
Appleが自社AI「Apple Intelligence」の性能向上のため、ユーザープライバシーを保護しながらユーザーデータを活用する新たなトレーニング手法を発表した。この技術は「差分プライバシー(Differential Privacy)」と「合成データ(Synthetic Data)」を組み合わせ、ユーザーデータをデバイス上で処理し、個人を特定できない形で集計・分析する物だという。このアプローチは、iOS 18.5ベータ版以降で段階的に導入される見込みだ。。
プライバシー保護を核としたAIトレーニングの新機軸
Appleは、長年にわたりプライバシーを基本的人権と位置づけ、製品開発の根幹に据えてきた。そのため、Appleはこれまで、Apple Intelligenceのトレーニングに合成データのみを使用してきた。しかし、Bloombergの報道によれば、この方法には限界があり、特に要約機能やライティングツールなど、長文や全体のメールメッセージを扱う機能においては十分な精度が得られないという課題があったようだ。
この問題に対処するため、Appleは新たなアプローチを取り入れることにしたようだ。新手法では、Apple Intelligenceのトレーニングに実際のユーザーデータの傾向を反映させながらも、個人のプライバシーを侵害しない仕組みとなっており、AIの性能向上に必要な「利用傾向」を把握することが可能になっている。
このシステムの核心は、ユーザーが任意で参加する「デバイス解析(Device Analytics)」プログラムを通じて得られる情報を、個人が特定されない形で活用する点にある。具体的には、「差分プライバシー」という技術が用いられる。これは、収集するデータに意図的に「ノイズ」と呼ばれるランダムな情報を加えることで、個々のデータポイントが特定のユーザーに紐づけられることを統計的に不可能にする手法だ。Appleは2016年のiOS 10からこの技術を採用しており、絵文字の使用頻度分析や辞書機能の改善などに活用してきた実績がある。
さらに重要なのは、この分析プロセスがユーザーのiPhoneやMacといったデバイス上で完結する点である。ユーザーの生データがデバイス外部のAppleサーバーに送信されることはない。Appleが受け取るのは、多数のユーザーから集められ、ノイズが付加された統計的な情報のみであり、個人のプライバシーは厳重に保護される。
ジェン文字から始まる差分プライバシーの応用
Apple Intelligenceにおける差分プライバシーの具体的な応用例として、まず「ジェン文字」機能が挙げられる。ユーザーがジェン文字を作成する際にどのようなプロンプト(指示)を入力しているか、その人気の傾向を把握するためにこの技術が活用される。
このプロセスは以下のように行われる。
- フラグメント(断片)の特定: Appleは、「カウボーイハットをかぶった恐竜」のような、一般的と思われるプロンプトの断片を想定する。
- デバイスへの問い合わせ: デバイス解析に参加しているデバイスに対し、特定の断片が最近使用されたかをランダムに問い合わせる。
- ノイズ付き応答: デバイスは匿名で応答するが、その際、真の応答(使用した/していない)に加えて、ランダムに選択された別の断片に関する応答や「一致なし」という応答を返すことがある(これがノイズ)。
- 集計と分析: Appleは多数のデバイスからのノイズ付き応答を集計する。特定の断片が「人気がある」と判断されるためには、数百人規模のユーザーが実際にその断片を使用している必要があるようにノイズレベルが調整されている。
