
OpenAIから、新たな小型言語モデル群「GPT-5.4 mini」および「GPT-5.4 nano」がリリースされた。これらはすでにChatGPT、Codex、そしてAPI経由で利用可能となっている。前世代のGPT-5 miniと比較して、推論速度を2倍以上に高めつつ、上位モデルであるGPT-5.4に肉薄する性能を叩き出している。特筆すべきは、コーディング支援やエージェントベースのタスク、そしてコンピュータ操作(OSWorld-Verifiedなど)において大幅なスコア向上を見せている点である。
しかし、この性能向上は無料では手に入らない。API利用価格は前世代から最大4倍へと跳ね上がっており、AI開発における費用対効果のロジックは根本的な見直しを迫られている。
実効速度とコストの新たなトレードオフ:小規模モデルの役割再定義
長らくAI開発の世界では、パラメータ数の巨大化がそのままモデルの優位性に直結すると考えられてきた。しかし、GPT-5.4 miniとnanoの登場は、特定のユースケースにおいては「レイテンシの低さ」こそがユーザー体験の決定要因になるという明確な見解を示している。
OpenAIの発表によれば、GPT-5.4 miniは推論速度において前モデルの2倍以上を記録しつつ、コーディングベンチマークであるSWE-Bench Proにおいて54.4%の正答率を達成したとのことだ。これはフルスペックのGPT-5.4が記録した57.7%という数値に極めて近い。さらに、コンピュータの操作・理解能力を測るOSWorld-Verifiedにおいても、GPT-5.4の75.0%に肉薄する72.1%を記録し、旧世代のGPT-5 mini(42.0%)から劇的な進化を遂げている。
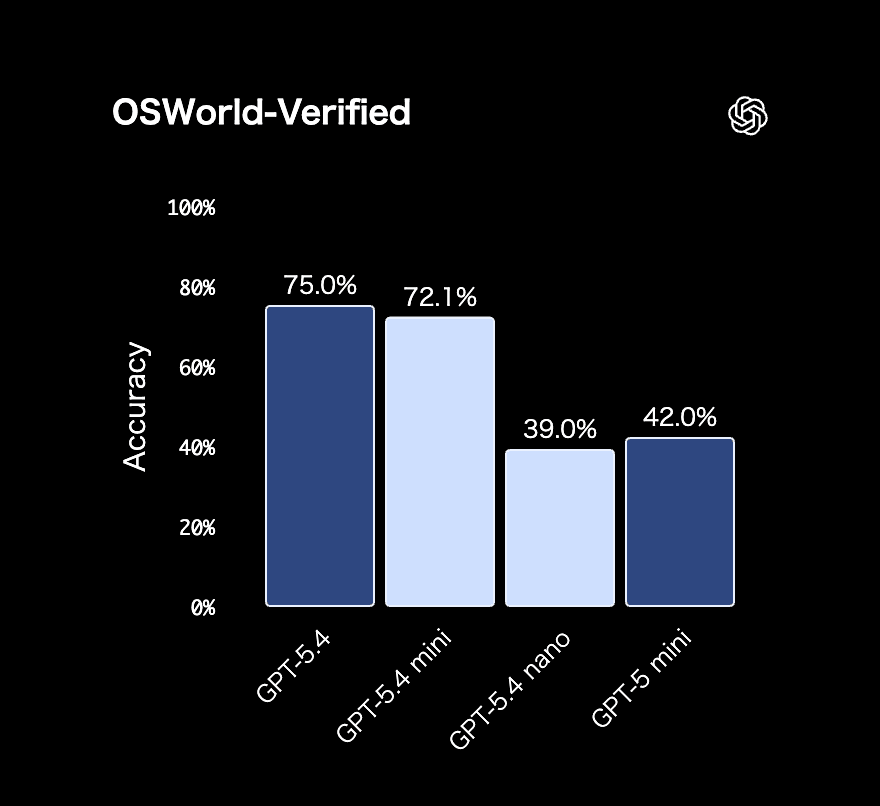
現代のAIモデルでは、コーディングアシスタントにおけるリアルタイムなコード補完機能や、システム内部で自律的に動作するサブエージェントなど、ユーザーの体感速度が製品価値に直結する領域において、「必要十分な性能を最短時間で返す」能力がこれまで以上に求められている。OpenAIは大規模モデルのような万能性を持たずとも、推論や関数呼び出しの精度を特化して高めることで、小規模モデルは単なる廉価版という位置づけを脱却し、レイテンシクリティカルなタスクにおける「最適解」へとその役割を昇華させているのだ。
マルチエージェント・アーキテクチャの本格稼働
今回のリリースにおいて最も注目すべき技術的コンセプトは、Codexの事例で明示された「サブエージェント」のアーキテクチャである。
このアプローチでは、複雑な処理全体を単一の巨大モデルに処理させる構造を非効率とみなし、明確な役割分担によってタスクを最適化する。GPT-5.4のような大規模で高コストなモデルが、全体計画の立案、タスクの調整、最終的な評価・判断といった司令塔の役割に専念する一方で、並列処理が可能な単一作業——巨大なコードベースの検索、ファイルの論理的な読み込み、あるいはサポートドキュメント全体の要約処理など——を、より軽量かつ高速なGPT-5.4 miniやnanoに一斉に委譲する。
Codexの環境下では、GPT-5.4 miniの利用分はフルサイズのGPT-5.4の約30%のクオータ消費で動作するよう設計されている。この分業モデルが浸透すれば、エンタープライズのAIシステムは「すべてを高度なモデルに任せる」という段階から、「計算コストと精度の要件に応じて複数のモデルを適材適所に稼働させる」精緻なハイブリッド構成へと進化していく。巨大モデルの持つ知的な判断力と、小規模モデルが提供するスケール時の速度および低コスト性が結びつくことで、次世代AIアプリケーションの処理能力は構造的に別次元へと進むことになる。
性能の代償:大幅な価格引き上げがもたらすビジネスへの波紋
技術的な進化が開発者にもたらす恩恵の影で、最大の懸念事項として浮上しているのが大幅なAPI利用コストのインフレである。
