
コンピューティングの歴史において、人間と機械のインターフェースは常にテキストから始まり、グラフィカル・ユーザー・インターフェース(GUI)へと進化し、現在その主戦場は「音声」へと移行している。しかし、音声合成(Text-to-Speech: TTS)技術は長らく、微細な感情表現や文脈に応じた抑揚の制御という壁に直面してきた。機械音声特有の平板な読み上げは解消されつつあるものの、人間の発声が内包する複雑な情報を完全に再現するには至っていなかった。
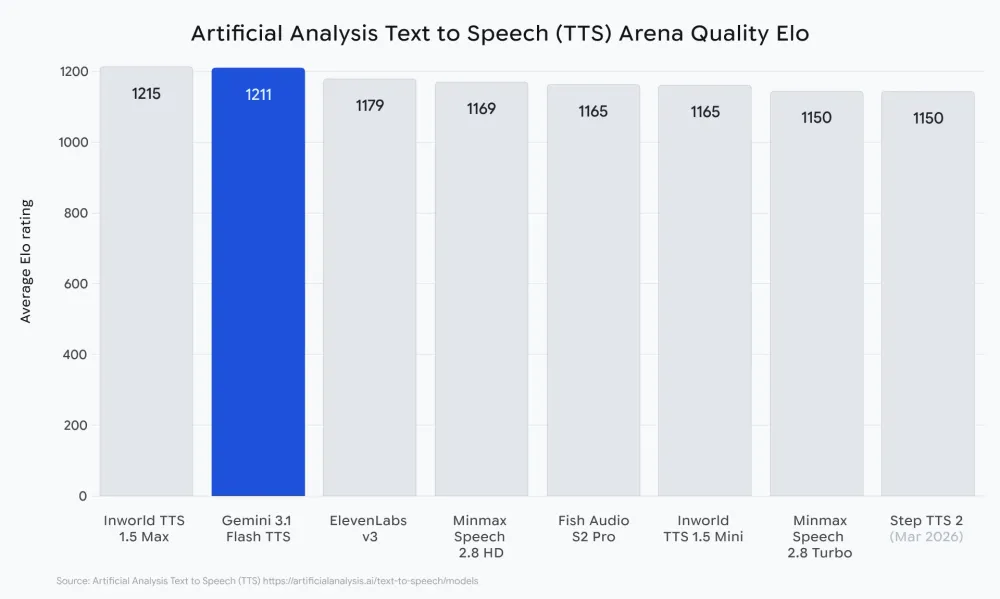
この技術的停滞を打破する決定的な一手として、Googleは「Gemini 3.1 Flash TTS」を展開した。これは音声合成エンジンの高音質化という枠を超え、音声を完全にプログラマブルなメディアへと変容させるプラットフォーム構造の提示に他ならない。第三者機関による評価基盤において、Gemini 3.1 Flash TTSはすでに顕著な成績を収めている。何千ものブラインドテストによる人間評価をベースとした「Artificial Analysis TTS Leaderboard」において、Eloスコア1,211を記録した。これは、業界を牽引してきたElevenlabs v3の全体的な品質を凌駕し、AIキャラクターに特化したInworld 1.5 Maxに肉薄する水準である。特筆すべきは、同モデルが「品質と価格のバランス」において極めて競争力の高い位置に配置されている点であり、高品質なAI音声の民主化フェーズが実用段階に入ったことを示している。
音声をプログラマブルにする「オーディオタグ」の革新性
これまで、テキストから音声を生成するプロセスはブラックボックス化されていた。開発者が入力したテキストに対して、AIが推論した抑揚が固定的に出力されるだけであり、特定の単語を強調したり、文脈に応じて話者の感情を切り替えたりすることは困難であった。
Gemini 3.1 Flash TTSが導入した「オーディオタグ(Audio Tags)」は、この制御不能性を解消する技術的ブレイクスルーだ。開発者は自然言語のコマンドをテキスト内に埋め込むことで、ボーカルスタイル、話すペース、トーン、そしてアクセントを粒度高く指定できるようになった。例えば、「enthusiastic(熱狂的)」「positive surprise(前向きな驚き)」「informative(情報提供)」といったメタデータを付与することで、出力される音声の質感を動的に変化させる。
さらに、この制御体系は「ディレクターズチェア」に座るような体験として設計されている。「シーン・ディレクション」機能を利用すれば、ポッドキャストの対話、オーディオブックのナレーター、言語学習の家庭教師、あるいはニュースキャスターといった特定の環境と世界観を定義することが可能である。これにより、複数回のターンの対話においても、AIキャラクターは設定されたペルソナを維持し、自然に反応し合う。特筆すべきは「インラインタグ」による話者レベルの粒度指定であり、一つの文章の途中でアクセントやトーンを切り替えるという高度な制御すら可能にしている。完成した設定はGemini APIのコードとしてエクスポートでき、他のプロジェクトやプラットフォームでも一貫して同一のペルソナを再現できる。これは、音声生成プロセスが一時的な「推論」から、完全に制御・反復可能な「資産」へと変化したことを意味する。
グローバル展開とエコシステムの覇権競争
Googleの音声戦略の射程は、単一言語での高品質化にとどまるものではない。Gemini 3.1 Flash TTSは初期段階から70以上の普遍的な言語をサポートし、同時に言語体系の内部に存在する多様な方言やアクセントの制御を実現している。英語圏の表現においては、アメリカ英語の「Valley(バレーガール風)」「Southern(南部訛り)」から、イギリス英語の「Brixton(ロンドンのブリクストン訛り)」「RP(容認発音)」、さらには歴史・映画的な「Transatlantic(大西洋横断アクセント)」といったニッチなオプションまでがAPI経由で即座に呼び出し可能となっている。これは、グローバル市場に向けて双方向のアプリケーション群を展開するエンタープライズ領域において、各国の文化的文脈に合わせたローカライゼーション作業のコストと時間を劇的に引き下げるブレイクスルーとなる。例えば、多国籍に展開するコールセンター業務や、ゲーム内のNPC(ノン・プレイヤー・キャラクター)の音声生成においては、現地の声優をアサインする時間的制約から解放され、同一のテキストベースから数十の地域に適合した音声音源をリアルタイムかつ並行して生成する運用が視野に入ってくる。