この仕組みにより、Appleは以下を実現する。
- 人気傾向の把握: 広く使われているプロンプトのパターンを把握し、モデル改善に役立てる。
- 個別データの秘匿: ユニークな、あるいは稀なプロンプトがAppleに知られることはない。
- 匿名性の確保: どのデバイスがどの応答をしたかは紐づけられず、IPアドレスやApple IDとも関連付けられない。
この手法はジェン文字で既に利用されており、今後、Image Playground、Image Wand、Memories Creation、作文ツールといった他のApple Intelligence機能やVisual Intelligenceにも順次展開される予定だ。
テキスト生成向上のための「合成データ」活用
メールの要約や文章作成支援など、より長い文章を扱う機能においては、ジェン文字のような短いプロンプト断片の分析手法は有効ではない。そこでAppleは、ユーザーの実際のメール内容などを収集することなく、利用傾向を反映した「合成データ」を作成・活用する新たな手法を開発した。
このプロセスは、近年の研究成果を応用したもので、以下のようなステップで進められる。
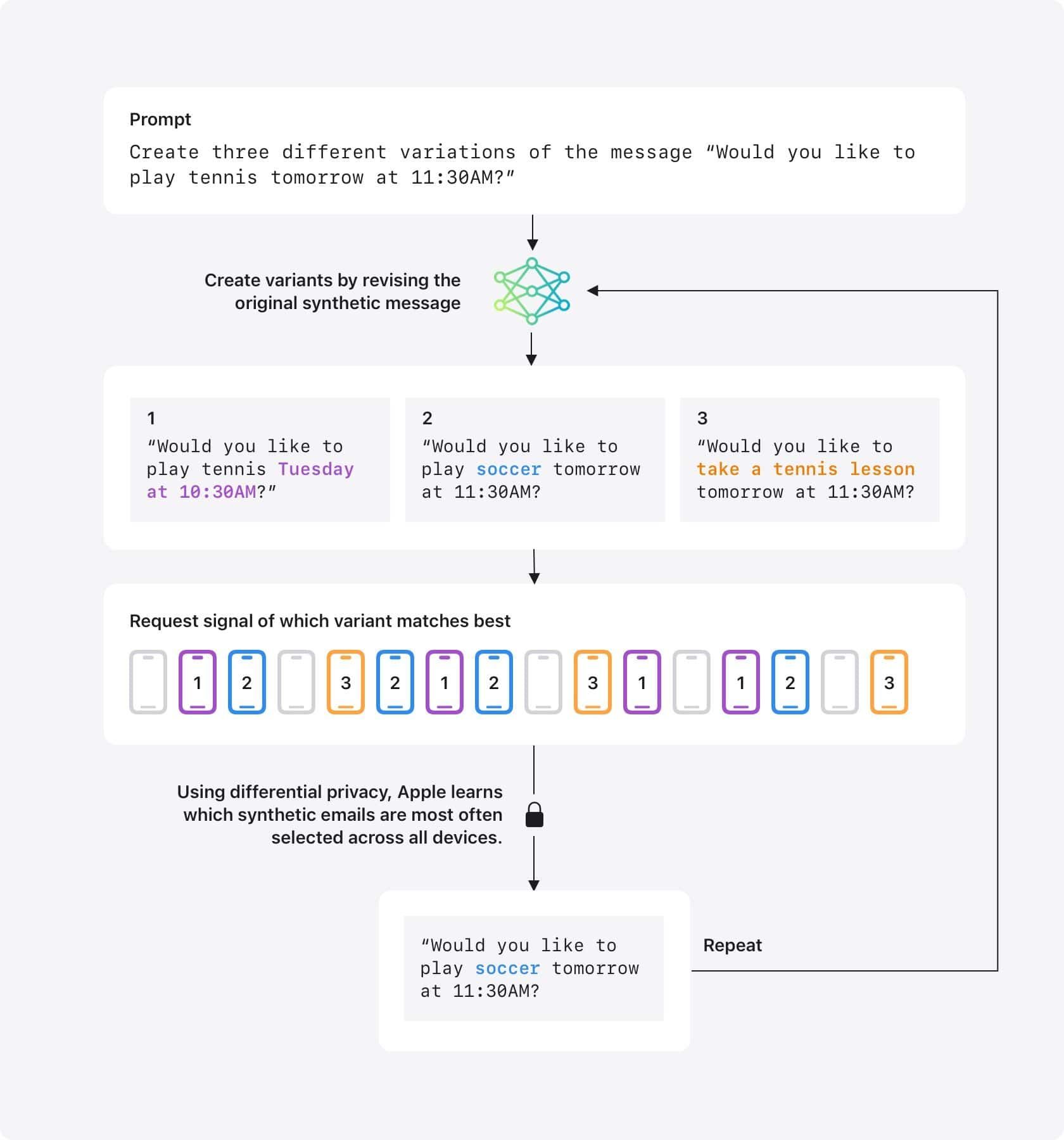
- 合成データの生成: Appleはまず、様々なトピックに関する多数の合成メッセージ(例:「明日11時半にテニスをしませんか?」)を、実際のユーザーデータとは無関係に大量に生成する。これはLLM(大規模言語モデル)などを用いて行われる。
- 埋め込み表現の作成: 生成された各合成メッセージについて、言語、トピック、長さといった主要な特徴を捉えた「埋め込み(Embedding)」と呼ばれる数値表現を作成する。
- デバイスへの送信: これらの合成メッセージの埋め込み表現を、デバイス解析に参加している一部のユーザーデバイスに送信する。
- デバイス上での比較: デバイスは、最近のユーザー自身のメールから少数のサンプルを(デバイス上で)選択し、その埋め込み表現を計算する。そして、Appleから送られてきた合成メッセージの埋め込みの中から、自身のメールサンプルの埋め込みに最も近いものを(デバイス上で)特定する。
- 差分プライバシーによる信号送信: デバイスは、最も近いと判断された「合成メッセージの埋め込み」がどれであったかを示す信号を、差分プライバシーの技術(ノイズ付加)を用いてAppleに送信する。ここでも、個々のデバイスの選択結果がAppleに知られることはない。
- 集計と合成データの改良: Appleは、全デバイスから送られてきた信号を集計し、どの合成埋め込みが最も頻繁に選択されたかを把握する。この情報に基づき、より現実の利用傾向に近い合成データセットを構築・改良していく(例:「テニス」が人気なら、「サッカー」など他のスポーツに置き換えた合成メッセージを追加生成する)。
この手法により、Appleはユーザーのメール内容を決してデバイス外に出すことなく、また読むこともなく、メール要約などの機能改善に役立つ「代表的なトピックや文体」を反映した合成データを作成できる。プライバシー保護の仕組み(オプトイン、デバイス上処理、差分プライバシーによる匿名化)はジェン文字の場合と同様に適用される。
この合成データを用いたテキスト生成機能の改善は、まずベータ版ソフトウェアでメール要約機能に対して導入され、今後順次拡大される見込みだ。
