
人類が創造した新たな知能を、我々はどのように測定すべきなのだろうか。かつてチェスや囲碁の世界チャンピオンを打ち破ったとき、AIの能力は「勝敗」という極めて明確な指標で測ることができた。しかし、汎用的な言語能力と推論能力を獲得した現代の大規模言語モデルにおいて、知性の測定は泥沼の様相を呈している。知能の指標として用意されたテスト問題は、解答があらかじめインターネット上に公開されていれば、単なる記憶力ゲームに成り下がる。2026年現在、人工知能の開発最前線で繰り広げられているのは、純粋な推論能力の追求と、公開されたテストで高得点を取るための過剰な最適化という、二つの顔を持つ複雑な競争である。
特定の領域で突出した結果を出すモデルが次々と登場する中、中国から発表されたオープンウェイトモデル「DeepSeek V4 Pro」は、業界に強烈な衝撃を与えた。開発元の自己申告によれば、その能力はAnthropicのOpus 4.6やOpenAIのGPT-5.4といった米国の最新鋭モデルに匹敵するという。もしこれが事実であれば、米国のテクノロジー企業が天文学的な資金と計算資源を投じて長年築き上げてきた優位性は、根底から崩れ去ることになる。
この宣言の真偽を確かめるべく、米国国立標準技術研究所(NIST)の傘下にあるAI標準・イノベーションセンター(CAISI)がメスを入れた。彼らが採用した手法は、AIが事前に学習できない「完全非公開のテスト」を用意し、過剰適合のメッキを剥がして真の推論能力を丸裸にすることであった。2026年4月に実施されたこの評価レポートは、AIの能力評価におけるごまかしを排除し、米中間の技術格差の現在地を冷酷なまでに描き出している。
カンニング不能な試験場。非公開ベンチマークが暴く真の実力
巨大なニューラルネットワークが持つ能力を評価する際、開発者は一般に公開されている標準的なベンチマークテストを使用する。しかし現在、モデルの事前学習データにこれらのテスト問題そのもの、あるいは類似の解説が含まれてしまう「データ汚染」が常態化している。AIは推論して答えを導き出しているのか、それとも巨大なデータベースの中から正解のパターンをただ引き出しているだけなのか、開発者自身でさえ判別がつかなくなっているのが実態である。
CAISIはこの汚染問題に対処するため、外部に一切漏れていない独自の評価セットを構築した。アリゾナ州立大学が開発した難解なサイバーセキュリティ課題を基にした「CTF-Archive-Diamond」や、あるプログラミング言語のコマンドラインツールを別の言語に移植する能力を測る未公開評価「PortBench」などである。さらに、ARC Prize Foundationから提供された半非公開の抽象推論データセット「ARC-AGI-2 semi-private」を組み合わせ、AIにとって全く未知の領域を用意した。
評価の結果、DeepSeek V4 Proの自己申告スコアは幻影であったことが示された。DeepSeek自身が選定した公開ベンチマークでは米国トップモデルと肩を並べていたものの、CAISIが用意した非公開の環境下ではスコアが大幅に下落したのである。
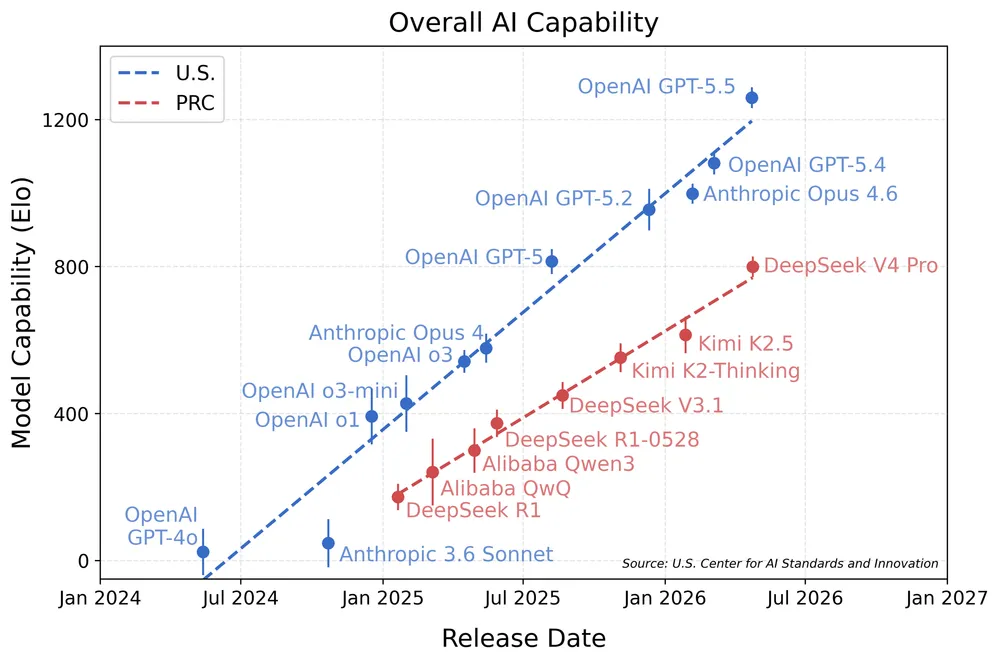
CAISIは、AIモデルの相対的な能力を精密に数値化するために「項目応答理論(IRT:Item Response Theory)」から着想を得た統計手法を導入した。これは、チェスの強さを測るイロレーティング(Elo)のように、モデルの潜在的な能力値と、各タスクの難易度を同時に推定する数学的アプローチである。直感的に言えば、数百人の学生(AIモデル)に難易度の異なる大量のテスト問題を解かせ、正答率の単純な平均ではなく、「誰がどのくらい難しい問題を解けたか」を統計的に解析する仕組みだ。
この算出方法により、OpenAIの最高峰モデルGPT-5.5が「1260±28」という圧倒的なEloスコアを記録したのに対し、DeepSeek V4 Proは「800±28」にとどまった。この約460ポイントのスコア差は、CAISIの分析によればおよそ「8ヶ月」の開発期間の遅れに相当する。中国の最先端は、米国の8ヶ月前の足跡をなぞっている状態であることが判明したのだ。