GPT-5.4 miniのAPI利用料は、100万入力トークンあたり0.75ドル、100万出力トークンあたり4.50ドルに設定されている。これは前世代のGPT-5 mini(入力0.25ドル、出力2.00ドル)と比較して、入力で3倍、出力で実に2.25倍もの価格上昇を突きつけている。さらに、最もコスト要件が厳しい領域を想定したはずのGPT-5.4 nano(入力0.20ドル、出力1.25ドル)であっても、前世代のGPT-5 nano(入力0.05ドル、出力0.40ドル)と比較すると、入力部において実に4倍もの急激な値上げとなっている。
OpenAIはこの強気な価格設定を、上位モデルに迫る性能の劇的な向上、ひいてはそれによって得られるプロセスの自動化の価値によって相殺できると見積もっている。実際、タスクの精度が大幅に高まったことで、開発者はこれまでフルスペックの高性能モデルを使用せざるを得なかった処理プロセスを、この新たなminiモデルに大きくダウンサイジングできる可能性がある。しかし、すでにGPT-5 miniなどに最適化してシステムを構築し、極端な薄利多売のビジネスモデルを採用しているSaaS系スタートアップや個人開発者にとって、この容赦のない価格改定は深刻な収益構造の破壊をもたらすトリガーとなる。
AIを組み込んだプロダクトを提供する企業は、性能の大幅な向上という恩恵をユーザー体験に還元しつつ、跳ね上がった原価を吸収するための価格転嫁を行うか、あるいは代替の推論基盤へと舵を切るかの判断を即座に迫られている。
オープンソース陣営の追従:Mistral Small 4の意図とハードウェア要件の死闘
OpenAIのこの動きと時を同じくして、フランスのMistral AIから新しいオープンソースモデル「Mistral Small 4」が発表された。これは、ハードウェアの稼働効率と推論コストの低減をかつてないレベルで意識したカウンター・リリースである。
Mistral Small 4は1,190億パラメータのMoE(Mixture of Experts)構造を採用しており、実際の推論時にはそのうちの4つのエキスパート(計60億パラメータ)のみをアクティブにして計算を実行する。特に注視すべきは、タスクの複雑さに応じてモデルが投下する計算リソースを動的に調整できる「reasoning_effort」という柔軟なパラメーターを実装している点である。Mistral AIの公式発表によれば、この機能を用いて論理的思考を最小化する遅延最適化設定を選択した場合、最大40%の処理時間短縮が可能になるという。
OpenAIの小規模モデル群が価格を大きく引き上げる中、NVIDIA HGX H100などでオンプレミス・独自運用が可能なMistral Small 4のようなハードウェア効率特化型のオープンソースモデルは、クラウドベンダーの価格支配を嫌悪するエンタープライズ市場において、インフラコストに対する強力な交渉材料としてその存在感を急速に高めていくことは想像に難くない。
AI開発における「適切なサイジング」の時代へ
今回のGPT-5.4 miniおよびnanoのリリースがもたらす影響は、APIラインナップの一斉更新という一過性の現象を遥かに凌駕する。「推論速度と運用コスト」というトレードオフの力学において、パラダイムシフトが明白に進行していることを業界全体に知らしめる出来事である。
開発者はもはや「どのベンダーのモデルが最も賢いか」という単一の指標でAIインフラを選択することはできない。解決すべきタスクの性質、システム全体で許容されるレイテンシ、そして何よりも厳格な損益分岐点の枠組みの中で、知能レベルの異なる複数のモデルをオーケストレーションする、高度で緻密なアーキテクチャ設計能力が求められているのである。
OpenAIによるAPI利用料の引き上げは、機能的な価値に対する絶対的な自信の証明であると同時に、実用期に入ったAI市場全体の「演算リソースの相場」を再定義する試みであるとも言える。このゲームルールの変更に適応できる企業は、高度なサブエージェントを縦横無尽に稼働させ、かつてないスピードで業務領域を自動化する対価として、莫大なクラウドインフラコストを払い続けることになる。AIモデルの運用最適化は、いまや現場の技術的課題を越え、企業の事業継続に直結する最重要の経営課題そのものへと成熟している。
Sources