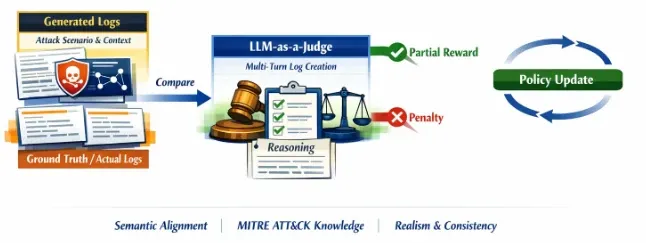
さらに研究チームは、検証可能報酬を用いた強化学習のメカニズムを導入した。エージェントベースの手法は意味論的には正しいログを出力するが、サービス名や固有のファイルパスといった実際のシステムログとの完全な一致という点ではわずかなズレが残る。そこで、評価用の言語モデルが生成データを実際の正解データと比較し、単なる正誤ではなく意味的な合致度合いに応じた部分的な報酬を与える仕組みを構築した。完全な一致でなければペナルティを課すことで、より文脈を捉えた柔軟なポリシー更新を可能にしている。
ベンチマークが示す圧倒的精度。推論モデルがもたらす飛躍
研究チームは、このシステムの汎用性を証明するため、特定目標を持った攻撃シミュレーション、マルチプラットフォームのオープンソースデータ、そして複雑なノイズを含むマルチステージ攻撃環境という3つの異なるデータセットを用いて評価を行った。
評価の主要指標は再現率(Recall)、すなわち特定の攻撃シナリオにおいて期待される関連ログをどれだけ正確に生成できたかである。
| 評価アプローチ | 適用モデル | 主な特徴と結果の概要 | 実務への影響 (So What?) |
|---|---|---|---|
| 従来の手法 (Lab Simulation) | 人間と物理環境 | 精度は高いが、環境構築に膨大な工数がかかる。 | 検知ルールのデプロイが遅れ、未知の脅威への対応が後手に回る。 |
| プロンプトベース | 一般的な推論モデル | 単発攻撃には有効だが、再現率のばらつきが大きい。 | 大規模な自動化には不向きであり、手動での確認作業が残る。 |
| エージェント協調 | 推論特化型モデル | プロセス親子関係を維持。全データセットで劇的な精度向上を記録。 | 物理ラボを完全にバイパスし、数分で高品質なテストデータを無数に生成可能。 |
高度な推論能力を持つモデルを中程度の推論エフォート設定でエージェントワークフローに組み込んだ場合、生成されるテレメトリは驚異的なリアリズムを獲得した。単に実行ファイル名を出力するだけでなく、それが呼び出されるフルパスや、環境変数に依存した親プロセスとの論理的整合性を自ら推論して組み上げるのである。
市場の覇権を揺るがす波と、両刃の剣を制御するガードレール
この技術的ブレイクスルーは、サイバーセキュリティ業界の構造に決定的なパラダイムシフトをもたらす。これまでCrowdStrikeやPalo Alto Networksなどの業界の巨人は、世界中から収集される本物のテレメトリデータ量を競い合ってきた。膨大なデータを保有するベンダーほど優秀な検知モデルを構築できるという優位性の法則が存在していたからだ。
しかし、合成データによって高品質な攻撃テレメトリを無限かつオンデマンドに生成できるようになれば、この前提が覆る。セキュリティチームは、歴史上まだ発生していない未知の攻撃ルートをAIに指示し、それに対する防御網を本番環境に近いノイズの中で事前にテストすることが可能になる。顧客データという機密情報を外部に持ち出すことなくプライバシーを保護したまま、世界中の運用チームで検証データを共有する道が開かれるのだ。
これはエコシステム全体に多大な波及効果をもたらす。Microsoftが自社のDefenderプラットフォームにこの技術を統合することで検知と対応の俊敏性が引き上げられることはもちろん、今後は「Detection-as-a-Service(サービスとしての検知環境構築)」といった新たなビジネスモデルの台頭が予想される。小規模な組織であっても、AIの力を借りて自律的なテストパイプラインを構築し、最新の脅威に対する防衛力を常にアップデートできる「セキュリティの民主化」が数年以内に現実のものとなるだろう。
一方で未解決のリスクも存在する。攻撃テレメトリを完璧に模倣できるAIは、見方を変えれば防御網をすり抜けるための最適な攻撃コマンドを自動生成するツールにもなり得る。強化学習を完全に機能させるには依然として大量の正解データが必要であり、データの品質が落ちればモデルは非現実的なアーティファクトを生成してしまう。
研究チームはこの技術の悪用を防ぐため、厳格なガードレールの必要性を説いている。モデルへのアクセスはスコープを限定したエンジニアリング環境に留め、生成された合成攻撃は通常トラフィックと明確に区別するためのラベル付けが不可欠である。この技術は攻撃者に自動化された侵入プレイブックを手渡すためのものではなく、防御者が予測される未来の攻撃に対する耐性を安全に確認するためのものである。
果てしないログの砂漠の中で、エンジニアたちはもはや泥にまみれながらマルウェアを走らせる必要はない。AIが紡ぎ出す極めてリアルな幻影とのスパーリングを通じて、サイバー防衛の最前線は物理的限界を超えた新たな次元へと突入していく。