背景:プライバシーとAI進化の両立という課題
Appleが今回発表した手法は、AIの性能向上とユーザープライバシー保護という、しばしばトレードオフになりがちな課題に対する同社なりの回答と言える。Bloombergなどの報道によれば、完全に合成データのみでAIモデルを学習させることには限界があり、特に要約や文章作成ツールのような、よりニュアンスが求められる機能においては、実際の利用傾向を反映させることが性能向上に不可欠となる。
今回のこのオンデバイスでのデータ比較・分析手法が、過去にAppleが計画し、後に撤回したCSAM(児童性的虐待コンテンツ)検出システムと類似しており、それを想起させることも指摘されている。CSAM検出システムは、ユーザーのiCloud写真をデバイス上でハッシュ化し、既知のCSAMハッシュデータベースと照合するものだった。
しかし、両者は目的も技術的基盤も大きく異なる。CSAM検出は特定の(違法な)コンテンツを発見する可能性があったのに対し、今回のAIトレーニングシステムは、差分プライバシーのノイズ導入により、Appleが個々のユーザーについて何かを学習することを積極的に防ぐように設計されている。また、CSAM検出計画には差分プライバシーの核となる「ノイズ導入による匿名化」は含まれていなかった。類似点(ユーザーデータをデバイス上で何らかの比較可能な形式に変換する点)はあるものの、混同すべきではない。
Appleは、プライバシーに関する懸念からCSAM検出システムの導入を断念したが、今回のAIトレーニング手法は、より論争を呼びにくい形で、AI進化とプライバシー保護の両立を目指すものと考えられる。
AIトレーニングへのデータ提供を停止する方法
この新しいAIトレーニング手法は、デバイス解析への参加に同意しているユーザーのみが対象となる、オプトイン方式である。プライバシーが保護されるとはいえ、自身のデータが(間接的にであれ)AIトレーニングに利用されることを望まないユーザーは、設定を変更することで参加を停止できる。
この機能はiOS 18.5およびmacOS 15.5の将来のベータ版でテストが開始され、正式導入される予定であるため、現時点ですぐに設定が必要なわけではないが、確認・変更方法は以下の通りである。
- 「設定」アプリを開く。
- 「プライバシーとセキュリティ」を選択する。
- 「解析と改善」を選択する。
- 「iPhoneとWatch解析を共有」(またはデバイスに応じた同様の項目)のトグルスイッチをオフにする。
これにより、差分プライバシーを用いたApple Intelligenceのトレーニングへのデータ提供を含む、デバイス解析データの共有が停止される。
Appleは、長年の差分プライバシー技術の経験と、合成データ生成のような新たな技術を組み合わせることで、ユーザープライバシーを最優先にしながらApple Intelligenceを進化させようとしている。この取り組みは、AI時代におけるプライバシー保護のあり方を示す、重要な一歩となる可能性がある。
Sources
- Apple Machine Learning Research: Understanding Aggregate Trends for Apple Intelligence Using Differential Privacy
- Bloomberg: Apple to Analyze User Data on Devices to Bolster AI Technology