この技術的な優位性を背景とし、Googleはエコシステム全域へのトップダウンとボトムアップの市場浸透アプローチを同時に展開している。スタートアップや個人の開発者向けには「Gemini API」および「Google AI Studio」を通じたプレビュー提供を行い、既存のシステム基盤に組み込むエンタープライズの顧客群に対してはクラウド・インフラストラクチャの中核である「Vertex AI」上で展開する。さらに日々の資料作成を行う一般のビジネスユーザー向けには、動画生成・共有サービスである「Google Vids」に直接実装するという、全方位に向けたインターフェースを確立している。
次世代のインターフェース競争を決定づける価格戦略においても、プラットフォーマーとしての明確な意図が観察される。有料層の商用利用においては、テキストの入力が100万トークンあたり1.00ドル、音声の出力が100万トークンあたり20.00ドルという極めて攻撃的な設定が行われている。さらに非同期での処理を許容するバッチモードを利用すればこれらのコストはそれぞれ0.50ドル、10.00ドルにまで半減し、エンタープライズの大量バッチ処理を強力に後押しする。対照的に、Google AI Studioでは個人開発者に向けた無料枠が設けられており、そこで入力・出力されたデータは、オプトインの範囲内でGoogle内部のプロダクト改善と精度向上のためのフィードバックループへと還元される。一方で有料プランにおいては、エンタープライズの機密データを保護するためにこのデータ利用設定が完全にオプトアウトされる。この二段構えのクラウド構造は、大手企業へのコンプライアンス要件を厳格に満たすと同時に、全世界の無料ユーザーからの膨大な利用と試行錯誤のデータを、次世代モデルの継続的な改善燃料として吸い上げる巨大で不可逆的なエコサイクルを形成している。
信頼性とセキュリティ基盤の確立
生成AIを利用したクローン技術や音声合成の高品質化は、技術的な達成であると同時に、実社会に対して深刻なセキュリティ的リスクを引き起こす要因となっている。政治家のディープフェイク発言による選挙の混乱や、金融機関をターゲットにした音声認証の突破、あるいは一般市民を標的にしたオレオレ詐欺の高度化など、偽情報の拡散は社会インフラの全体的な信頼性を揺るがす直接的な脅威へと急速に発展している。
Googleはこの社会実装に伴うリスクの深刻化に対し、技術的なトレーサビリティをAIモデルの出力段階からデフォルトで組み込むアプローチを選択した。Gemini 3.1 Flash TTSのエンジンによって生成されたすべての音声データには、同社のAI識別技術である「SynthID」による電子透かし(ウォーターマーク)が不可避的に施されている。この透かし技術は、音の波形の中に人間の聴覚器官では知覚不可能な微細なノイズパターンとして埋め込まれており、MP3への圧縮やビットレートの変換といった不可逆なデータ加工を経た後でも、専用の検出アルゴリズムによって正確にAI生成物であるかどうかが判定される。これは、出力されたコンテンツが自律的に自身の来歴を証明する仕組みであり、サードパーティの検知ツールに頼ることなく、生成プラットフォーマー自身が出口の時点で透明性を担保する責任構造を確立するものである。
Googleによるこれらの一連の包括的な機能群は、既存の音声合成APIがテキストの単なる「読み上げツール」という限定的な役割から明確に脱却した事実を示している。テキストタグによって細部まで制御可能な喜怒哀楽の感情表現、グローバル市場に適合するアクセントの多様性、アグレッシブな価格設定、そしてSynthIDを用いたセキュリティの自己担保。これらが統合されたGemini 3.1 Flash TTSの登場により、顧客の感情に寄り添うカスタマー・サポートエージェント、プレイヤーの行動で台詞が変わる対話型のオープンワールドゲーム、自然な多言語での没入型オーディオブックなど、無数のデジタル領域において「音声というメディアを介した、人間と機械のインタラクション」のパラダイムが根本から書き換えられようとしている。
Sources