抽象化とハッキングの壁。局所的特化と汎用性の断絶
モデルの能力をさらにミクロな視点で観察すると、米中のAIがそれぞれどのような学習戦略をとってきたのかが如実に表れている。DeepSeek V4 Proはすべての領域で劣っているわけではない。領域によっては、米国の最先端モデルの喉元に刃を突きつけている。
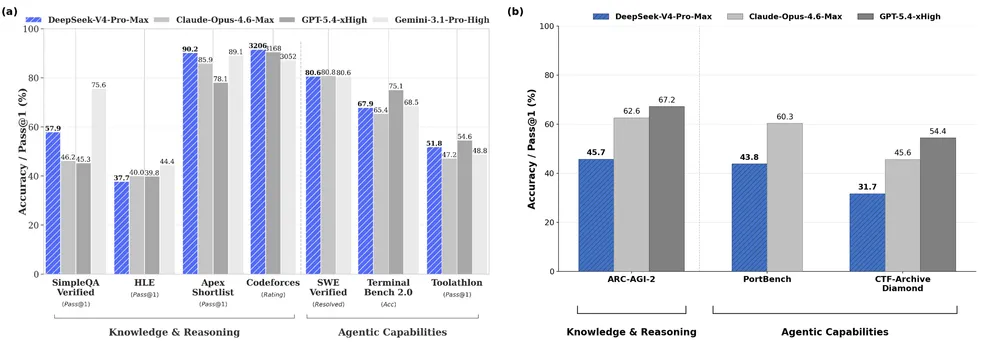
以下の表は、各モデルが特定のベンチマークで記録した正答率の比較である。
| 領域 | ベンチマーク | OpenAI GPT-5.5 (最高性能) | OpenAI GPT-5.4 mini | Anthropic Opus 4.6 | DeepSeek V4 Pro |
|---|---|---|---|---|---|
| サイバー | CTF-Archive-Diamond | 71% | 32% | 46% | 32% |
| ソフトウェア工学 | SWE-Bench Verified | 81% | 73% | 79% | 74% |
| ソフトウェア工学 | PortBench (非公開) | 78% | 41% | 60% | 44% |
| 自然科学 | GPQA-Diamond | 96% | 87% | 91% | 90% |
| 抽象的推論 | ARC-AGI-2 semi-private | 79% | 未計測 | 63% | 46% |
| 数学 | PUMaC 2024 | 96% | 93% | 95% | 96% |
| 数学 | SMT 2025 | 99% | 92% | 94% | 96% |
注目すべきは数学領域におけるDeepSeek V4 Proの異常なほどの強さである。プリンストン大学の数学競技会をベースにした「PUMaC 2024」において、DeepSeekは96%という驚異的な正答率を叩き出し、GPT-5.5と完全に同点となっている。論理の規則が厳密に定まっており、記号操作のパターンが学習しやすい数学的推論において、中国のモデルはすでに最高到達点に達している。
その反面、未知の状況における直感的なパターンの把握や、ルールのない環境での問題解決能力において、深刻な断絶が確認できる。AIの「真の知能」を測る試金石とされる「ARC-AGI-2 semi-private」において、GPT-5.5が79%を記録したのに対し、DeepSeek V4 Proは46%と半分近いスコアに沈んだ。さらに、システムを破壊し脆弱性を突く実践的なハッキング能力を問う「CTF-Archive-Diamond」でも、GPT-5.5の71%に対して32%という結果に終わっている。
なぜこのような極端な能力の偏りが生まれたのか。その根本原因は、それぞれのタスクが要求する「強化学習(RL)の難易度差」にある。数学は形式論理であり、最終的な答えが正解か不正解かが明確である。そのため、報酬系(Reward Model)を設定しやすく、AI自身に延々と自己対戦を行わせて能力を研ぎ澄ます「アルファゴ的アプローチ」が機能しやすい。中国の開発環境において、理数系の質の高いデータセットが高密度にキュレーションされていることも、この特化を後押ししている。
一方で、未知のパズルを解く抽象的推論や、ノイズに満ちた現実のシステムを相手にするハッキング課題には、明確なルールが存在しない。システムからのフィードバックを得ながら、その場で自律的に計画を立て、試行錯誤を通じて新しいルールを推論する「エージェント的な推論能力」が求められる。このような自由度の高い環境での探索と学習には、圧倒的な計算資源のスケールと、多様で複雑なシミュレーション環境(スキャフォールディング)の長期的な蓄積が不可欠である。ここに、シリコンバレーのトップラボが持つ巨大な資本力と技術的蓄積の真価が発揮されており、それが局所的な特化と汎用的な知能の間に明確な断絶を生み出している。
知能のコスト・デフレ。パラダイムを揺るがす経済性の逆襲
能力の絶対値において米国が8ヶ月のリードを保っているという事実は、一見すると米国の盤石な勝利に思える。しかし、産業界の現実的なマクロ文脈にこの結果を接続したとき、全く異なる風景が広がってくる。
AIを社会基盤として実装していく上で、知能の高さと同等に重要な指標が「推論コスト」である。現在、シリコンバレーの巨大企業は天文学的な資金を投じて巨大なデータセンターを建設し、より賢いモデルの訓練に血道を上げている。その結果、最上位モデルの利用料金は高止まりし、ビジネスの現場では「AIによる生産性向上」と「APIの利用コスト」の採算が合わないという問題が表面化しつつある。
ここでDeepSeek V4 Proが持つ真の脅威が牙を剥く。CAISIの評価において、DeepSeek V4 Pro(Elo 800)と同等の能力を持つ米国のモデルとして比較対象に選ばれたのは、軽量版であるGPT-5.4 mini(Elo 749)であった。推論コストを比較すると、DeepSeek V4 ProはCAISIが実施した7つのベンチマークのうち5つで、GPT-5.4 miniよりも安価にタスクを完了している。モデルが回答を生成する際のトークン単価を見ても、入力キャッシュを利用した際のDeepSeek V4 Proのコストは、100万トークンあたりわずか0.0145ドルであり、GPT-5.4 miniの5分の1以下に抑えられている。
現実のソフトウェア開発や事務作業の現場で発生するタスクの大部分は、超高度なハッキング能力や複雑な抽象推論を必要としない。日常的なコードの記述、データの整形、文章の要約といった大半の退屈な作業を処理するには、GPT-5.5のような最高峰の知能はオーバースペックであり、コストの無駄遣いとなる。
この経済構造の歪みを突くように、新たなビジネスモデルが台頭している。次世代のコードエディターとして急速にシェアを拡大し、SpaceXによる巨額の買収が噂される「Cursor」は、高価な米国製モデルに依存するのをやめ、Kimi k2.5をはじめとする中国のオープンウェイトモデルをベースに独自のファインチューニングを施すことで、爆発的なコストダウンとレスポンスの高速化を実現した。
OpenAIのCEOであるSam Altman氏も、より賢いモデルを追求するべきか、より安価で速いモデルを普及させるべきかというジレンマに直面していることを示唆している。一部の限られた天才的なタスクを米国のクローズドモデルが独占し、世の中の大部分の汎用タスクを中国の低コストなオープンモデルが根こそぎ奪っていく。そのような知能の分業体制が、すでに水面下で進行している。
評価の罠と次なる戦場。残された死角とコミュニティの反発
CAISIの報告書は、AI業界に冷水を浴びせる精緻な分析であった。しかし、この評価方法自体が完璧であるとは言い切れない。オープンソースコミュニティや専門家の間では、この結果に対する懐疑的な見方も存在している。
第一の死角は、ベンチマークの選定に伴う構造的なバイアスである。NISTという米国の政府機関が内部で開発した非公開テスト(CTF-Archive-DiamondやPortBench)において、米国のモデルが高得点を出すのは、開発文化やプロンプトの構成方式が米国企業の手法と暗黙のうちに同調しているからではないか、という指摘がある。異なる文化圏で異なるデータセットを食べて育ったAIにとって、出題の文脈自体が不利に働いている可能性は否定できない。
第二に、エージェント型評価の不安定さがある。AIに自律的な思考プロセスを与え、長時間にわたって試行錯誤させるタスクでは、モデルそのものの基礎能力だけでなく、AIを動かす枠組みやシステムプロンプトの設計が結果を大きく左右する。CAISIのテスト環境が、DeepSeekの持つアーキテクチャの真価を引き出すのに最適な設定であったかどうかは、さらなる検証を待つ必要がある。
我々は今、知能の価値が根本から問い直される特異点に立っている。米国が莫大な計算資源を注ぎ込んで神の如き知能の天井を押し上げ続ける一方で、中国は効率とコストを極限まで削ぎ落とし、社会の隅々に浸透する安価な知能のインフラを構築しつつある。
8ヶ月という遅れは、知能の絶対値における劣後を示している。しかし、経済的な実用性という戦場において、それが致命的な敗北を意味するわけではない。知性の軍拡競争は、テストの点数を競う段階から、いかにそれを安価に、そして広範に実社会へデプロイするかという、より冷徹なフェーズへと突入したのである。